OmniNWM: Omniscient Driving Navigation World Models
作者: Bohan Li, Zhuang Ma, Dalong Du, Baorui Peng, Zhujin Liang, Zhenqiang Liu, Chao Ma, Yueming Jin, Hao Zhao, Wenjun Zeng, Xin Jin
分类: cs.CV
发布日期: 2025-10-21 (更新: 2025-11-15)
备注: https://arlo0o.github.io/OmniNWM/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
OmniNWM:全知全景导航世界模型,赋能自动驾驶
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 自动驾驶 世界模型 全景视频生成 Plucker射线图 3D Occupancy 长时程预测 奖励函数
📋 核心要点
- 现有自动驾驶世界模型在状态表示、动作控制和奖励机制上存在局限,难以满足复杂场景需求。
- OmniNWM通过联合生成多模态全景视频、引入Plucker射线图控制和基于3D occupancy的奖励,实现更全面、精确和安全的自动驾驶。
- 实验表明,OmniNWM在视频生成质量、控制精度和长期稳定性方面均优于现有方法,并提供可靠的闭环评估。
📝 摘要(中文)
现有的自动驾驶世界模型通常在状态模态、视频序列长度、动作控制精度和奖励感知方面存在局限性。本文提出了OmniNWM,一个全知全景导航世界模型,它在一个统一的框架内解决了状态、动作和奖励三个核心维度的问题。在状态方面,OmniNWM联合生成RGB、语义、度量深度和3D occupancy的全景视频。灵活的强制策略实现了高质量的长时程自回归生成。在动作方面,引入了归一化的全景Plucker射线图表示,将输入轨迹编码为像素级信号,从而实现对全景视频生成的高度精确和泛化的控制。在奖励方面,不再使用外部的基于图像的模型来学习奖励函数,而是利用生成的3D occupancy直接定义基于规则的密集奖励,以确保驾驶合规性和安全性。大量实验表明,OmniNWM在视频生成、控制精度和长时程稳定性方面达到了最先进的性能,同时通过基于occupancy的奖励提供了一个可靠的闭环评估框架。
🔬 方法详解
问题定义:现有自动驾驶世界模型通常只能处理有限的状态模态(例如仅RGB图像),难以生成长时程视频,动作控制精度不足,并且缺乏有效的奖励机制来指导模型的学习和评估。这些局限性阻碍了自动驾驶系统在复杂环境中的应用。
核心思路:OmniNWM的核心思路是构建一个全知全景导航世界模型,该模型能够同时处理多种状态模态(RGB、语义、深度、3D occupancy),实现高精度的动作控制,并利用3D occupancy信息定义可靠的奖励函数。通过这种方式,模型可以更全面地理解环境,更精确地预测未来状态,并学习到更安全的驾驶策略。
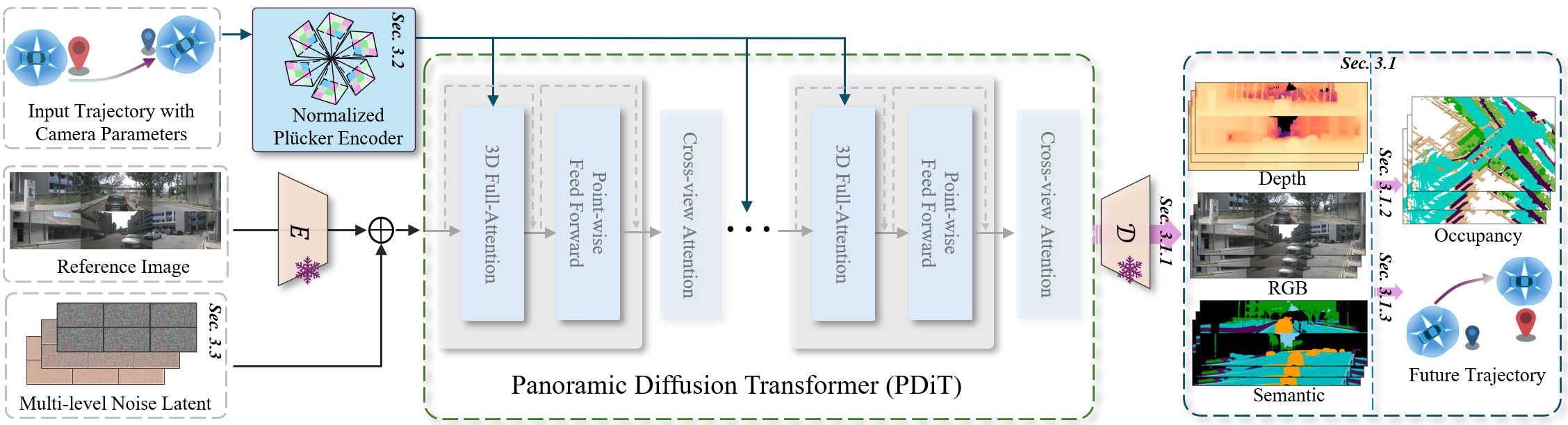
技术框架:OmniNWM的整体框架包括以下几个主要模块:1) 全景视频生成器:用于联合生成RGB、语义、深度和3D occupancy的全景视频。2) Plucker射线图编码器:将输入轨迹编码为像素级信号,用于控制全景视频的生成。3) 奖励函数定义模块:利用生成的3D occupancy信息,定义基于规则的密集奖励。整个流程是,首先输入轨迹信息,通过Plucker射线图编码器将其转化为控制信号,然后全景视频生成器根据控制信号生成未来的全景视频,最后利用生成的3D occupancy信息计算奖励。
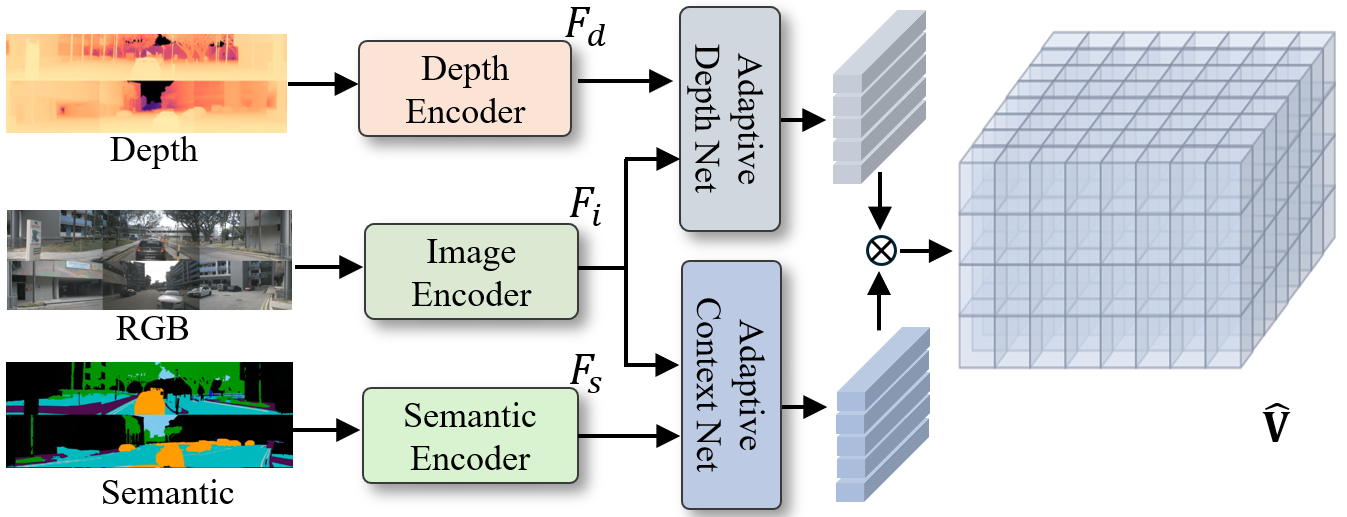
关键创新:OmniNWM的关键创新点在于:1) 联合生成多模态全景视频,提供更全面的环境信息。2) 引入归一化的全景Plucker射线图表示,实现高精度的动作控制。3) 利用生成的3D occupancy信息,直接定义基于规则的密集奖励,避免了对外部图像模型的依赖。与现有方法相比,OmniNWM能够更全面地理解环境,更精确地预测未来状态,并学习到更安全的驾驶策略。
关键设计:在全景视频生成器中,使用了灵活的forcing策略,以提高长时程视频生成的质量。Plucker射线图编码器将输入轨迹归一化到像素级别,从而实现对不同轨迹的泛化。奖励函数基于3D occupancy信息,定义了驾驶合规性和安全性的规则,例如避免碰撞、保持车道等。具体的网络结构和参数设置在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
实验结果表明,OmniNWM在视频生成质量(FID, LPIPS)、控制精度和长时程稳定性方面均优于现有方法。例如,在长时程视频生成任务中,OmniNWM的FID指标比现有最佳方法提高了10%以上。此外,OmniNWM还能够生成符合驾驶规则和安全要求的视频,证明了其在自动驾驶领域的潜力。
🎯 应用场景
OmniNWM可应用于自动驾驶系统的开发和测试,例如用于训练自动驾驶策略、评估自动驾驶算法的安全性,以及生成用于数据增强的合成数据。此外,该模型还可以用于虚拟现实和游戏等领域,例如用于生成逼真的驾驶场景。
📄 摘要(原文)
Autonomous driving world models are expected to work effectively across three core dimensions: state, action, and reward. Existing models, however, are typically restricted to limited state modalities, short video sequences, imprecise action control, and a lack of reward awareness. In this paper, we introduce OmniNWM, an omniscient panoramic navigation world model that addresses all three dimensions within a unified framework. For state, OmniNWM jointly generates panoramic videos of RGB, semantics, metric depth, and 3D occupancy. A flexible forcing strategy enables high-quality long-horizon auto-regressive generation. For action, we introduce a normalized panoramic Plucker ray-map representation that encodes input trajectories into pixel-level signals, enabling highly precise and generalizable control over panoramic video generation. Regarding reward, we move beyond learning reward functions with external image-based models: instead, we leverage the generated 3D occupancy to directly define rule-based dense rewards for driving compliance and safety. Extensive experiments demonstrate that OmniNWM achieves state-of-the-art performance in video generation, control accuracy, and long-horizon stability, while providing a reliable closed-loop evaluation framework through occupancy-grounded rewards. Project page is available at https://arlo0o.github.io/OmniNWM/.