Xihe: Scalable Zero-Shot Time Series Learner Via Hierarchical Interleaved Block Attention
作者: Yinbo Sun, Yuchen Fang, Zhibo Zhu, Jia Li, Yu Liu, Qiwen Deng, Jun Zhou, Hang Yu, Xingyu Lu, Lintao Ma
分类: cs.CV, cs.AI
发布日期: 2025-10-20
💡 一句话要点
提出基于分层交错块注意力(HIBA)的Xihe,用于可扩展的零样本时间序列学习。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时间序列预测 零样本学习 Transformer 注意力机制 多尺度依赖 分层注意力 时间序列基础模型
📋 核心要点
- 现有时间序列基础模型在跨领域迁移时,难以有效捕捉时间序列数据中固有的多尺度时间依赖性。
- 提出分层交错块注意力(HIBA),通过分层的块内和块间稀疏注意力来捕捉多尺度依赖关系。
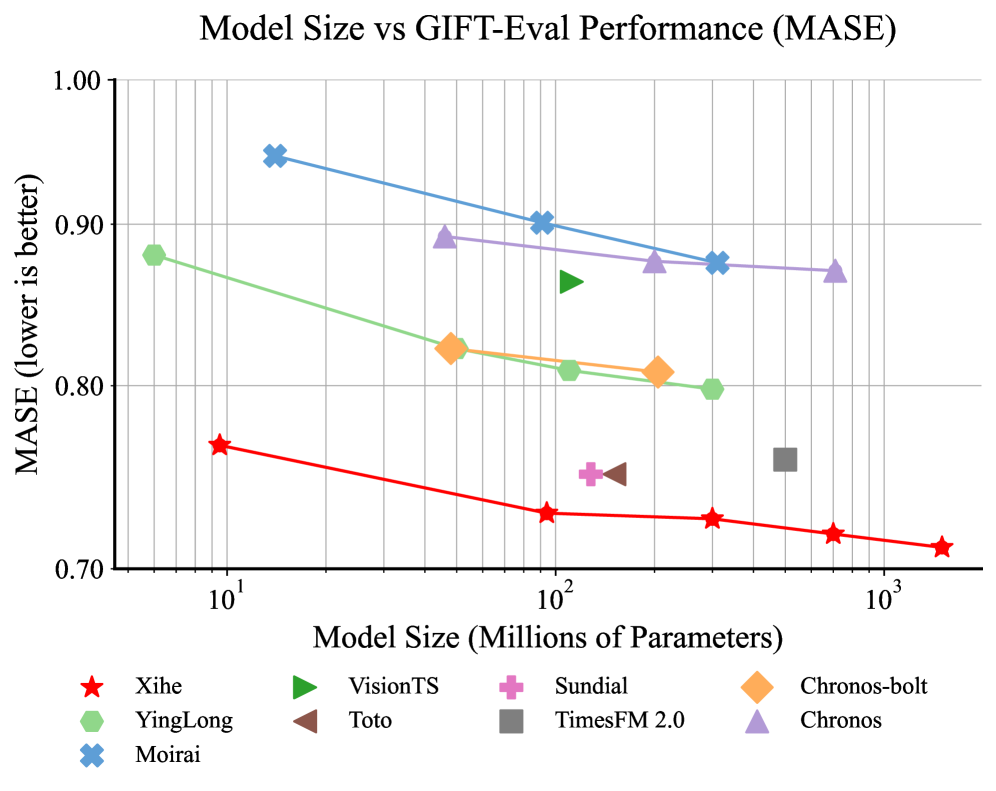
- Xihe模型家族在GIFT-Eval基准测试中表现出色,Xihe-tiny超越多数TSFM,Xihe-max达到新的SOTA零样本性能。
📝 摘要(中文)
时间序列基础模型(TSFMs)的发展受益于语言模型的架构迁移。然而,现有TSFMs直接采用跨领域架构,限制了其有效捕捉时间序列数据固有的多尺度时间依赖性,尤其是在具有不同底层模式和采样策略的数据集上进行零样本迁移时。为了解决这些挑战,我们提出了分层交错块注意力(HIBA),它采用分层的块内和块间稀疏注意力来有效地捕捉多尺度依赖关系。块内注意力促进局部信息交换,块间注意力跨块操作以捕捉全局时间模式交互和动态演化。利用HIBA架构,我们推出了Xihe,一个可扩展的TSFM家族,参数规模从超高效的950万到高容量的15亿不等。在全面的GIFT-Eval基准测试中,我们最紧凑的Xihe-tiny模型(950万参数)超越了大多数当代TSFM,展示了卓越的参数效率。更令人印象深刻的是,Xihe-max(15亿参数)建立了新的最先进的零样本性能,大幅超越了之前的最佳结果。这种在整个参数范围内一致的卓越性能为HIBA的卓越泛化能力和架构优势提供了有力的证据。
🔬 方法详解
问题定义:现有时间序列基础模型(TSFMs)直接采用跨领域架构,无法有效捕捉时间序列数据中固有的多尺度时间依赖性。这导致在具有不同底层模式和采样策略的数据集上进行零样本迁移时性能下降。现有方法缺乏对局部和全局时间模式的有效建模能力。
核心思路:论文的核心思路是设计一种能够有效捕捉时间序列数据中多尺度依赖关系的注意力机制。通过分层结构,分别在块内和块间进行注意力计算,从而同时关注局部细节和全局模式。这种设计旨在提高模型在零样本迁移场景下的泛化能力。
技术框架:Xihe模型家族基于Transformer架构,核心是HIBA模块。整体流程包括:输入时间序列数据,通过嵌入层进行特征提取,然后通过多层HIBA模块进行特征变换,最后通过预测头输出预测结果。HIBA模块是整个框架的核心,负责捕捉时间序列中的多尺度依赖关系。
关键创新:关键创新在于提出的分层交错块注意力(HIBA)机制。HIBA通过分层结构,将注意力计算分解为块内和块间两个层次。块内注意力关注局部信息交换,块间注意力关注全局时间模式交互和动态演化。这种分层结构使得模型能够同时捕捉局部细节和全局模式,从而提高模型的泛化能力。与传统注意力机制相比,HIBA更适合处理时间序列数据中的多尺度依赖关系。
关键设计:HIBA模块的关键设计包括:1) 将时间序列数据划分为多个块;2) 在每个块内进行自注意力计算,捕捉局部依赖关系;3) 在块之间进行注意力计算,捕捉全局依赖关系;4) 使用稀疏注意力机制,降低计算复杂度。具体的参数设置和网络结构细节在论文中有详细描述,例如块的大小、注意力头的数量等。损失函数采用标准的预测损失函数,例如均方误差(MSE)。
🖼️ 关键图片


📊 实验亮点
Xihe模型家族在GIFT-Eval基准测试中取得了显著成果。Xihe-tiny模型(950万参数)超越了大多数当代TSFM,展示了卓越的参数效率。Xihe-max模型(15亿参数)建立了新的最先进的零样本性能,大幅超越了之前的最佳结果。实验结果表明,HIBA架构具有卓越的泛化能力和架构优势。
🎯 应用场景
该研究成果可广泛应用于各种时间序列预测任务,例如金融市场预测、能源消耗预测、医疗健康监测、工业生产优化等。通过零样本迁移能力,可以快速部署到新的数据集和应用场景,降低模型训练成本。该研究对于推动时间序列基础模型的发展具有重要意义,有望促进更多实际应用。
📄 摘要(原文)
The rapid advancement of time series foundation models (TSFMs) has been propelled by migrating architectures from language models. While existing TSFMs demonstrate impressive performance, their direct adoption of cross-domain architectures constrains effective capture of multiscale temporal dependencies inherent to time series data. This limitation becomes particularly pronounced during zero-shot transfer across datasets with divergent underlying patterns and sampling strategies. To address these challenges, we propose Hierarchical Interleaved Block Attention (HIBA) which employs hierarchical inter- and intra-block sparse attention to effectively capture multi-scale dependencies. Intra-block attention facilitates local information exchange, and inter-block attention operates across blocks to capture global temporal pattern interaction and dynamic evolution. Leveraging the HIBA architecture, we introduce Xihe, a scalable TSFM family spanning from an ultra-efficient 9.5M parameter configuration to high-capacity 1.5B variant. Evaluated on the comprehensive GIFT-Eval benchmark, our most compact Xihe-tiny model (9.5M) surpasses the majority of contemporary TSFMs, demonstrating remarkable parameter efficiency. More impressively, Xihe-max (1.5B) establishes new state-of-the-art zero-shot performance, surpassing previous best results by a substantial margin. This consistent performance excellence across the entire parameter spectrum provides compelling evidence for the exceptional generalization capabilities and architectural superiority of HIBA.