Elastic ViTs from Pretrained Models without Retraining
作者: Walter Simoncini, Michael Dorkenwald, Tijmen Blankevoort, Cees G. M. Snoek, Yuki M. Asano
分类: cs.CV
发布日期: 2025-10-20
备注: Accepted at NeurIPS 2025
💡 一句话要点
提出SnapViT,无需重训练即可从预训练ViT模型中获得弹性推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Vision Transformer 模型剪枝 弹性推理 自监督学习 进化算法 Hessian矩阵 网络压缩
📋 核心要点
- 现有Vision Transformer模型尺寸固定,难以适应不同计算资源约束下的部署需求。
- SnapViT通过结合梯度信息和跨网络结构相关性,实现对预训练ViT模型的单次剪枝,无需重训练。
- 实验表明,SnapViT在多种ViT模型上优于现有剪枝方法,且计算效率高,可在单GPU上快速生成弹性模型。
📝 摘要(中文)
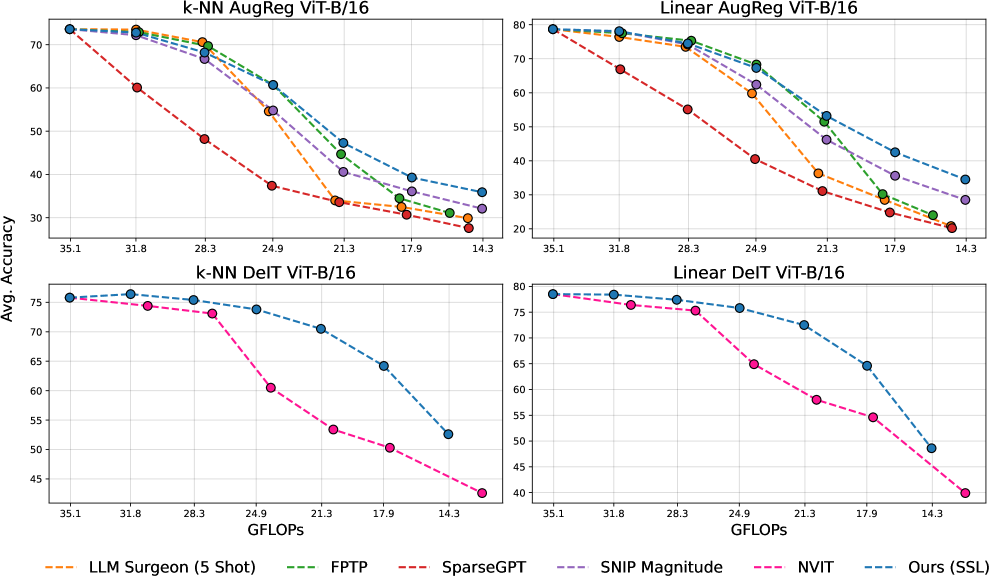
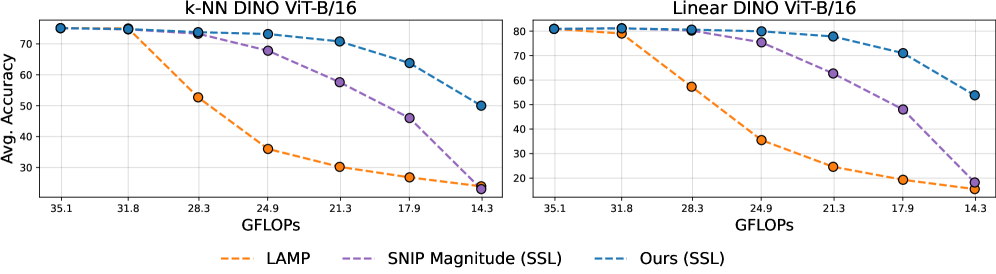
视觉基础模型性能卓越,但仅限于预定义的几种尺寸,在实际部署中存在次优选择。我们提出了SnapViT:用于剪枝Vision Transformer的单次网络近似方法,这是一种新的后预训练结构化剪枝方法,可以在连续的计算预算范围内实现弹性推理。我们的方法有效地结合了梯度信息和跨网络结构相关性(通过进化算法近似),不需要标注数据,可以推广到没有分类头的模型,并且无需重新训练。在DINO、SigLIPv2、DeIT和AugReg模型上的实验表明,在各种稀疏性下,该方法优于最先进的方法,在单个A100 GPU上只需不到五分钟即可生成可调整到任何计算预算的弹性模型。我们的主要贡献包括一种用于预训练Vision Transformer的有效剪枝策略,一种Hessian矩阵非对角结构的进化近似方法,以及一种无需重新训练或标签即可保持强大性能的自监督重要性评分机制。
🔬 方法详解
问题定义:现有Vision Transformer模型通常以固定尺寸进行训练和部署,这限制了它们在不同计算资源约束下的应用。例如,在资源受限的边缘设备上部署大型ViT模型是不切实际的。现有的模型压缩方法,如剪枝和量化,通常需要重新训练模型以恢复性能,这带来了额外的计算成本和时间开销。因此,如何在不重新训练的情况下,从预训练的ViT模型中获得适应不同计算预算的弹性模型是一个关键问题。
核心思路:SnapViT的核心思路是利用单次网络近似(Single-shot network approximation)方法,在预训练的ViT模型上进行结构化剪枝,从而获得可以在不同计算预算下进行弹性推理的模型。该方法通过结合梯度信息和跨网络结构相关性,来确定哪些Transformer块或注意力头可以被安全地移除,而不会显著降低模型性能。关键在于,该方法不需要标注数据,也不需要重新训练模型,从而大大提高了效率。
技术框架:SnapViT的整体框架包括以下几个主要步骤:1) 重要性评分:使用自监督学习方法(如DINO)提取的特征,计算每个Transformer块或注意力头的重要性得分。该得分反映了该模块对模型整体性能的贡献。2) 结构相关性近似:利用进化算法近似Hessian矩阵的非对角结构,从而捕捉不同模块之间的依赖关系。这有助于在剪枝过程中避免移除相互依赖的关键模块。3) 剪枝:根据重要性得分和结构相关性信息,对模型进行结构化剪枝,移除不重要的模块。4) 弹性推理:根据给定的计算预算,选择合适的剪枝比例,从而获得适应不同计算资源的弹性模型。
关键创新:SnapViT的关键创新在于以下几个方面:1) 高效的剪枝策略:该策略结合了梯度信息和跨网络结构相关性,能够在不重新训练的情况下,有效地剪枝预训练的ViT模型。2) Hessian矩阵非对角结构的进化近似:通过进化算法近似Hessian矩阵的非对角结构,能够更准确地捕捉不同模块之间的依赖关系,从而提高剪枝的准确性。3) 自监督重要性评分机制:该机制利用自监督学习方法提取的特征,计算每个模块的重要性得分,无需标注数据。
关键设计:SnapViT的关键设计包括:1) 使用DINO等自监督学习方法提取特征,用于计算模块的重要性得分。2) 使用进化算法(如遗传算法)近似Hessian矩阵的非对角结构。3) 使用结构化剪枝方法,移除整个Transformer块或注意力头,以保证模型的结构规整性。4) 通过调整剪枝比例,实现对不同计算预算的适应性。
🖼️ 关键图片

📊 实验亮点
SnapViT在DINO、SigLIPv2、DeIT和AugReg等多种预训练ViT模型上进行了实验,结果表明,在各种稀疏度下,SnapViT的性能优于现有的剪枝方法。例如,在某些情况下,SnapViT可以在保持相同性能的同时,将模型的计算量减少50%以上。此外,SnapViT的计算效率非常高,在单个A100 GPU上只需不到五分钟即可生成弹性模型。
🎯 应用场景
SnapViT具有广泛的应用前景,尤其是在资源受限的场景下,例如移动设备、嵌入式系统和边缘计算。它可以用于图像分类、目标检测、语义分割等各种视觉任务。通过SnapViT,可以在不牺牲太多性能的情况下,将大型ViT模型部署到这些设备上,从而提高视觉应用的智能化水平。此外,SnapViT还可以用于模型压缩和加速,降低模型的存储空间和计算复杂度。
📄 摘要(原文)
Vision foundation models achieve remarkable performance but are only available in a limited set of pre-determined sizes, forcing sub-optimal deployment choices under real-world constraints. We introduce SnapViT: Single-shot network approximation for pruned Vision Transformers, a new post-pretraining structured pruning method that enables elastic inference across a continuum of compute budgets. Our approach efficiently combines gradient information with cross-network structure correlations, approximated via an evolutionary algorithm, does not require labeled data, generalizes to models without a classification head, and is retraining-free. Experiments on DINO, SigLIPv2, DeIT, and AugReg models demonstrate superior performance over state-of-the-art methods across various sparsities, requiring less than five minutes on a single A100 GPU to generate elastic models that can be adjusted to any computational budget. Our key contributions include an efficient pruning strategy for pretrained Vision Transformers, a novel evolutionary approximation of Hessian off-diagonal structures, and a self-supervised importance scoring mechanism that maintains strong performance without requiring retraining or labels. Code and pruned models are available at: https://elastic.ashita.nl/