BlendCLIP: Bridging Synthetic and Real Domains for Zero-Shot 3D Object Classification with Multimodal Pretraining
作者: Ajinkya Khoche, Gergő László Nagy, Maciej Wozniak, Thomas Gustafsson, Patric Jensfelt
分类: cs.CV
发布日期: 2025-10-21
备注: Under Review
🔗 代码/项目: GITHUB
💡 一句话要点
BlendCLIP:通过多模态预训练桥接合成与真实域,实现零样本3D物体分类
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 零样本学习 3D物体分类 多模态预训练 领域自适应 课程学习 CLIP 点云处理
📋 核心要点
- 现有零样本3D物体分类方法难以应对合成数据与真实LiDAR数据间的领域差异,限制了其在实际场景中的应用。
- BlendCLIP通过多模态预训练和课程学习的数据混合策略,有效结合合成数据和真实数据的优势,弥合领域鸿沟。
- 实验表明,BlendCLIP仅需少量真实数据即可显著提升零样本分类精度,并在nuScenes等数据集上取得SOTA性能。
📝 摘要(中文)
零样本3D物体分类对于自动驾驶等现实应用至关重要,但常受到训练所用的合成数据与真实世界中稀疏、嘈杂的激光雷达扫描之间显著领域差距的阻碍。当前仅在合成数据上训练的方法无法泛化到室外场景,而仅在真实数据上训练的方法则缺乏识别稀有或未见物体的语义多样性。我们提出了BlendCLIP,一个多模态预训练框架,通过策略性地结合两个领域的优势来弥合这种合成到真实的差距。我们首先提出了一个pipeline,用于生成大规模的物体级别三元组数据集——包含点云、图像和文本描述——直接从真实世界驾驶数据和人工标注的3D框中挖掘。我们的核心贡献是一种基于课程的数据混合策略,该策略首先将模型建立在语义丰富的合成CAD数据上,然后再逐步将其适应真实世界扫描的特定特征。实验表明,我们的方法具有很高的标签效率:在训练中每批次引入低至1.5%的真实世界样本,即可将nuScenes基准上的零样本精度提高27%。因此,我们的最终模型在nuScenes和TruckScenes等具有挑战性的室外数据集上实现了最先进的性能,在nuScenes上比最佳现有方法提高了19.3%,同时保持了在各种合成基准上的强大泛化能力。我们的研究结果表明,有效的领域自适应,而不是全面的真实世界标注,是解锁鲁棒的开放词汇3D感知的关键。我们的代码和数据集将在接受后发布在https://github.com/kesu1/BlendCLIP。
🔬 方法详解
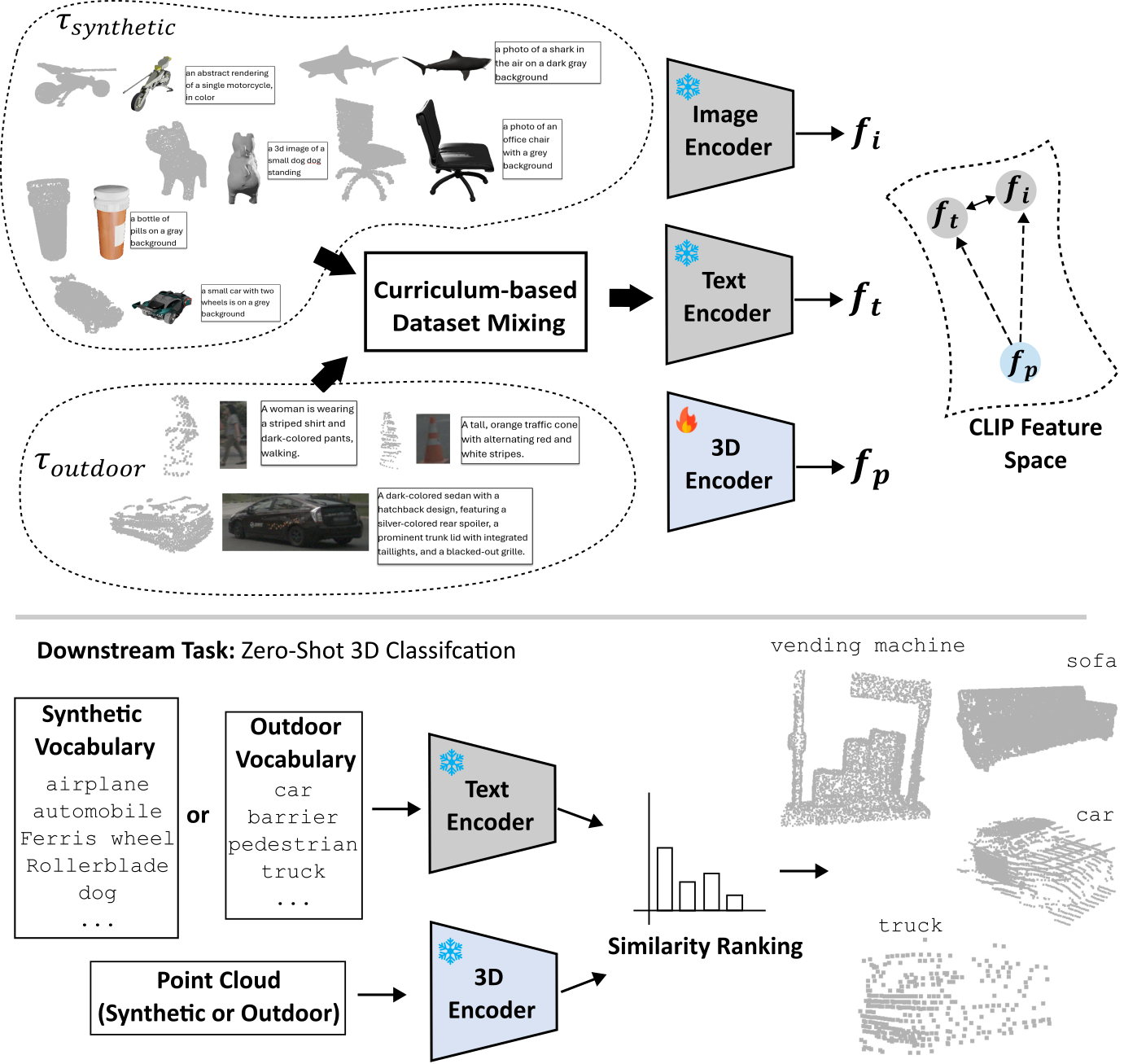
问题定义:论文旨在解决零样本3D物体分类中,由于合成数据和真实LiDAR数据之间存在显著领域差异,导致模型泛化能力差的问题。现有方法要么依赖大量真实数据标注,成本高昂;要么仅使用合成数据训练,无法适应真实场景的噪声和稀疏性。
核心思路:BlendCLIP的核心思路是利用多模态预训练框架,结合合成数据和真实数据的优势,通过课程学习的方式逐步将模型从合成域迁移到真实域。模型首先在语义丰富的合成数据上学习通用特征,然后逐步适应真实数据的特定特征,从而提高零样本分类的泛化能力。
技术框架:BlendCLIP的整体框架包含以下几个主要模块:1) 数据集构建:构建包含点云、图像和文本描述的三元组数据集,同时包含合成数据和真实数据。2) 多模态预训练:使用CLIP模型作为骨干网络,将点云、图像和文本嵌入到统一的特征空间。3) 课程学习:设计课程学习策略,逐步增加真实数据在训练中的比例,引导模型从合成域迁移到真实域。
关键创新:BlendCLIP的关键创新在于其课程学习的数据混合策略。该策略不是简单地混合合成数据和真实数据,而是根据模型的学习进度,逐步增加真实数据的比例。这种策略可以有效地避免模型过早地受到真实数据噪声的影响,从而更好地学习到通用特征。
关键设计:BlendCLIP的关键设计包括:1) 使用CLIP模型作为骨干网络,利用其强大的多模态表示能力。2) 设计课程学习策略,逐步增加真实数据在训练中的比例。3) 使用对比学习损失函数,鼓励模型学习到点云、图像和文本之间的一致性表示。具体而言,真实数据占比从0%开始,逐步增加到1.5%甚至更高,具体增加策略未知。
🖼️ 关键图片


📊 实验亮点
BlendCLIP在nuScenes数据集上实现了显著的性能提升,零样本分类精度比现有最佳方法提高了19.3%。即使仅使用少量真实数据(每批次1.5%),也能将零样本精度提高27%。实验结果表明,有效的领域自适应比大规模真实数据标注更重要,为未来的3D感知研究提供了新的方向。
🎯 应用场景
BlendCLIP在自动驾驶、机器人导航、场景理解等领域具有广泛的应用前景。它可以帮助机器人更好地理解周围环境,识别各种物体,从而实现更安全、更智能的自主行为。该研究降低了对大量真实数据标注的依赖,使得3D物体识别系统能够更容易地部署到新的场景中,具有重要的实际价值。
📄 摘要(原文)
Zero-shot 3D object classification is crucial for real-world applications like autonomous driving, however it is often hindered by a significant domain gap between the synthetic data used for training and the sparse, noisy LiDAR scans encountered in the real-world. Current methods trained solely on synthetic data fail to generalize to outdoor scenes, while those trained only on real data lack the semantic diversity to recognize rare or unseen objects. We introduce BlendCLIP, a multimodal pretraining framework that bridges this synthetic-to-real gap by strategically combining the strengths of both domains. We first propose a pipeline to generate a large-scale dataset of object-level triplets -- consisting of a point cloud, image, and text description -- mined directly from real-world driving data and human annotated 3D boxes. Our core contribution is a curriculum-based data mixing strategy that first grounds the model in the semantically rich synthetic CAD data before progressively adapting it to the specific characteristics of real-world scans. Our experiments show that our approach is highly label-efficient: introducing as few as 1.5\% real-world samples per batch into training boosts zero-shot accuracy on the nuScenes benchmark by 27\%. Consequently, our final model achieves state-of-the-art performance on challenging outdoor datasets like nuScenes and TruckScenes, improving over the best prior method by 19.3\% on nuScenes, while maintaining strong generalization on diverse synthetic benchmarks. Our findings demonstrate that effective domain adaptation, not full-scale real-world annotation, is the key to unlocking robust open-vocabulary 3D perception. Our code and dataset will be released upon acceptance on https://github.com/kesu1/BlendCLIP.