World-in-World: World Models in a Closed-Loop World
作者: Jiahan Zhang, Muqing Jiang, Nanru Dai, Taiming Lu, Arda Uzunoglu, Shunchi Zhang, Yana Wei, Jiahao Wang, Vishal M. Patel, Paul Pu Liang, Daniel Khashabi, Cheng Peng, Rama Chellappa, Tianmin Shu, Alan Yuille, Yilun Du, Jieneng Chen
分类: cs.CV
发布日期: 2025-10-20
备注: Code is at https://github.com/World-In-World/world-in-world
💡 一句话要点
World-in-World:首个闭环世界模型基准平台,评估具身智能体的预测感知能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 世界模型 具身智能 闭环控制 在线规划 模型预测控制
📋 核心要点
- 现有世界模型评估侧重视觉质量,忽略了其在具身任务中的实用性,缺乏闭环环境下的有效评估。
- World-in-World平台提供统一的在线规划策略和标准化动作API,支持异构世界模型在闭环环境中进行决策。
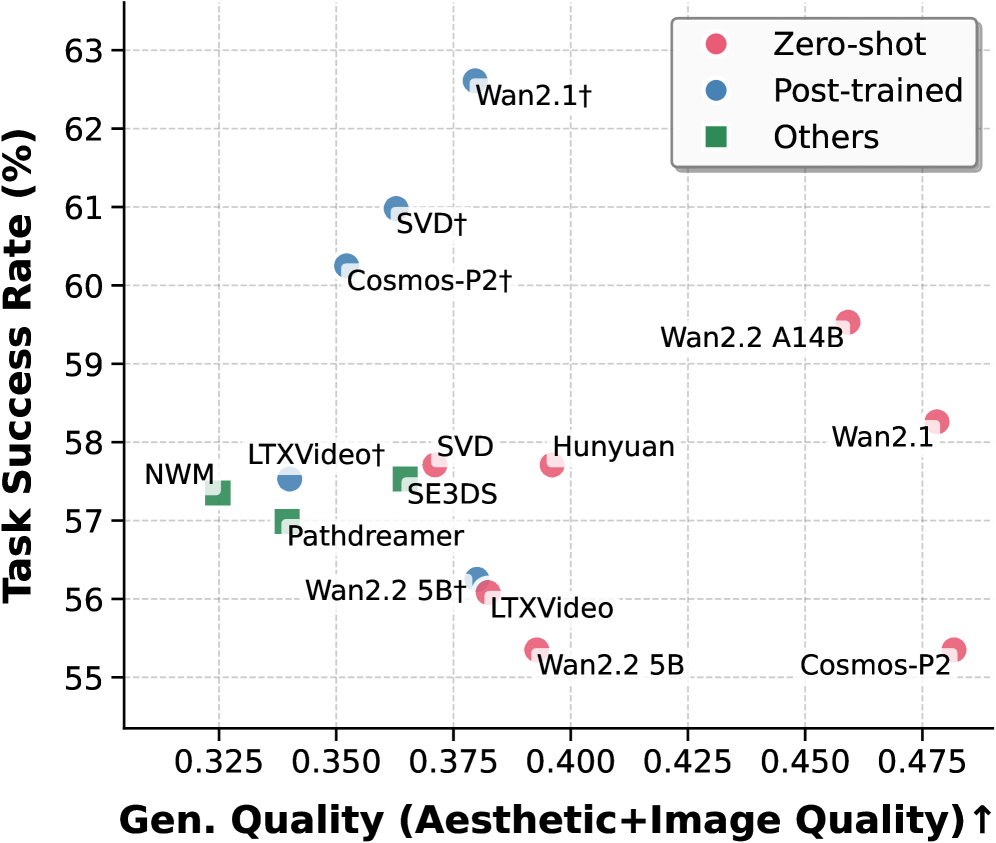
- 实验表明,视觉质量并非成功的唯一因素,可控性更重要;后训练优于升级预训练模型;增加推理计算可提升性能。
📝 摘要(中文)
生成式世界模型(WMs)现在可以模拟具有惊人视觉真实感的世界,这自然引出了一个问题:它们是否能赋予具身智能体用于决策的预测感知能力?由于评估的碎片化,这个问题上的进展受到限制:大多数现有基准采用开放循环协议,孤立地强调视觉质量,而未解决具身效用的核心问题,即WMs是否真正帮助智能体在具身任务中取得成功?为了解决这一差距,我们引入了World-in-World,这是第一个开放平台,用于在模拟真实智能体-环境交互的闭环世界中对WMs进行基准测试。World-in-World提供了一个统一的在线规划策略和一个标准化的动作API,从而能够为决策制定提供异构WMs。我们策划了四个闭环环境,严格评估不同的WMs,优先考虑任务成功作为主要指标,并超越了对视觉质量的常见关注;我们还提出了具身环境中世界模型的第一个数据缩放定律。我们的研究揭示了三个令人惊讶的发现:(1)仅凭视觉质量并不能保证任务成功,可控性更为重要;(2)使用动作-观察数据进行后训练比升级预训练的视频生成器更有效;(3)分配更多的推理时间计算可以使WMs显着提高闭环性能。
🔬 方法详解
问题定义:现有世界模型评估体系主要关注视觉质量,缺乏在真实具身任务闭环环境下的有效评估。这导致了世界模型的视觉逼真度与智能体在实际任务中的表现脱节,难以判断世界模型是否真正有助于智能体的决策和控制。现有方法难以有效评估世界模型在具身智能体中的实用性。
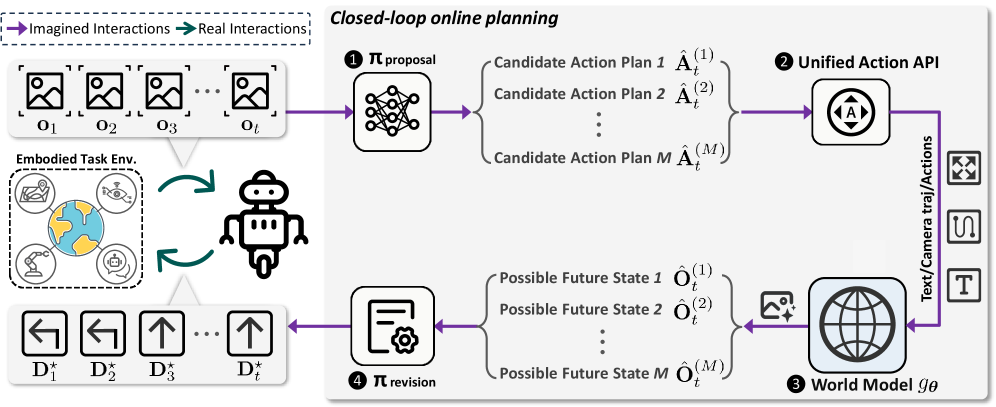
核心思路:World-in-World的核心思路是构建一个闭环的具身智能体评估平台,该平台模拟真实智能体与环境的交互过程,并提供标准化的接口和评估指标。通过在闭环环境中评估世界模型,可以更准确地衡量其在具身任务中的实用性,并发现现有评估方法忽略的关键因素。
技术框架:World-in-World平台包含以下主要模块:1) 闭环环境:提供多个模拟环境,模拟真实智能体与环境的交互。2) 统一在线规划策略:提供标准化的在线规划算法,用于智能体在环境中的决策。3) 标准化动作API:提供统一的动作接口,方便不同世界模型与环境进行交互。4) 评估指标:主要关注任务成功率,并提供其他辅助指标,如视觉质量等。整体流程是:智能体通过动作API与环境交互,环境返回观测结果,世界模型根据观测结果进行预测,在线规划策略根据世界模型的预测结果生成动作,重复以上过程直到任务完成或失败。
关键创新:World-in-World的关键创新在于:1) 首次提出了一个闭环的世界模型评估平台,更贴近真实应用场景。2) 强调任务成功率作为主要评估指标,超越了对视觉质量的片面关注。3) 提出了具身环境中世界模型的数据缩放定律,为世界模型的训练提供了指导。
关键设计:World-in-World平台采用模块化设计,方便扩展和定制。在线规划策略采用模型预测控制(MPC)算法,可以根据世界模型的预测结果进行优化。动作API采用标准化的格式,方便不同世界模型接入。评估指标包括任务成功率、平均奖励、视觉质量等。平台还提供了数据收集工具,方便用户收集训练数据。
🖼️ 关键图片

📊 实验亮点
实验结果表明,视觉质量与任务成功率并非正相关,可控性更为重要。使用动作-观察数据进行后训练比升级预训练视频生成器更有效。增加推理时间计算可以显著提高闭环性能。此外,该研究还提出了具身环境中世界模型的数据缩放定律,为模型训练提供了指导。
🎯 应用场景
该研究成果可应用于机器人、自动驾驶、游戏AI等领域。通过World-in-World平台,研究人员可以更有效地评估和改进世界模型,从而提升具身智能体的决策和控制能力。该平台还有助于开发更智能、更自主的机器人系统,使其能够更好地适应复杂和动态的环境。
📄 摘要(原文)
Generative world models (WMs) can now simulate worlds with striking visual realism, which naturally raises the question of whether they can endow embodied agents with predictive perception for decision making. Progress on this question has been limited by fragmented evaluation: most existing benchmarks adopt open-loop protocols that emphasize visual quality in isolation, leaving the core issue of embodied utility unresolved, i.e., do WMs actually help agents succeed at embodied tasks? To address this gap, we introduce World-in-World, the first open platform that benchmarks WMs in a closed-loop world that mirrors real agent-environment interactions. World-in-World provides a unified online planning strategy and a standardized action API, enabling heterogeneous WMs for decision making. We curate four closed-loop environments that rigorously evaluate diverse WMs, prioritize task success as the primary metric, and move beyond the common focus on visual quality; we also present the first data scaling law for world models in embodied settings. Our study uncovers three surprises: (1) visual quality alone does not guarantee task success, controllability matters more; (2) scaling post-training with action-observation data is more effective than upgrading the pretrained video generators; and (3) allocating more inference-time compute allows WMs to substantially improve closed-loop performance.