ConsistEdit: Highly Consistent and Precise Training-free Visual Editing
作者: Zixin Yin, Ling-Hao Chen, Lionel Ni, Xili Dai
分类: cs.CV
发布日期: 2025-10-20
备注: SIGGRAPH Asia 2025
💡 一句话要点
ConsistEdit:提出一种高一致性和精确度的免训练视觉编辑方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 图像编辑 视频编辑 注意力控制 MM-DiT 一致性编辑
📋 核心要点
- 现有免训练编辑方法难以兼顾编辑强度和与原始图像的一致性,尤其在多轮和视频编辑中问题突出。
- ConsistEdit通过纯视觉注意力控制、掩码引导的预注意力融合以及差异化token操作,实现一致且prompt对齐的编辑。
- 实验表明,ConsistEdit在图像和视频编辑任务中达到SOTA,支持多轮、多区域编辑,并可渐进式调整结构一致性。
📝 摘要(中文)
现有免训练注意力控制方法虽然能够对生成模型进行灵活高效的文本引导编辑,但难以同时保证编辑强度和与原始图像的一致性。这种局限在多轮和视频编辑中尤为突出,视觉误差会随时间累积。此外,现有方法通常强制全局一致性,限制了其修改纹理等独立属性同时保留其他属性的能力,阻碍了细粒度编辑。MM-DiT架构在生成性能上取得了显著提升,并引入了文本和视觉模态融合的新机制,为克服先前方法的挑战铺平了道路。通过深入分析MM-DiT,我们发现了其注意力机制的三个关键点。基于此,我们提出ConsistEdit,一种专为MM-DiT量身定制的注意力控制方法。ConsistEdit结合了纯视觉注意力控制、掩码引导的预注意力融合以及对查询、键和值token的差异化操作,以产生一致且与prompt对齐的编辑结果。大量实验表明,ConsistEdit在各种图像和视频编辑任务中都达到了最先进的性能,包括结构一致和结构不一致的场景。与先前的方法不同,它是第一个在所有推理步骤和注意力层中执行编辑而无需手工设计的方法,显著提高了可靠性和一致性,从而实现了鲁棒的多轮和多区域编辑。此外,它还支持结构一致性的渐进式调整,从而实现更精细的控制。
🔬 方法详解
问题定义:现有基于注意力控制的免训练图像编辑方法,在保证编辑效果的同时,难以维持与原始图像的高度一致性,尤其是在需要进行多轮编辑或视频编辑时,误差会逐渐累积。此外,现有方法通常采用全局一致性约束,限制了对图像局部属性(如纹理)的精细控制。
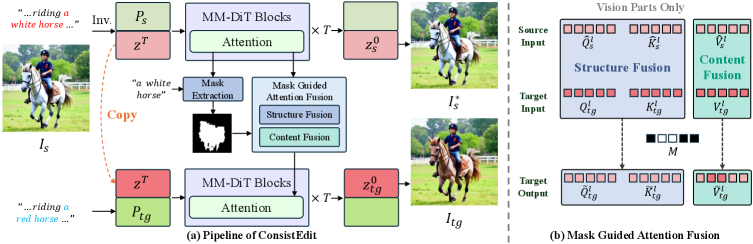
核心思路:ConsistEdit的核心思路是针对MM-DiT架构的特性,设计一种新的注意力控制方法,在编辑过程中更精确地控制视觉信息流,从而在实现所需编辑效果的同时,最大程度地保留原始图像的结构和内容一致性。该方法通过差异化地处理查询(Query)、键(Key)和值(Value)token,以及引入视觉注意力控制和掩码引导的预注意力融合,来实现更精细的控制。
技术框架:ConsistEdit方法主要基于MM-DiT架构,并在其注意力机制上进行改进。整体流程包括:1) 输入原始图像和文本prompt;2) 使用掩码引导的预注意力融合,将文本信息融入到视觉特征中;3) 在MM-DiT的各个Transformer层中,使用差异化的Query、Key和Value token操作,以及视觉注意力控制,进行特征更新;4) 最终生成编辑后的图像。
关键创新:ConsistEdit的关键创新在于其针对MM-DiT架构设计的注意力控制策略,包括:1) 纯视觉注意力控制,用于增强视觉特征的一致性;2) 掩码引导的预注意力融合,用于更精确地将文本信息融入到需要编辑的区域;3) 差异化的Query、Key和Value token操作,用于更灵活地控制编辑强度和一致性。与现有方法相比,ConsistEdit无需手工设计,可在所有推理步骤和注意力层中进行编辑。
关键设计:ConsistEdit的关键设计包括:1) 掩码的生成方式,用于指导预注意力融合和视觉注意力控制;2) Query、Key和Value token操作的具体方式,例如,可以通过调整它们的权重或添加噪声来实现不同的编辑效果;3) 视觉注意力控制的强度,可以通过调整注意力权重来实现对视觉特征一致性的控制。论文中可能还涉及到一些超参数的设置,例如学习率、batch size等,这些参数的选择也会影响最终的编辑效果。
🖼️ 关键图片


📊 实验亮点
实验结果表明,ConsistEdit在图像和视频编辑任务中均取得了SOTA性能。与现有方法相比,ConsistEdit在保持图像一致性方面有显著提升,尤其是在多轮编辑和视频编辑中,能够有效避免误差累积。此外,ConsistEdit还支持对图像结构一致性的渐进式调整,提供了更精细的编辑控制能力。具体性能数据和对比基线在论文的实验部分有详细展示。
🎯 应用场景
ConsistEdit在图像和视频编辑领域具有广泛的应用前景,例如艺术创作、内容生成、图像修复、视频特效等。该方法能够实现对图像和视频内容进行精确且一致的编辑,可以用于生成高质量的视觉内容,提升用户体验,并为相关产业带来新的发展机遇。未来,该方法还可以应用于更复杂的场景,例如三维场景编辑、交互式编辑等。
📄 摘要(原文)
Recent advances in training-free attention control methods have enabled flexible and efficient text-guided editing capabilities for existing generation models. However, current approaches struggle to simultaneously deliver strong editing strength while preserving consistency with the source. This limitation becomes particularly critical in multi-round and video editing, where visual errors can accumulate over time. Moreover, most existing methods enforce global consistency, which limits their ability to modify individual attributes such as texture while preserving others, thereby hindering fine-grained editing. Recently, the architectural shift from U-Net to MM-DiT has brought significant improvements in generative performance and introduced a novel mechanism for integrating text and vision modalities. These advancements pave the way for overcoming challenges that previous methods failed to resolve. Through an in-depth analysis of MM-DiT, we identify three key insights into its attention mechanisms. Building on these, we propose ConsistEdit, a novel attention control method specifically tailored for MM-DiT. ConsistEdit incorporates vision-only attention control, mask-guided pre-attention fusion, and differentiated manipulation of the query, key, and value tokens to produce consistent, prompt-aligned edits. Extensive experiments demonstrate that ConsistEdit achieves state-of-the-art performance across a wide range of image and video editing tasks, including both structure-consistent and structure-inconsistent scenarios. Unlike prior methods, it is the first approach to perform editing across all inference steps and attention layers without handcraft, significantly enhancing reliability and consistency, which enables robust multi-round and multi-region editing. Furthermore, it supports progressive adjustment of structural consistency, enabling finer control.