ManzaiSet: A Multimodal Dataset of Viewer Responses to Japanese Manzai Comedy
作者: Kazuki Kawamura, Kengo Nakai, Jun Rekimoto
分类: cs.CV, cs.MM
发布日期: 2025-10-20
备注: ICCV 2025 Workshop on Affective & Behavior Analysis in-the-Wild (ABAW), Honolulu, HI, USA (Oct 19, 2025, HST). 11 pages, 5 figures
期刊: ICCV 2025 Workshops (ICCVW) / CVF Open Access
💡 一句话要点
提出ManzaiSet:一个用于研究观众对日本漫才反应的大规模多模态数据集
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 情感计算 多模态数据集 日本漫才 观众反应 文化差异
📋 核心要点
- 现有情感计算研究存在以西方文化为中心的偏见,缺乏针对非西方文化背景下情感反应的数据集。
- ManzaiSet数据集通过记录观众观看日本漫才时的面部视频和音频,捕捉了观众的情感反应,填补了这一空白。
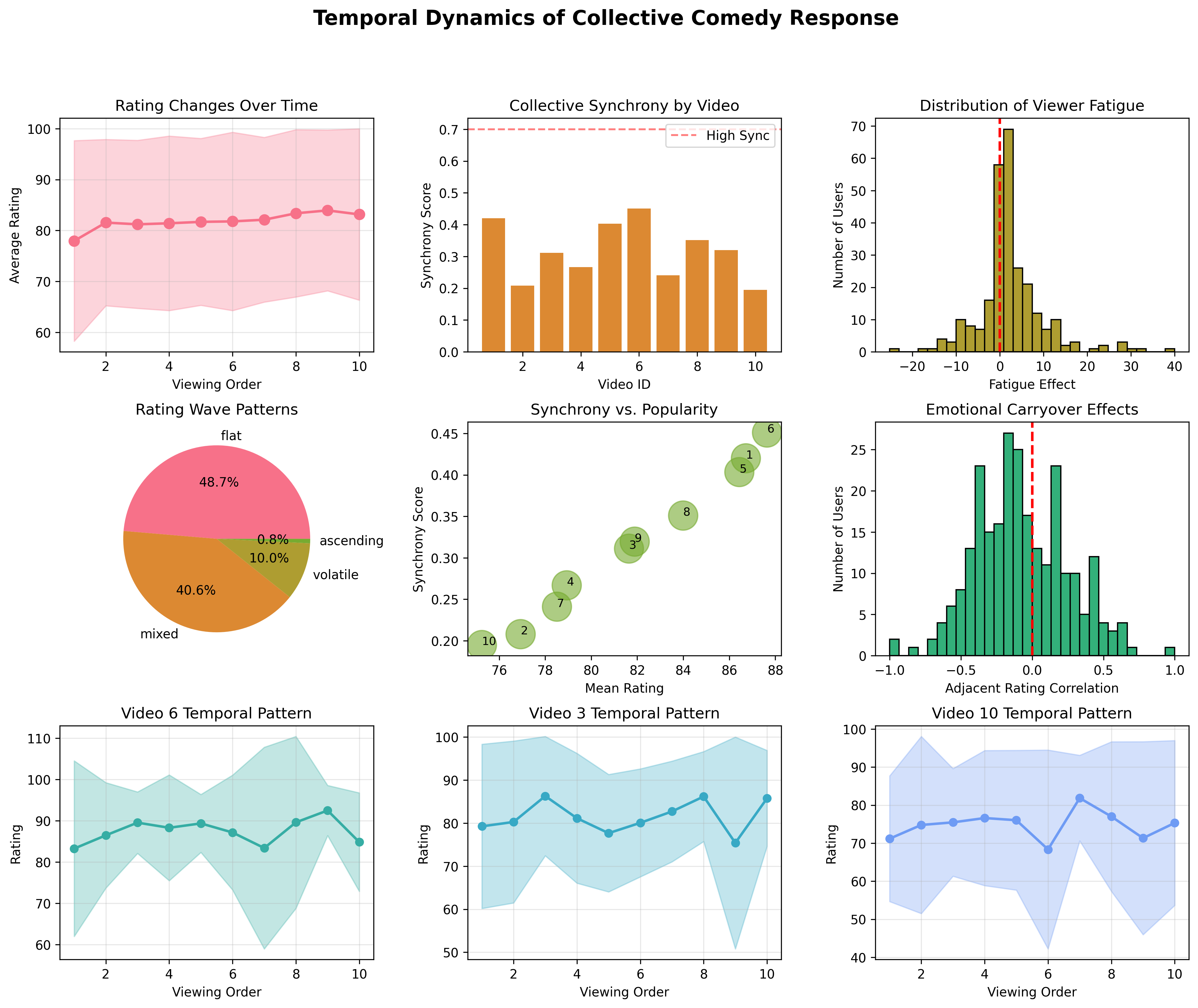
- 实验结果表明,观众存在三种不同的类型,且观看顺序对观众的反应有积极影响,这为个性化娱乐系统提供了依据。
📝 摘要(中文)
本文介绍了ManzaiSet,这是首个大规模多模态数据集,旨在研究观众对日本漫才喜剧的反应。该数据集记录了241名参与者观看多达10场专业漫才表演时的面部视频和音频(94.6%的参与者观看了至少8场;分析集中在n=228)。该数据集旨在解决情感计算中以西方为中心的偏见。研究发现了三个关键结果:(1) k均值聚类识别出三种不同的观众类型:高且稳定的欣赏者(72.8%,n=166)、低且多变的衰退者(13.2%,n=30)和多变的进步者(14.0%,n=32),且方差存在异质性(Brown Forsythe p < 0.001);(2) 个人层面的分析揭示了积极的观看顺序效应(平均斜率=0.488,t(227)=5.42,p < 0.001,置换检验p < 0.001),这与疲劳假设相矛盾;(3) 自动幽默分类(77个实例,131个标签)加上观众层面的反应建模发现,经过FDR校正后,不同类型之间没有差异。该数据集有助于开发具有文化意识的情感AI和为非西方环境量身定制的个性化娱乐系统。
🔬 方法详解
问题定义:现有情感计算数据集主要集中在西方文化背景下,缺乏对非西方文化,例如日本漫才这种喜剧形式的情感反应研究。这限制了情感AI在非西方文化环境中的应用,也难以开发针对特定文化背景的个性化娱乐系统。现有方法难以捕捉到不同文化背景下情感表达的细微差别。
核心思路:该论文的核心思路是通过构建一个大规模的多模态数据集,记录观众在观看日本漫才时的面部视频和音频,从而捕捉观众的情感反应。通过分析这些数据,可以了解不同观众类型的情感表达模式,以及观看顺序对情感反应的影响。这种方法旨在弥补现有情感计算研究中以西方为中心的偏见,并为开发具有文化意识的情感AI提供数据支持。
技术框架:ManzaiSet数据集的构建流程主要包括以下几个阶段: 1. 招募参与者:招募了241名参与者观看漫才表演。 2. 观看漫才:参与者观看多达10场专业漫才表演,观看顺序随机。 3. 数据采集:在观看过程中,记录参与者的面部视频和音频数据。 4. 数据分析:使用k均值聚类分析观众类型,并进行个体层面的分析,研究观看顺序的影响。 5. 自动幽默分类:对漫才表演进行自动幽默分类,并结合观众反应进行建模。
关键创新:该论文的关键创新在于构建了首个大规模的日本漫才观众反应多模态数据集ManzaiSet。该数据集的构建填补了情感计算领域在非西方文化背景下的数据空白,为研究不同文化背景下的情感表达提供了宝贵的数据资源。此外,该研究还发现了观众类型和观看顺序对情感反应的影响,为个性化娱乐系统的开发提供了新的思路。
关键设计:在数据采集方面,论文记录了参与者的面部视频和音频数据,以捕捉观众的情感反应。在数据分析方面,论文使用了k均值聚类算法对观众进行分类,并进行了个体层面的分析,研究观看顺序的影响。此外,论文还使用了自动幽默分类技术,对漫才表演进行分析,并结合观众反应进行建模。具体参数设置和网络结构等技术细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用k均值聚类可以将观众分为三种类型:高且稳定的欣赏者(72.8%)、低且多变的衰退者(13.2%)和多变的进步者(14.0%)。个体层面的分析揭示了积极的观看顺序效应(平均斜率=0.488,t(227)=5.42,p < 0.001,置换检验p < 0.001),这与疲劳假设相矛盾。自动幽默分类加上观众层面的反应建模发现,经过FDR校正后,不同类型之间没有显著差异。
🎯 应用场景
该研究成果可应用于开发具有文化意识的情感AI系统,例如个性化推荐系统,可以根据用户的文化背景和情感偏好,推荐更符合用户口味的娱乐内容。此外,该数据集还可以用于研究不同文化背景下的情感表达差异,为跨文化交流和理解提供支持。未来,该研究可以扩展到其他非西方文化背景下的情感计算研究。
📄 摘要(原文)
We present ManzaiSet, the first large scale multimodal dataset of viewer responses to Japanese manzai comedy, capturing facial videos and audio from 241 participants watching up to 10 professional performances in randomized order (94.6 percent watched >= 8; analyses focus on n=228). This addresses the Western centric bias in affective computing. Three key findings emerge: (1) k means clustering identified three distinct viewer types: High and Stable Appreciators (72.8 percent, n=166), Low and Variable Decliners (13.2 percent, n=30), and Variable Improvers (14.0 percent, n=32), with heterogeneity of variance (Brown Forsythe p < 0.001); (2) individual level analysis revealed a positive viewing order effect (mean slope = 0.488, t(227) = 5.42, p < 0.001, permutation p < 0.001), contradicting fatigue hypotheses; (3) automated humor classification (77 instances, 131 labels) plus viewer level response modeling found no type wise differences after FDR correction. The dataset enables culturally aware emotion AI development and personalized entertainment systems tailored to non Western contexts.