GeoDiff: Geometry-Guided Diffusion for Metric Depth Estimation
作者: Tuan Pham, Thanh-Tung Le, Xiaohui Xie, Stephan Mandt
分类: cs.CV
发布日期: 2025-10-21
备注: Accepted to ICCV Findings 2025. The first two authors contributed equally. The last two authors share co-corresponding authorship
💡 一句话要点
GeoDiff:提出几何引导的扩散模型用于度量深度估计,无需重新训练。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 度量深度估计 扩散模型 立体视觉 几何约束 单目深度估计
📋 核心要点
- 单目深度估计面临尺度模糊性问题,难以准确预测绝对度量深度。
- 利用预训练的潜在扩散模型,结合立体视觉的几何约束,学习尺度和偏移。
- 无需重新训练,即可在室内外复杂环境中达到或超过现有最佳方法。
📝 摘要(中文)
本文提出了一种新颖的度量深度估计框架,该框架利用立体视觉引导来增强预训练的基于扩散的单目深度估计(DB-MDE)模型。现有的DB-MDE方法在预测相对深度方面表现出色,但由于单图像场景中的尺度模糊性,估计绝对度量深度仍然具有挑战性。为了解决这个问题,我们将深度估计重新定义为一个逆问题,利用以RGB图像为条件的预训练潜在扩散模型(LDM),结合基于立体的几何约束,来学习尺度和偏移,从而实现精确的深度恢复。我们的免训练解决方案可以无缝集成到现有的DB-MDE框架中,并推广到室内、室外和复杂环境。大量的实验表明,我们的方法在具有半透明和镜面反射表面的挑战性场景中,能够匹配或超过最先进的方法,而且无需重新训练。
🔬 方法详解
问题定义:论文旨在解决单目深度估计中存在的尺度模糊性问题,即现有基于扩散模型的单目深度估计方法(DB-MDE)虽然能较好地预测相对深度,但在估计绝对度量深度时精度不足。这是因为单张图像本身缺乏绝对尺度的信息,导致深度估计结果存在不确定性。
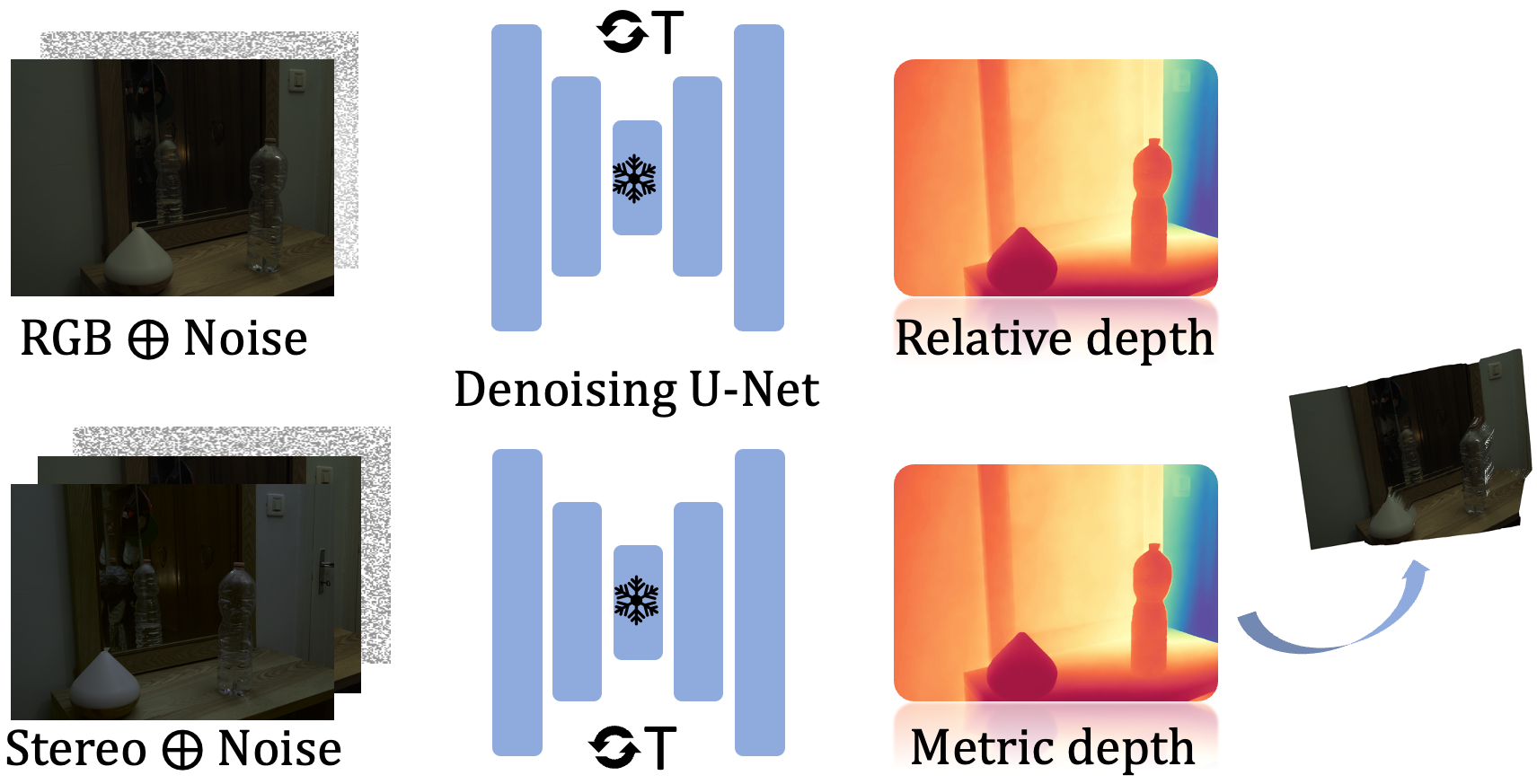
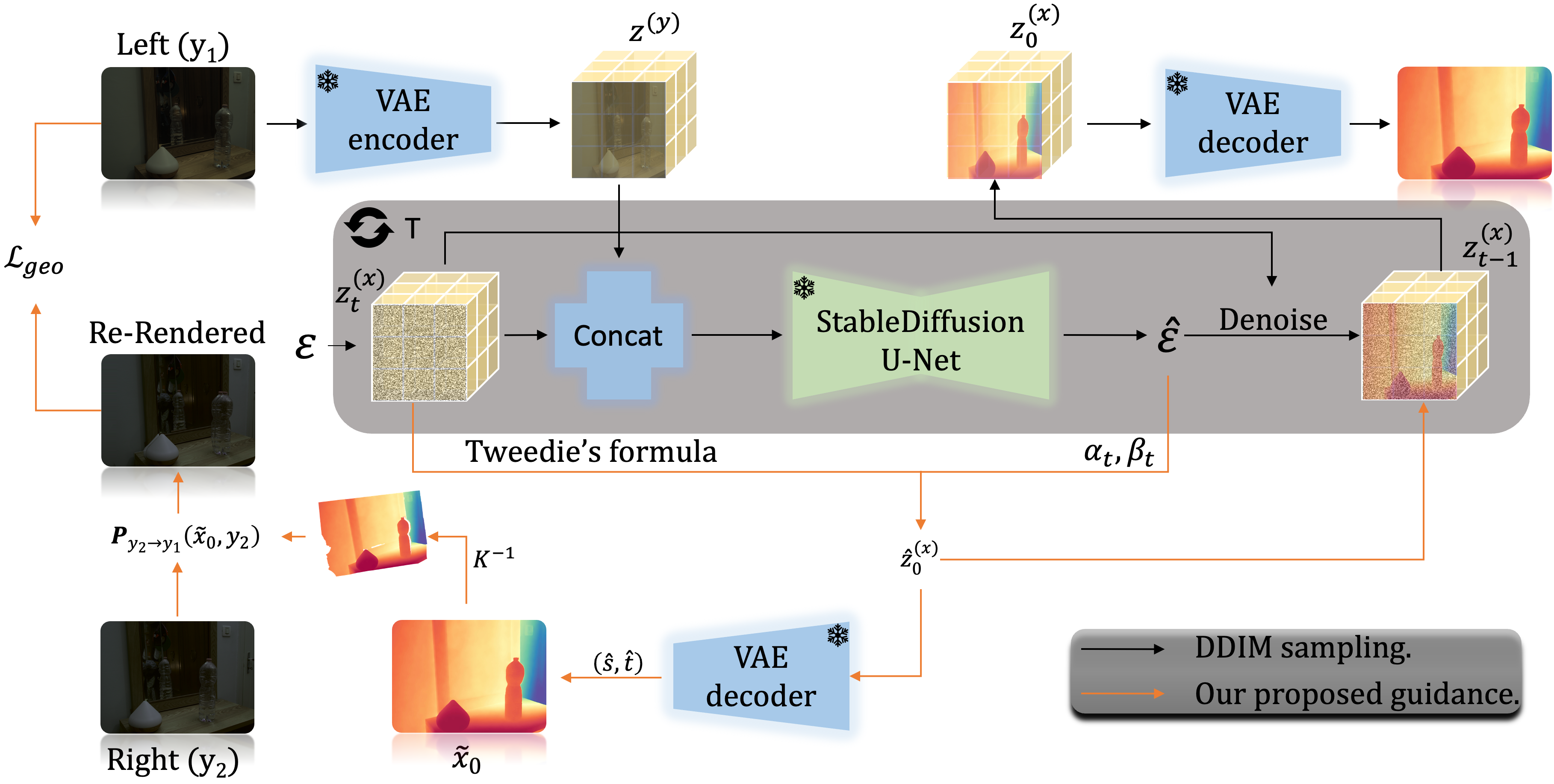
核心思路:论文将深度估计问题重新定义为一个逆问题,并利用立体视觉提供的几何约束来解决尺度模糊性。核心思想是利用预训练的潜在扩散模型(LDM)作为先验知识,并结合立体匹配得到的几何信息,学习一个尺度和偏移量,从而将相对深度转换为绝对度量深度。
技术框架:整体框架包含以下几个主要步骤:1) 使用预训练的LDM对输入RGB图像进行编码,得到潜在表示;2) 利用立体匹配算法(如SGM)提取视差图,并将其转换为三维点云;3) 将点云作为几何约束,与LDM的潜在表示相结合,通过优化过程学习尺度和偏移量;4) 使用学习到的尺度和偏移量对LDM的深度预测结果进行校正,得到最终的度量深度估计结果。整个过程无需重新训练LDM。
关键创新:该方法最大的创新在于将立体视觉的几何约束与预训练的扩散模型相结合,从而在不重新训练模型的情况下,实现了从相对深度到绝对度量深度的转换。这避免了从头训练深度估计模型的巨大计算成本,并充分利用了预训练模型强大的先验知识。
关键设计:论文的关键设计包括:1) 使用预训练的LDM作为深度估计的先验;2) 利用立体匹配算法提取精确的几何约束;3) 设计合适的优化目标函数,以学习尺度和偏移量,该目标函数平衡了几何约束和LDM的先验知识;4) 采用免训练的方式,直接将该方法应用于现有的DB-MDE框架。
🖼️ 关键图片

📊 实验亮点
实验结果表明,GeoDiff在具有半透明和镜面反射表面的挑战性场景中,能够匹配或超过最先进的深度估计方法,且无需重新训练。这表明该方法具有很强的鲁棒性和泛化能力。具体的性能数据(如RMSE、MAE等)在论文中进行了详细的对比和分析。
🎯 应用场景
该研究成果可广泛应用于机器人导航、自动驾驶、三维重建、虚拟现实等领域。精确的度量深度估计对于机器人理解周围环境、规划运动轨迹至关重要。在自动驾驶领域,准确的深度信息是车辆感知和决策的基础。此外,该方法还可以用于生成高质量的三维模型,提升虚拟现实体验。
📄 摘要(原文)
We introduce a novel framework for metric depth estimation that enhances pretrained diffusion-based monocular depth estimation (DB-MDE) models with stereo vision guidance. While existing DB-MDE methods excel at predicting relative depth, estimating absolute metric depth remains challenging due to scale ambiguities in single-image scenarios. To address this, we reframe depth estimation as an inverse problem, leveraging pretrained latent diffusion models (LDMs) conditioned on RGB images, combined with stereo-based geometric constraints, to learn scale and shift for accurate depth recovery. Our training-free solution seamlessly integrates into existing DB-MDE frameworks and generalizes across indoor, outdoor, and complex environments. Extensive experiments demonstrate that our approach matches or surpasses state-of-the-art methods, particularly in challenging scenarios involving translucent and specular surfaces, all without requiring retraining.