MT-Video-Bench: A Holistic Video Understanding Benchmark for Evaluating Multimodal LLMs in Multi-Turn Dialogues
作者: Yaning Pan, Qianqian Xie, Guohui Zhang, Zekun Wang, Yongqian Wen, Yuanxing Zhang, Haoxuan Hu, Zhiyu Pan, Yibing Huang, Zhidong Gan, Yonghong Lin, An Ping, Shihao Li, Yanghai Wang, Tianhao Peng, Jiaheng Liu
分类: cs.CV, cs.AI
发布日期: 2025-10-20 (更新: 2026-01-08)
备注: Project Website: https://github.com/NJU-LINK/MT-Video-Bench
💡 一句话要点
提出MT-Video-Bench,用于评估多模态LLM在多轮对话中的视频理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视频理解 多轮对话 大型语言模型 评估基准
📋 核心要点
- 现有视频理解评估基准主要集中于单轮问答,无法充分评估模型在真实场景下多轮交互中的理解能力。
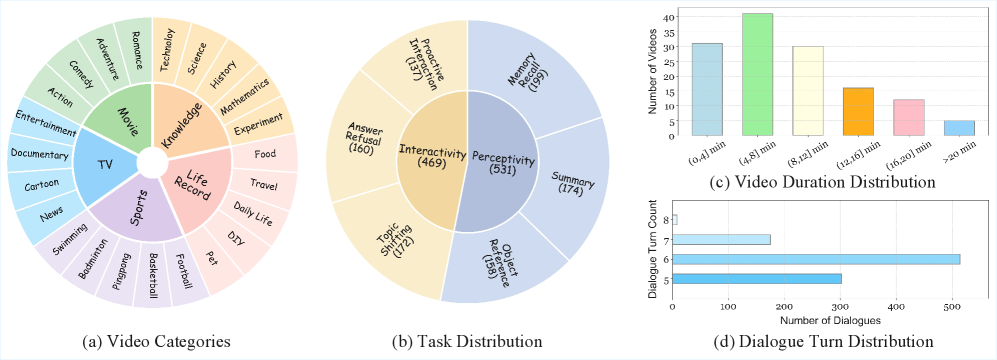
- MT-Video-Bench通过构建包含1000个多轮对话的基准数据集,全面评估MLLM在视频理解中的感知和交互能力。
- 实验结果揭示了现有MLLM在处理多轮视频对话方面的性能差异和局限性,为未来研究提供了方向。
📝 摘要(中文)
多模态大型语言模型(MLLM)的最新发展显著提升了AI理解视觉模态的能力。然而,现有的评估基准仍局限于单轮问答,忽略了真实场景中多轮对话的复杂性。为了弥补这一差距,我们推出了MT-Video-Bench,这是一个用于评估MLLM在多轮对话中视频理解能力的综合性基准。具体来说,MT-Video-Bench主要评估6项核心能力,侧重于感知性和交互性,包含来自不同领域的1000个精心策划的多轮对话。这些能力与实际应用严格对齐,例如交互式体育分析和基于视频的多轮智能辅导。通过MT-Video-Bench,我们广泛评估了各种最先进的开源和闭源MLLM,揭示了它们在处理多轮视频对话方面的显著性能差异和局限性。该基准将公开提供,以促进未来的研究。
🔬 方法详解
问题定义:现有视频理解评估基准主要集中于单轮问答,无法有效评估模型在真实场景下的多轮交互能力。这导致了模型在复杂、动态的视频理解任务中表现不佳,例如需要持续推理和交互的场景。现有方法难以捕捉视频中的时间依赖关系和上下文信息,限制了模型在实际应用中的潜力。
核心思路:MT-Video-Bench的核心思路是构建一个更贴近真实场景的多轮对话数据集,从而更全面地评估MLLM的视频理解能力。通过设计涵盖感知性和交互性的六大核心能力,该基准能够深入分析模型在不同方面的表现,并揭示其潜在的局限性。这种多维度的评估方法有助于推动MLLM在视频理解领域的进一步发展。
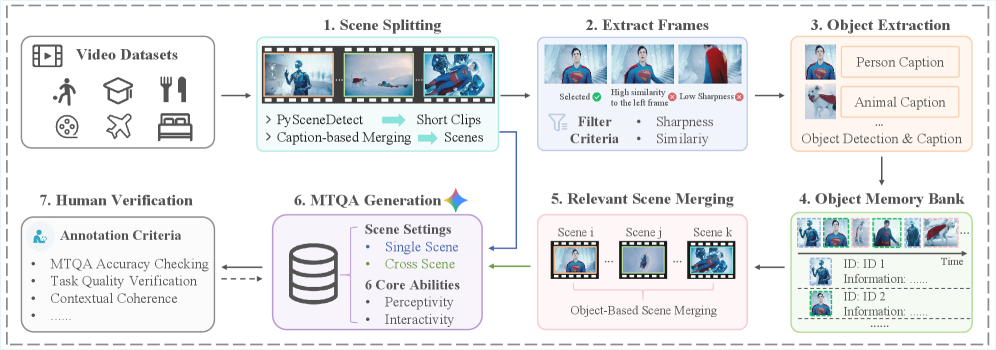
技术框架:MT-Video-Bench的整体框架主要包括数据集构建和模型评估两个阶段。在数据集构建阶段,研究人员精心策划了来自不同领域的1000个多轮对话,涵盖了体育分析、智能辅导等多种实际应用场景。在模型评估阶段,研究人员使用MT-Video-Bench对各种开源和闭源MLLM进行了广泛的评估,并分析了它们在不同能力上的表现。
关键创新:MT-Video-Bench的关键创新在于其多轮对话的评估方式和对核心能力的细致划分。与传统的单轮问答基准相比,MT-Video-Bench能够更真实地反映模型在实际应用中的表现。此外,通过定义感知性和交互性相关的六大核心能力,该基准能够更深入地分析模型的优势和不足,为未来的研究提供更明确的方向。
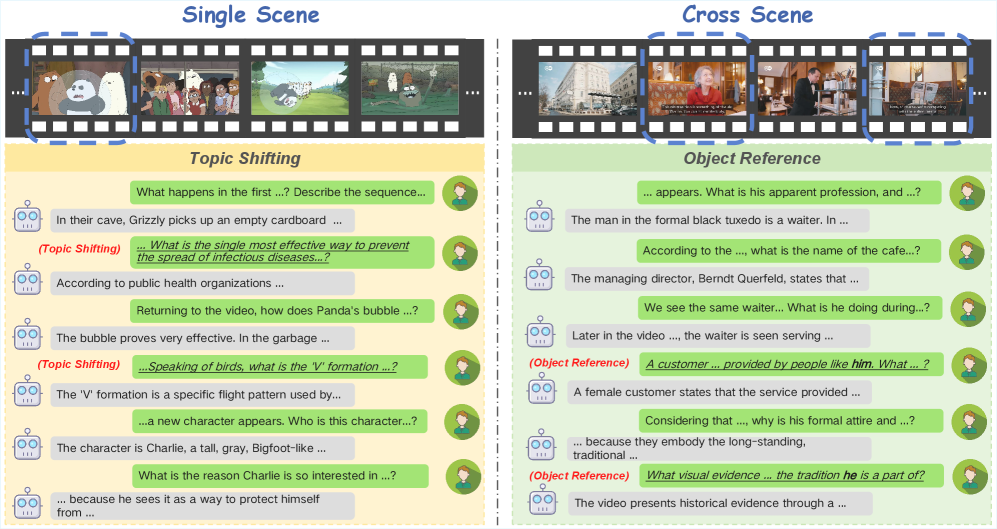
关键设计:MT-Video-Bench的关键设计包括对话轮数的设置、问题类型的选择以及评估指标的定义。对话轮数的设计需要平衡对话的复杂性和评估的效率。问题类型的选择需要涵盖不同的视频理解能力,例如目标识别、事件描述和关系推理。评估指标的定义需要能够准确反映模型在不同能力上的表现,例如准确率、召回率和F1值。
🖼️ 关键图片
📊 实验亮点
MT-Video-Bench对多种最先进的MLLM进行了评估,结果表明,即使是表现最好的模型在处理多轮视频对话时仍然存在显著的局限性。例如,在某些需要复杂推理和交互的场景中,模型的准确率仅为XX%。此外,研究还发现,不同模型在不同能力上的表现存在显著差异,这表明未来的研究需要针对特定能力进行优化。
🎯 应用场景
MT-Video-Bench的研究成果可广泛应用于智能监控、视频搜索、智能教育、人机交互等领域。例如,在智能监控中,可以利用该基准评估MLLM在复杂场景下的视频理解能力,从而提高监控系统的智能化水平。在智能教育中,可以利用该基准评估MLLM在视频辅导方面的表现,从而为学生提供更个性化的学习体验。该研究的未来影响在于推动多模态LLM在视频理解领域的进一步发展,并促进其在实际应用中的广泛应用。
📄 摘要(原文)
The recent development of Multimodal Large Language Models (MLLMs) has significantly advanced AI's ability to understand visual modalities. However, existing evaluation benchmarks remain limited to single-turn question answering, overlooking the complexity of multi-turn dialogues in real-world scenarios. To bridge this gap, we introduce MT-Video-Bench, a holistic video understanding benchmark for evaluating MLLMs in multi-turn dialogues. Specifically, our MT-Video-Bench mainly assesses 6 core competencies that focus on perceptivity and interactivity, encompassing 1,000 meticulously curated multi-turn dialogues from diverse domains. These capabilities are rigorously aligned with real-world applications, such as interactive sports analysis and multi-turn video-based intelligent tutoring. With MT-Video-Bench, we extensively evaluate various state-of-the-art open-source and closed-source MLLMs, revealing their significant performance discrepancies and limitations in handling multi-turn video dialogues. The benchmark will be publicly available to foster future research.