ViBED-Net: Video Based Engagement Detection Network Using Face-Aware and Scene-Aware Spatiotemporal Cues
作者: Prateek Gothwal, Deeptimaan Banerjee, Ashis Kumer Biswas
分类: cs.CV, cs.LG
发布日期: 2025-10-20 (更新: 2025-10-24)
备注: 10 pages, 4 figures, 2 tables
🔗 代码/项目: GITHUB
💡 一句话要点
ViBED-Net:利用面部感知和场景感知的时空线索进行视频参与度检测
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 参与度检测 视频分析 深度学习 时空特征 双流网络
📋 核心要点
- 在线学习环境中,参与度检测对于提升学生学习效果和个性化教学至关重要,但现有方法难以有效融合面部表情和场景上下文信息。
- ViBED-Net采用双流架构,分别处理面部裁剪和完整视频帧,提取时空特征,并使用LSTM和Transformer进行时间建模,从而有效融合多模态信息。
- 在DAiSEE数据集上的实验表明,ViBED-Net优于现有方法,其中LSTM变体达到了73.43%的准确率,证明了该方法的有效性。
📝 摘要(中文)
本文提出了一种新颖的深度学习框架ViBED-Net(Video-Based Engagement Detection Network),旨在从视频数据中评估学生的参与度,采用双流架构。ViBED-Net通过EfficientNetV2处理面部裁剪和完整视频帧,以提取空间特征,从而捕获面部表情和完整场景上下文。然后,使用两种时间建模策略:长短期记忆(LSTM)网络和Transformer编码器,对这些特征进行时间分析。该模型在DAiSEE数据集上进行了评估,这是一个用于电子学习中情感状态识别的大规模基准。为了提高在代表性不足的参与度类别上的性能,我们应用了有针对性的数据增强技术。在测试的变体中,带有LSTM的ViBED-Net达到了73.43%的准确率,优于现有的最先进方法。ViBED-Net表明,结合面部感知和场景感知的时空线索可以显着提高参与度检测的准确性。其模块化设计使其可以灵活地应用于教育、用户体验研究和内容个性化。这项工作通过为实际参与度分析提供可扩展的高性能解决方案,从而推进了基于视频的情感计算。该项目的源代码可在https://github.com/prateek-gothwal/ViBED-Net上找到。
🔬 方法详解
问题定义:论文旨在解决在线学习场景中,如何准确检测学生参与度的问题。现有方法通常只关注面部表情或场景信息,缺乏对二者的有效融合,导致检测精度不高,难以适应复杂多变的课堂环境。
核心思路:论文的核心思路是同时利用面部感知和场景感知的时空线索,通过双流网络分别提取面部和场景特征,然后进行融合和时间建模,从而更全面地捕捉学生的参与状态。这种设计能够弥补单一模态信息的不足,提高检测的鲁棒性和准确性。
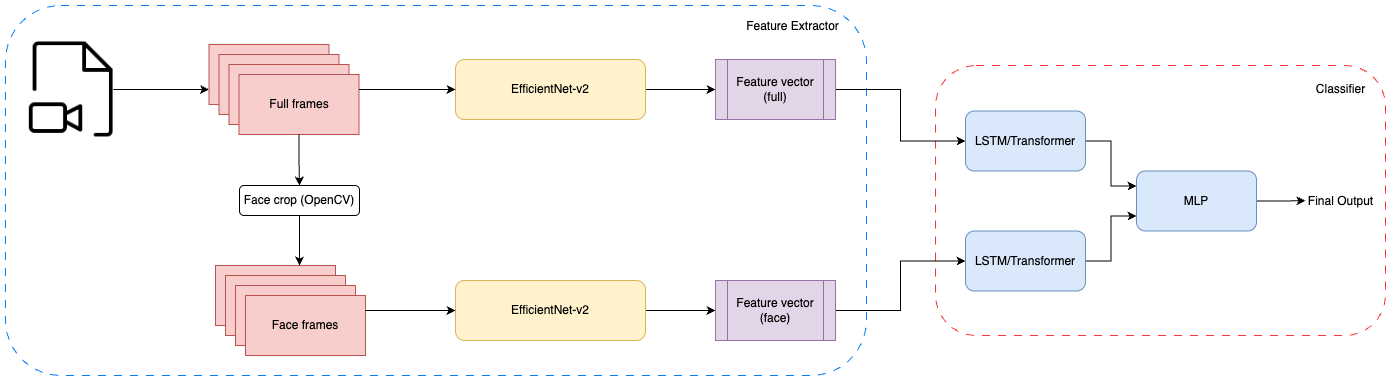
技术框架:ViBED-Net采用双流架构。首先,使用EfficientNetV2作为空间特征提取器,分别处理面部裁剪图像和完整视频帧。然后,将提取的空间特征输入到两个独立的时间建模模块中,分别使用LSTM网络和Transformer编码器进行时间序列分析。最后,将两个时间建模模块的输出进行融合,得到最终的参与度预测结果。
关键创新:论文的关键创新在于双流架构的设计,以及对LSTM和Transformer两种时间建模方法的对比研究。通过同时考虑面部和场景信息,并探索不同的时间建模策略,ViBED-Net能够更有效地捕捉学生的参与状态。此外,论文还针对数据集中存在的类别不平衡问题,采用了数据增强技术,进一步提升了模型的性能。
关键设计:在空间特征提取方面,选择了EfficientNetV2,因为它在计算效率和特征表达能力之间取得了较好的平衡。在时间建模方面,分别尝试了LSTM和Transformer,并发现LSTM在DAiSEE数据集上表现更好。此外,论文还采用了数据增强技术,对代表性不足的类别进行过采样,以缓解类别不平衡问题。具体的损失函数使用了交叉熵损失函数。
🖼️ 关键图片

📊 实验亮点
ViBED-Net在DAiSEE数据集上取得了显著的性能提升,其中LSTM变体达到了73.43%的准确率,超过了现有的state-of-the-art方法。实验结果表明,结合面部感知和场景感知的时空线索能够有效提高参与度检测的准确性。此外,数据增强技术也对提升模型在代表性不足类别上的性能起到了积极作用。
🎯 应用场景
ViBED-Net可应用于在线教育平台,实时监测学生的参与度,为教师提供反馈,以便调整教学策略。此外,该技术还可用于用户体验研究,分析用户在使用产品或服务时的参与程度,从而优化产品设计。未来,该技术有望应用于内容个性化推荐,根据用户的参与度,推荐更符合其兴趣的内容。
📄 摘要(原文)
Engagement detection in online learning environments is vital for improving student outcomes and personalizing instruction. We present ViBED-Net (Video-Based Engagement Detection Network), a novel deep learning framework designed to assess student engagement from video data using a dual-stream architecture. ViBED-Net captures both facial expressions and full-scene context by processing facial crops and entire video frames through EfficientNetV2 for spatial feature extraction. These features are then analyzed over time using two temporal modeling strategies: Long Short-Term Memory (LSTM) networks and Transformer encoders. Our model is evaluated on the DAiSEE dataset, a large-scale benchmark for affective state recognition in e-learning. To enhance performance on underrepresented engagement classes, we apply targeted data augmentation techniques. Among the tested variants, ViBED-Net with LSTM achieves 73.43\% accuracy, outperforming existing state-of-the-art approaches. ViBED-Net demonstrates that combining face-aware and scene-aware spatiotemporal cues significantly improves engagement detection accuracy. Its modular design allows flexibility for application across education, user experience research, and content personalization. This work advances video-based affective computing by offering a scalable, high-performing solution for real-world engagement analysis. The source code for this project is available on https://github.com/prateek-gothwal/ViBED-Net .