Online In-Context Distillation for Low-Resource Vision Language Models
作者: Zhiqi Kang, Rahaf Aljundi, Vaggelis Dorovatas, Karteek Alahari
分类: cs.CV
发布日期: 2025-10-20
💡 一句话要点
提出在线上下文蒸馏方法,提升低资源视觉语言模型性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视觉语言模型 上下文学习 知识蒸馏 低资源学习 在线学习
📋 核心要点
- 大型视觉语言模型部署成本高,小型模型性能不足,需要高效的低资源适应方法。
- 提出在线上下文蒸馏方法,利用大型教师模型在推理时指导小型学生模型,提升性能。
- 实验表明,该方法使用少量教师标注即可显著提升小型模型性能,接近教师模型的零样本水平。
📝 摘要(中文)
本文关注如何在低资源、预算受限的环境中应用视觉语言模型(VLM)。大型VLM性能强大,但部署成本高昂。小型VLM效率高,但性能与大型模型差距明显,通常需要昂贵的微调。受上下文学习启发,我们提出一种在线上下文蒸馏(ICD)方法,在推理时,小型VLM与更强大的教师模型协作,通过稀疏的示例来提炼知识,从而有效地弥合两者之间的差距。我们深入分析了视觉语言上下文学习的可行模型规模和选择,并证明了在有限的计算预算下,上下文学习优于微调。我们通过新颖的跨模态示例选择策略、教师测试时缩放以减少噪声以及学生不确定性条件来动态填充示例池并最小化教师查询,从而增强了我们的方法。我们的ICD方法使用稀缺的教师标注(低至4%)显著提高了小型模型的性能(高达33%),并且可以与教师模型的零样本性能相媲美。
🔬 方法详解
问题定义:论文旨在解决低资源场景下视觉语言模型(VLM)的性能瓶颈问题。现有方法要么依赖于计算资源庞大的大型VLM,要么需要对小型VLM进行昂贵的微调,这在资源受限的环境中是不可行的。因此,如何在有限的计算预算下,提升小型VLM的性能,使其能够媲美甚至超越大型VLM的零样本性能,是本文要解决的核心问题。
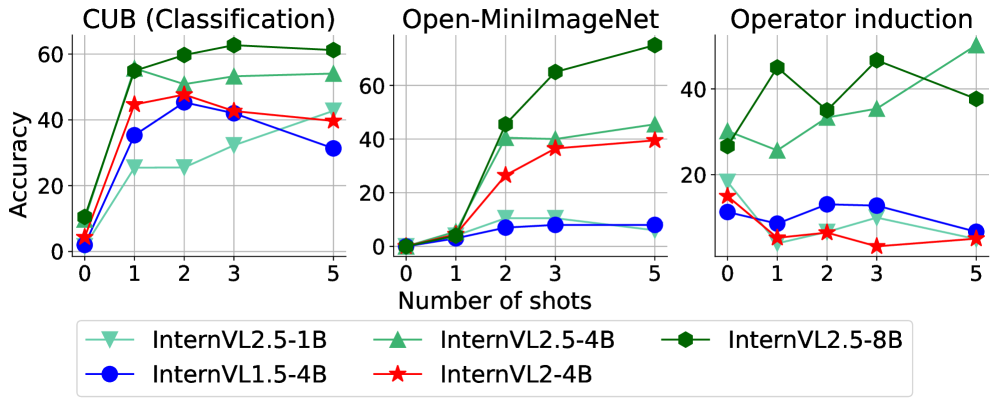
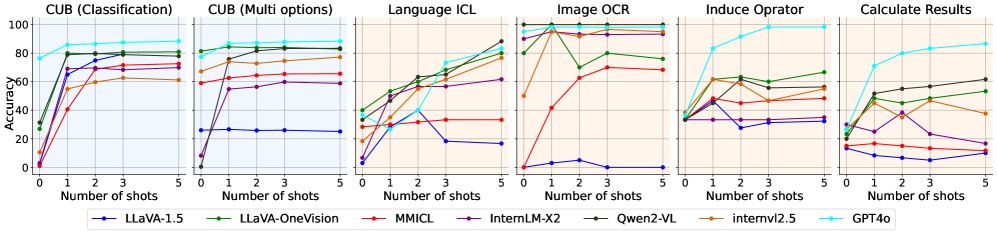
核心思路:论文的核心思路是利用上下文学习(In-Context Learning, ICL)的思想,在推理阶段,让小型VLM(学生模型)通过与大型VLM(教师模型)的交互,动态地学习和提炼知识。通过教师模型提供的少量示例,学生模型可以更好地理解任务,从而提升性能。这种在线蒸馏的方式避免了昂贵的离线微调,并且能够适应不同的任务和数据分布。
技术框架:该方法的核心是In-Context Distillation (ICD) 框架,主要包含以下几个模块:1) 跨模态示例选择:从少量标注数据中选择最具代表性的示例,用于构建上下文。2) 教师测试时缩放:对教师模型的输出进行缩放,以减少噪声,提高知识提炼的质量。3) 学生不确定性条件:根据学生模型的不确定性,动态地更新示例池,并决定是否需要向教师模型查询新的示例。整体流程是,给定一个输入,首先根据学生模型的不确定性判断是否需要更新示例池。如果需要,则向教师模型查询新的示例,并更新示例池。然后,利用示例池中的示例构建上下文,输入到学生模型中进行推理。
关键创新:该方法的主要创新在于将上下文学习与知识蒸馏相结合,提出了一种在线的知识提炼方法。与传统的离线蒸馏方法相比,该方法不需要预先训练好的教师模型,而是可以在推理时动态地利用教师模型的知识。此外,该方法还提出了新颖的跨模态示例选择策略和教师测试时缩放方法,进一步提高了知识提炼的效率和质量。
关键设计:在跨模态示例选择方面,论文设计了一种基于互信息的选择策略,选择与当前输入最相关的示例。在教师测试时缩放方面,论文采用了一种基于温度的缩放方法,通过调整温度参数来控制教师模型输出的置信度。在学生不确定性条件方面,论文采用了一种基于熵的不确定性度量方法,根据学生模型输出的熵值来判断是否需要更新示例池。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在多个视觉语言任务上取得了显著的性能提升。例如,在使用仅4%的教师标注数据的情况下,小型模型的性能提升高达33%,并且可以与教师模型的零样本性能相媲美。此外,该方法在计算预算受限的情况下,优于传统的微调方法,证明了其在低资源场景下的有效性。
🎯 应用场景
该研究成果可广泛应用于资源受限的视觉语言任务中,例如移动设备上的图像识别、机器人导航、智能助手等。通过利用大型模型的知识,小型模型可以在无需大量计算资源的情况下实现高性能,从而降低部署成本,加速视觉语言技术的普及。未来,该方法还可以扩展到其他模态和任务中,例如语音识别、自然语言处理等。
📄 摘要(原文)
As the field continues its push for ever more resources, this work turns the spotlight on a critical question: how can vision-language models (VLMs) be adapted to thrive in low-resource, budget-constrained settings? While large VLMs offer strong performance, they are impractical to deploy in such settings. Small VLMs, on the other hand, are efficient but typically require costly fine-tuning to close the performance gap with larger models in the deployment domain. Inspired by the in-context learning framework, we propose an online In-Context Distillation (ICD) method, in which a small VLM collaborates with a stronger teacher model at inference time, distilling its knowledge via sparse demonstrations to efficiently bridge the gap between them. Our method is built on an in-depth analysis that identifies the scale and the choice of models for which vision-language ICL is currently feasible, and demonstrates the advantage of ICL over fine-tuning under constrained compute budgets. We enhance our method with a novel cross-modal demonstration selection strategy, teacher test-time scaling to reduce noise, and student uncertainty conditioning to dynamically populate a demonstration pool and minimize teacher queries. Our ICD method significantly boosts the performance of small models (up to 33%) using scarce teacher annotations (as low as 4%), and competes with the teacher's zero-shot performance.