ImaGGen: Zero-Shot Generation of Co-Speech Semantic Gestures Grounded in Language and Image Input
作者: Hendric Voss, Stefan Kopp
分类: cs.HC, cs.CV
发布日期: 2025-10-20
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
ImaGGen:提出一种基于语言和图像输入的零样本共语语义手势生成方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 共语手势生成 零样本学习 多模态融合 图像分析 语义匹配
📋 核心要点
- 现有手势生成方法局限于简单的节拍手势,无法表达与语言语义相关的标志性或指示性手势。
- ImaGGen利用图像输入提取视觉信息,并通过语义匹配模块将其与口语文本关联,生成语义一致的手势。
- 用户研究表明,ImaGGen生成的手势在语音模糊时能显著提高对象属性识别率,验证了其有效性。
📝 摘要(中文)
本文提出了一种零样本系统ImaGGen,用于生成与口语表达在语义上一致的标志性或指示性手势。该系统不仅接收语言输入,还接收图像输入,无需手动标注或人工干预。系统集成了图像分析流程,提取形状、对称性和对齐等关键对象属性,以及一个语义匹配模块,将这些视觉细节与口语文本联系起来。然后,逆运动学引擎合成标志性和指示性手势,并将它们与共同生成的自然节拍手势相结合,以实现连贯的多模态交流。用户研究表明,在仅凭语音难以区分语义的情况下,该系统生成的手势显著提高了参与者识别对象属性的能力,证实了其可解释性和交流价值。虽然在表示复杂形状方面仍存在挑战,但该研究强调了上下文感知的语义手势对于创建富有表现力和协作性的虚拟代理或化身的重要性,标志着在高效、稳健的具身人机交互方面迈出了重要一步。
🔬 方法详解
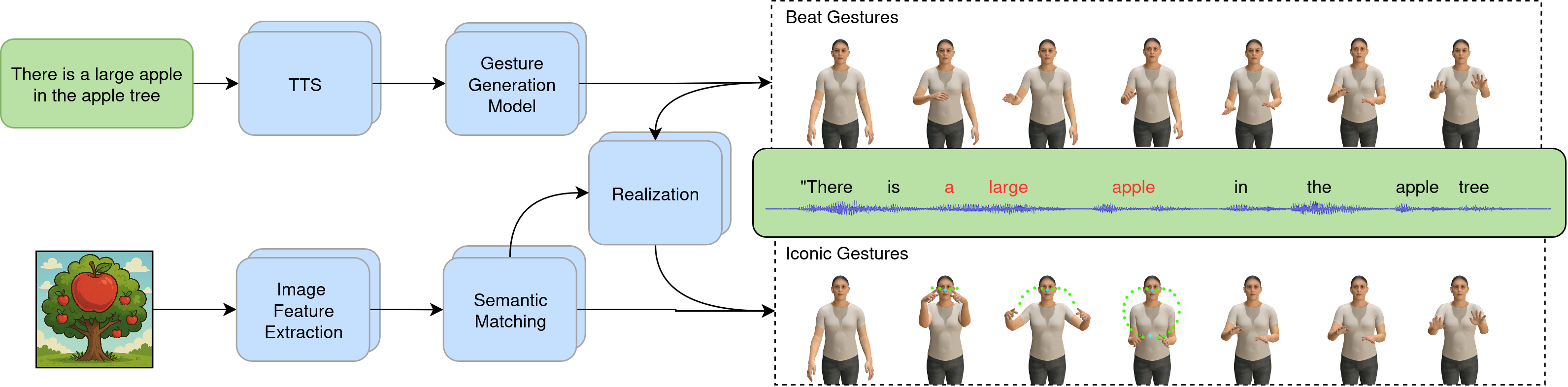
问题定义:现有共语手势生成方法主要生成与语音节奏同步的节拍手势,缺乏与语义相关的标志性或指示性手势。仅依赖语言输入难以生成此类手势,因为语言本身缺乏手势所携带的视觉信息。因此,需要解决如何从多模态输入(语言和图像)中生成语义一致的共语手势的问题。
核心思路:ImaGGen的核心思路是利用图像输入来补充语言输入,提取图像中的视觉信息(如形状、对称性等),并将这些信息与语言输入进行语义匹配,从而生成与语言和图像都相关的语义手势。这种方法无需人工标注,实现了零样本生成。
技术框架:ImaGGen系统包含以下主要模块:1) 图像分析模块:提取输入图像的关键对象属性,如形状、对称性和对齐方式。2) 语义匹配模块:将提取的视觉属性与口语文本进行语义匹配,建立视觉信息与语言信息的关联。3) 手势生成模块:基于语义匹配的结果,利用逆运动学引擎合成标志性和指示性手势,并与共同生成的节拍手势相结合。
关键创新:ImaGGen的关键创新在于其零样本生成能力,即无需任何人工标注或训练数据,即可从语言和图像输入中生成语义一致的共语手势。这与传统的需要大量标注数据的有监督学习方法形成鲜明对比。此外,该系统集成了图像分析和语义匹配模块,实现了视觉信息与语言信息的有效融合。
关键设计:图像分析模块使用预训练的计算机视觉模型(具体模型未知)来提取图像特征。语义匹配模块的设计细节未知,但推测可能使用了某种形式的注意力机制或相似度度量来建立视觉属性与语言信息的关联。手势生成模块使用逆运动学引擎,根据语义匹配的结果生成目标姿态,并与节拍手势进行融合。损失函数和网络结构等细节未知。
🖼️ 关键图片

📊 实验亮点
用户研究表明,在仅凭语音难以区分语义的情况下,ImaGGen生成的手势显著提高了参与者识别对象属性的能力。具体而言,参与者在观看带有ImaGGen生成手势的视频时,识别对象属性的准确率明显高于仅观看语音或带有传统节拍手势的视频。这证实了ImaGGen生成的手势具有可解释性和交流价值。
🎯 应用场景
ImaGGen具有广泛的应用前景,可用于创建更具表现力和协作性的虚拟代理或化身,从而改善人机交互体验。例如,在虚拟会议、在线教育、游戏等领域,ImaGGen可以使虚拟角色能够更自然地与用户进行交流,提高沟通效率和用户满意度。该研究为具身人机交互开辟了新的方向,有望推动相关技术的发展。
📄 摘要(原文)
Human communication combines speech with expressive nonverbal cues such as hand gestures that serve manifold communicative functions. Yet, current generative gesture generation approaches are restricted to simple, repetitive beat gestures that accompany the rhythm of speaking but do not contribute to communicating semantic meaning. This paper tackles a core challenge in co-speech gesture synthesis: generating iconic or deictic gestures that are semantically coherent with a verbal utterance. Such gestures cannot be derived from language input alone, which inherently lacks the visual meaning that is often carried autonomously by gestures. We therefore introduce a zero-shot system that generates gestures from a given language input and additionally is informed by imagistic input, without manual annotation or human intervention. Our method integrates an image analysis pipeline that extracts key object properties such as shape, symmetry, and alignment, together with a semantic matching module that links these visual details to spoken text. An inverse kinematics engine then synthesizes iconic and deictic gestures and combines them with co-generated natural beat gestures for coherent multimodal communication. A comprehensive user study demonstrates the effectiveness of our approach. In scenarios where speech alone was ambiguous, gestures generated by our system significantly improved participants' ability to identify object properties, confirming their interpretability and communicative value. While challenges remain in representing complex shapes, our results highlight the importance of context-aware semantic gestures for creating expressive and collaborative virtual agents or avatars, marking a substantial step forward towards efficient and robust, embodied human-agent interaction. More information and example videos are available here: https://review-anon-io.github.io/ImaGGen.github.io/