Proactive Reasoning-with-Retrieval Framework for Medical Multimodal Large Language Models
作者: Lehan Wang, Yi Qin, Honglong Yang, Xiaomeng Li
分类: cs.CV
发布日期: 2025-10-21
备注: Work in progress
🔗 代码/项目: GITHUB
💡 一句话要点
提出Med-RwR框架,通过主动检索增强医学多模态大语言模型的推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学多模态 大语言模型 检索增强生成 主动推理 强化学习
📋 核心要点
- 现有医学多模态大语言模型依赖内部知识推理,易出现幻觉,缺乏外部知识的有效利用。
- Med-RwR框架通过主动检索外部知识,结合视觉和文本信息,增强模型推理能力。
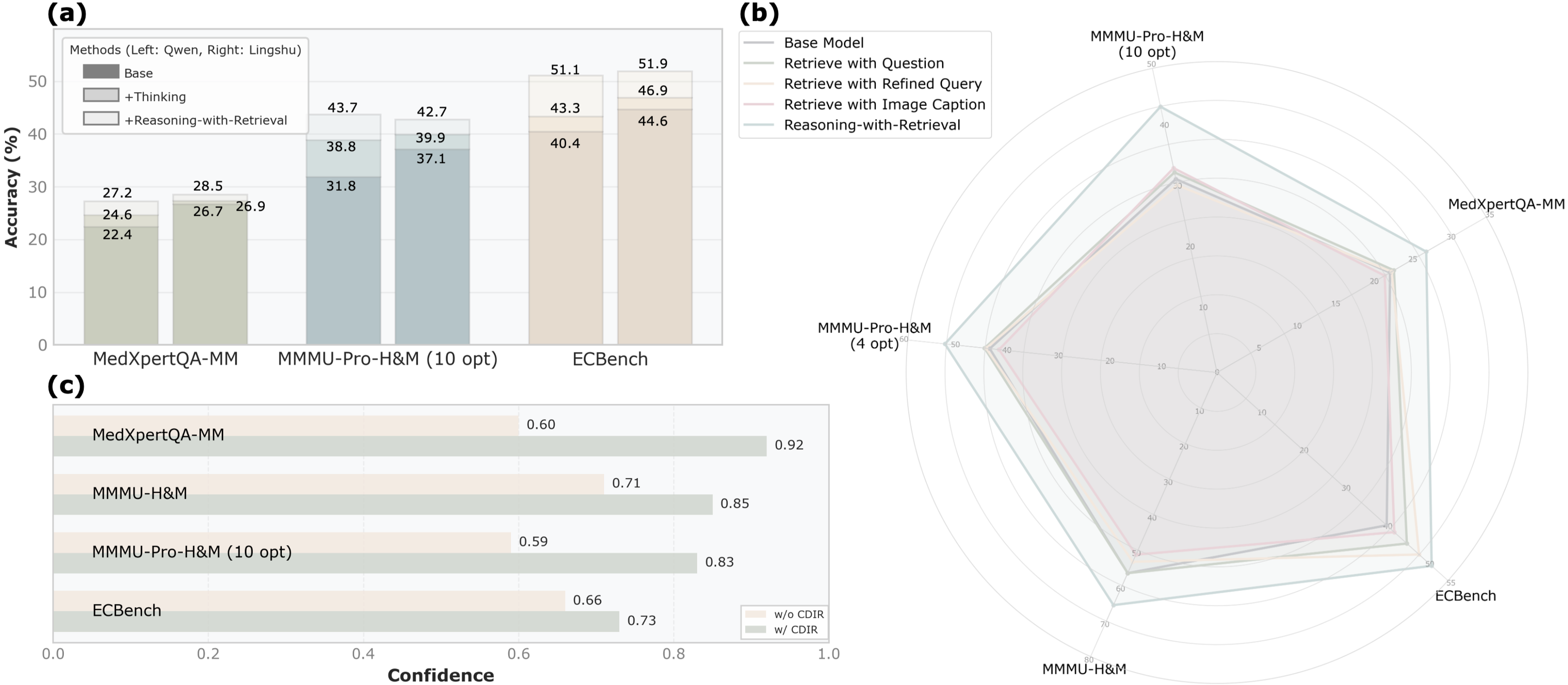
- 实验表明,Med-RwR在多个医学基准上显著提升性能,并展现出良好的领域泛化能力。
📝 摘要(中文)
本文提出了一种用于医学多模态大语言模型(MLLMs)的主动推理-检索框架Med-RwR,旨在提升模型在医学应用中的推理能力,使其能够透明地分析医学扫描图像并提供可靠的诊断。现有医学MLLMs仅依赖内部知识进行推理,当遇到超出训练范围的案例时,容易产生幻觉推理和事实不准确。虽然最近的Agentic RAG方法激发了医学模型在推理过程中的主动检索能力,但它们仅限于单模态LLMs,忽略了推理和检索过程中至关重要的视觉信息。Med-RwR通过在推理过程中查询观察到的症状或领域特定的医学概念来主动检索外部知识。具体而言,设计了一个具有定制奖励的两阶段强化学习策略,以激励模型利用视觉诊断结果和文本临床信息进行有效检索。此外,提出了一种置信度驱动的图像重检索(CDIR)方法,用于在检测到低预测置信度时进行测试时缩放。在多个公共医学基准上的评估表明,Med-RwR相对于基线模型有显著改进,证明了通过外部知识集成增强推理能力的有效性。Med-RwR还表现出对不熟悉领域的显著泛化能力,在提出的心动超声基准(ECBench)上获得了8.8%的性能提升,尽管训练语料库中缺乏心动超声数据。
🔬 方法详解
问题定义:现有医学多模态大语言模型在推理时主要依赖于模型内部的知识,这导致模型在遇到超出训练范围的病例时,容易产生“幻觉”现象,即生成不准确甚至错误的信息。现有的检索增强生成(RAG)方法主要集中在单模态语言模型上,忽略了医学图像中包含的重要视觉信息,无法充分利用多模态数据进行推理。
核心思路:本文的核心思路是让医学多模态大语言模型在推理过程中能够主动地检索外部知识,从而弥补模型内部知识的不足,减少“幻觉”现象的发生。通过结合视觉诊断结果和文本临床信息,模型可以更准确地理解病例,并检索到相关的外部知识,从而提高推理的准确性和可靠性。
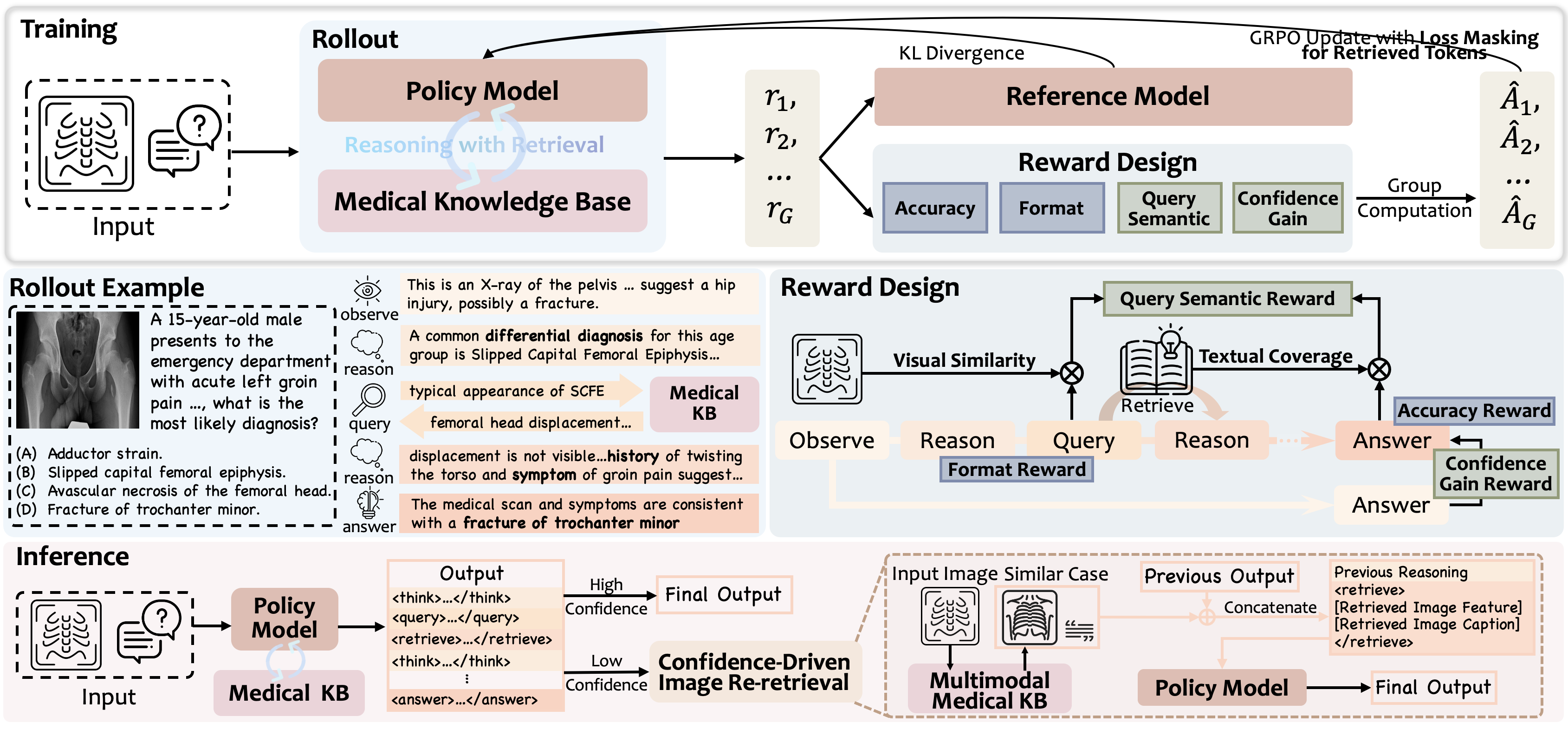
技术框架:Med-RwR框架主要包含以下几个关键模块:1) 多模态输入编码:将医学图像和文本信息编码成向量表示。2) 主动检索模块:根据当前推理状态,生成检索查询,并从外部知识库中检索相关信息。3) 知识融合模块:将检索到的外部知识与原始输入信息融合,形成增强的输入表示。4) 推理模块:基于增强的输入表示,进行诊断推理,并生成诊断报告。5) 置信度驱动的图像重检索(CDIR):在测试阶段,当模型预测置信度较低时,触发图像重检索机制,进一步提升诊断准确率。
关键创新:Med-RwR的关键创新在于:1) 多模态主动检索:模型能够同时利用视觉和文本信息进行检索,从而更准确地找到相关的外部知识。2) 两阶段强化学习策略:通过定制的奖励函数,激励模型有效地利用视觉和文本信息进行检索。3) 置信度驱动的图像重检索:根据模型预测的置信度,动态地调整检索策略,从而提高模型的鲁棒性。
关键设计:在两阶段强化学习中,第一阶段旨在鼓励模型进行检索,奖励函数侧重于检索行为本身。第二阶段则侧重于检索结果的有效性,奖励函数基于诊断结果的准确性。置信度驱动的图像重检索(CDIR)方法使用模型预测概率作为置信度指标,当置信度低于阈值时,触发重检索。具体的阈值设置和重检索策略需要根据具体数据集进行调整。
🖼️ 关键图片

📊 实验亮点
Med-RwR在多个公共医学基准上取得了显著的性能提升。例如,在心动超声基准(ECBench)上,Med-RwR获得了8.8%的性能提升,证明了其在不熟悉领域的泛化能力。实验结果表明,通过主动检索外部知识,Med-RwR能够有效地提高医学多模态大语言模型的推理能力和诊断准确性。
🎯 应用场景
Med-RwR框架可应用于多种医学诊断场景,例如疾病诊断、病情评估、治疗方案制定等。该框架能够帮助医生更准确地理解病例,减少误诊漏诊的发生,提高医疗质量。此外,该框架还可以用于医学教育和研究,为医学生和研究人员提供更丰富的知识资源和更强大的分析工具。未来,该技术有望应用于远程医疗、智能辅助诊断等领域,提升医疗服务的可及性和效率。
📄 摘要(原文)
Incentivizing the reasoning ability of Multimodal Large Language Models (MLLMs) is essential for medical applications to transparently analyze medical scans and provide reliable diagnosis. However, existing medical MLLMs rely solely on internal knowledge during reasoning, leading to hallucinated reasoning and factual inaccuracies when encountering cases beyond their training scope. Although recent Agentic Retrieval-Augmented Generation (RAG) methods elicit the medical model's proactive retrieval ability during reasoning, they are confined to unimodal LLMs, neglecting the crucial visual information during reasoning and retrieval. Consequently, we propose the first Multimodal Medical Reasoning-with-Retrieval framework, Med-RwR, which actively retrieves external knowledge by querying observed symptoms or domain-specific medical concepts during reasoning. Specifically, we design a two-stage reinforcement learning strategy with tailored rewards that stimulate the model to leverage both visual diagnostic findings and textual clinical information for effective retrieval. Building on this foundation, we further propose a Confidence-Driven Image Re-retrieval (CDIR) method for test-time scaling when low prediction confidence is detected. Evaluation on various public medical benchmarks demonstrates Med-RwR's significant improvements over baseline models, proving the effectiveness of enhancing reasoning capabilities with external knowledge integration. Furthermore, Med-RwR demonstrates remarkable generalizability to unfamiliar domains, evidenced by 8.8% performance gain on our proposed EchoCardiography Benchmark (ECBench), despite the scarcity of echocardiography data in the training corpus. Our data, model, and codes will be made publicly available at https://github.com/xmed-lab/Med-RwR.