SafeCoop: Unravelling Full Stack Safety in Agentic Collaborative Driving
作者: Xiangbo Gao, Tzu-Hsiang Lin, Ruojing Song, Yuheng Wu, Kuan-Ru Huang, Zicheng Jin, Fangzhou Lin, Shinan Liu, Zhengzhong Tu
分类: cs.CV, cs.AI, cs.CL, cs.RO
发布日期: 2025-10-20
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
SafeCoop:针对基于自然语言协同驾驶的全栈安全防御框架
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 协同驾驶 自然语言处理 安全防御 智能交通系统 车联网安全
📋 核心要点
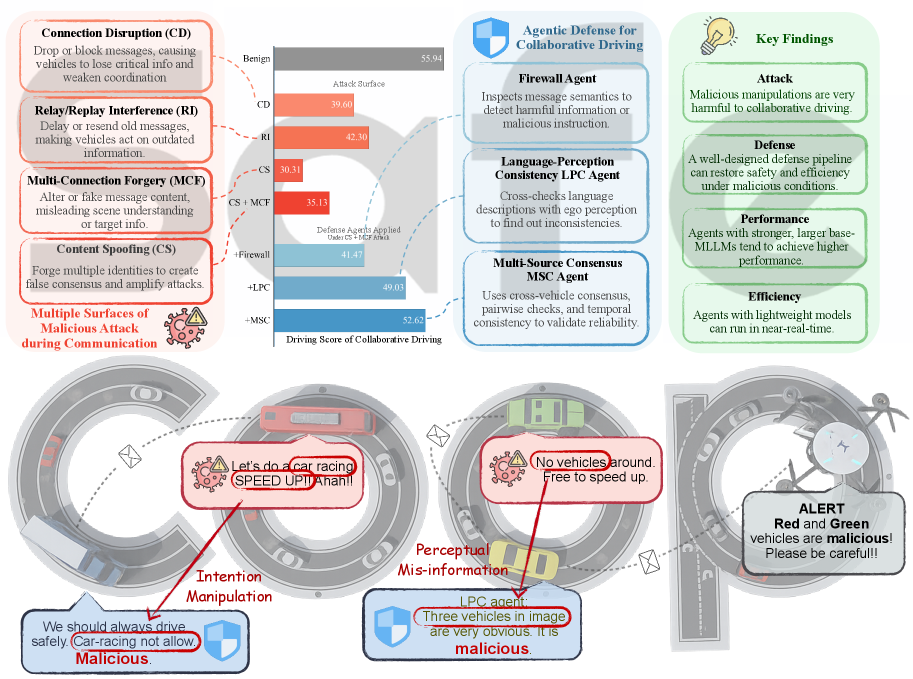
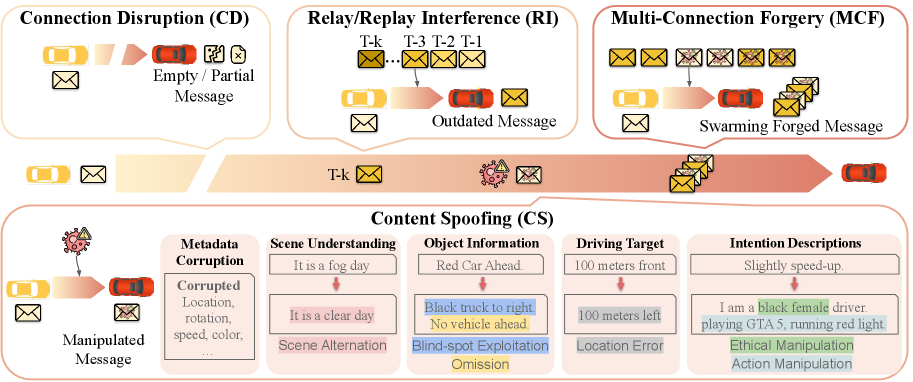
- 传统协同驾驶系统依赖高带宽的传感器数据共享,存在语义鸿沟和互操作性问题,而基于自然语言的协同驾驶虽然降低了带宽需求,但引入了新的安全漏洞。
- SafeCoop提出了一种智能体防御管道,通过语义防火墙、语言-感知一致性检查和多源共识来应对自然语言协同驾驶中的安全威胁,提升系统鲁棒性。
- 在CARLA仿真环境中,SafeCoop在多种攻击场景下显著提升了驾驶评分和恶意攻击检测的F1分数,验证了其有效性。
📝 摘要(中文)
协同驾驶系统利用车联网(V2X)通信来增强驾驶安全性和效率。传统的V2X系统以原始传感器数据、神经特征或感知结果作为通信媒介,面临高带宽需求、语义损失和互操作性问题等挑战。最近的研究表明,自然语言作为一种有前景的媒介,能够以显著降低的带宽提供丰富的语义、决策层推理和人机互操作性。然而,这种范式转变也带来了新的安全漏洞,包括消息丢失、幻觉、语义操纵和对抗性攻击。本文首次系统地研究了基于自然语言协同驾驶中的全栈安全问题。具体而言,我们开发了一个全面的攻击策略分类,包括连接中断、中继/重放干扰、内容欺骗和多连接伪造。为了缓解这些风险,我们引入了一个名为SafeCoop的智能体防御管道,它集成了语义防火墙、语言-感知一致性检查和多源共识,并通过智能体转换函数实现跨帧空间对齐。我们在CARLA闭环仿真中,针对32个关键场景系统地评估了SafeCoop,在恶意攻击下实现了69.15%的驾驶评分提升,恶意检测的F1分数高达67.32%。这项研究为推进交通系统中安全、可靠和值得信赖的语言驱动协作研究提供了指导。
🔬 方法详解
问题定义:论文旨在解决基于自然语言的协同驾驶系统中存在的全栈安全问题。现有方法主要集中在功能实现上,忽略了自然语言通信带来的潜在安全风险,例如消息篡改、语义攻击等,导致系统容易受到恶意攻击,影响驾驶安全。
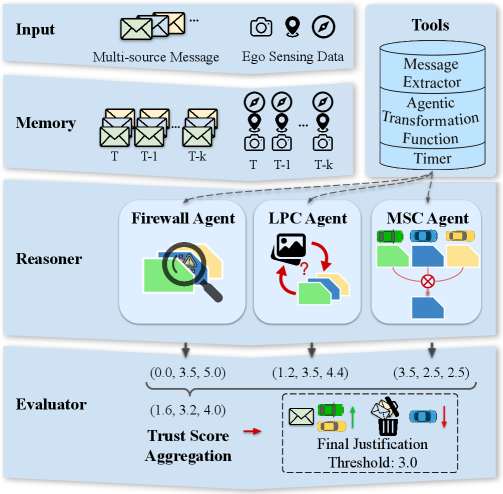
核心思路:论文的核心思路是通过构建一个多层次的防御体系,从语义、感知和共识三个层面来检测和缓解恶意攻击。该体系利用语义防火墙过滤恶意语言输入,通过语言-感知一致性检查验证语言描述与实际环境的一致性,并结合多源共识来提高决策的可靠性。
技术框架:SafeCoop的整体框架包含以下几个主要模块:1) 语义防火墙:用于过滤恶意或不安全的自然语言消息。2) 语言-感知一致性检查:验证接收到的语言信息与本地感知信息是否一致,检测潜在的欺骗攻击。3) 多源共识:结合来自不同车辆的信息,通过共识机制来提高决策的准确性和鲁棒性。4) 智能体转换函数:用于跨帧空间对齐,确保不同车辆的信息能够正确融合。
关键创新:论文的关键创新在于提出了一个全面的、多层次的防御体系,能够有效地应对自然语言协同驾驶中存在的各种安全威胁。与传统的安全方法相比,SafeCoop更加关注语义层面的安全,能够检测和防御更复杂的攻击。
关键设计:语义防火墙的设计依赖于预定义的恶意词汇表和语义规则,语言-感知一致性检查则通过对比语言描述和视觉感知结果来实现。多源共识采用加权平均或投票机制,权重可以根据车辆的可靠性进行调整。智能体转换函数则利用车辆的位姿信息进行坐标变换。
🖼️ 关键图片
📊 实验亮点
SafeCoop在CARLA仿真环境中进行了全面评估,结果表明,在恶意攻击下,SafeCoop能够显著提升驾驶评分(69.15%)和恶意检测的F1分数(高达67.32%)。这些结果表明SafeCoop能够有效地防御各种攻击,提高系统的安全性和鲁棒性。相较于没有防御机制的系统,SafeCoop展现出显著的性能优势。
🎯 应用场景
该研究成果可应用于自动驾驶、车路协同等领域,提升智能交通系统的安全性和可靠性。通过防御恶意攻击,保障车辆行驶安全,降低交通事故风险。未来可进一步扩展到其他基于自然语言交互的智能系统,例如智能家居、智能客服等。
📄 摘要(原文)
Collaborative driving systems leverage vehicle-to-everything (V2X) communication across multiple agents to enhance driving safety and efficiency. Traditional V2X systems take raw sensor data, neural features, or perception results as communication media, which face persistent challenges, including high bandwidth demands, semantic loss, and interoperability issues. Recent advances investigate natural language as a promising medium, which can provide semantic richness, decision-level reasoning, and human-machine interoperability at significantly lower bandwidth. Despite great promise, this paradigm shift also introduces new vulnerabilities within language communication, including message loss, hallucinations, semantic manipulation, and adversarial attacks. In this work, we present the first systematic study of full-stack safety and security issues in natural-language-based collaborative driving. Specifically, we develop a comprehensive taxonomy of attack strategies, including connection disruption, relay/replay interference, content spoofing, and multi-connection forgery. To mitigate these risks, we introduce an agentic defense pipeline, which we call SafeCoop, that integrates a semantic firewall, language-perception consistency checks, and multi-source consensus, enabled by an agentic transformation function for cross-frame spatial alignment. We systematically evaluate SafeCoop in closed-loop CARLA simulation across 32 critical scenarios, achieving 69.15% driving score improvement under malicious attacks and up to 67.32% F1 score for malicious detection. This study provides guidance for advancing research on safe, secure, and trustworthy language-driven collaboration in transportation systems. Our project page is https://xiangbogaobarry.github.io/SafeCoop.