ShapeCraft: LLM Agents for Structured, Textured and Interactive 3D Modeling
作者: Shuyuan Zhang, Chenhan Jiang, Zuoou Li, Jiankang Deng
分类: cs.CV
发布日期: 2025-10-20
备注: NeurIPS 2025 Poster
💡 一句话要点
ShapeCraft:利用LLM智能体进行结构化、纹理化和交互式3D建模
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting)
关键词: 文本到3D生成 LLM智能体 程序化建模 图表示学习 3D内容创作
📋 核心要点
- 现有文本到3D生成方法生成的网格结构性差,交互性不足,限制了其在艺术创作中的应用。
- ShapeCraft提出基于图的程序化形状(GPS)表示,并利用多智能体框架迭代优化3D模型,实现结构化建模。
- 实验结果表明,ShapeCraft在几何精度和语义丰富度上优于现有方法,并支持动画和用户自定义编辑。
📝 摘要(中文)
本文提出ShapeCraft,一种新颖的多智能体框架,用于从文本生成3D模型。现有方法生成的网格通常是非结构化的,且交互性差,难以应用于艺术工作流程。ShapeCraft将3D资产表示为形状程序,并引入基于图的程序化形状(GPS)表示,将复杂的自然语言分解为子任务的结构化图,从而促进LLM对空间关系和语义形状细节的准确理解和解释。LLM智能体分层解析用户输入以初始化GPS,然后迭代地细化程序建模和绘制,以生成结构化、纹理化和交互式的3D资产。定性和定量实验表明,与现有的基于LLM的智能体相比,ShapeCraft在生成几何精确和语义丰富的3D资产方面表现出优越的性能。通过动画和用户自定义编辑的例子,进一步展示了ShapeCraft的多功能性,突出了其在更广泛的交互式应用中的潜力。
🔬 方法详解
问题定义:现有文本到3D生成方法主要存在两个痛点:一是生成的3D网格通常是非结构化的,难以进行后续编辑和动画制作;二是交互性差,用户难以对生成的3D模型进行精细调整和个性化定制。这些问题限制了文本到3D生成技术在艺术创作和交互式应用中的广泛应用。
核心思路:ShapeCraft的核心思路是将3D模型表示为“形状程序”,即一系列可执行的建模指令。通过将复杂的自然语言描述分解为结构化的子任务图(GPS),利用LLM智能体逐步执行这些指令,从而生成结构化的、可交互的3D模型。这种方法借鉴了程序化建模的思想,使得生成的模型具有良好的可控性和可编辑性。
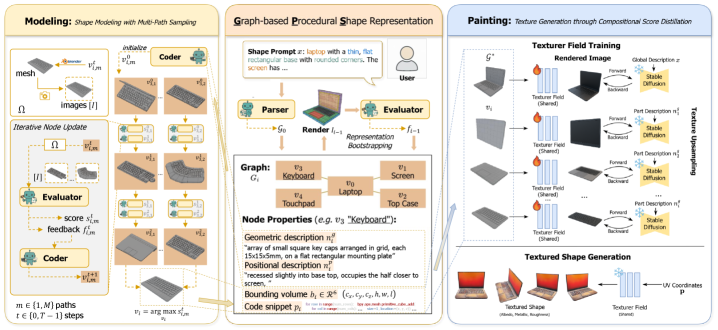
技术框架:ShapeCraft框架包含以下主要模块:1) GPS初始化:LLM智能体解析用户输入的文本描述,将其分解为子任务图(GPS),每个节点代表一个建模操作,边表示操作之间的依赖关系。2) 程序建模:LLM智能体根据GPS中的指令,逐步执行建模操作,生成3D模型的几何结构。3) 纹理绘制:LLM智能体根据文本描述,为3D模型添加纹理和颜色。4) 迭代优化:通过用户反馈或自动评估指标,LLM智能体不断优化GPS和建模参数,提高生成模型的质量。
关键创新:ShapeCraft的关键创新在于提出了基于图的程序化形状(GPS)表示。GPS将复杂的文本描述分解为结构化的子任务图,使得LLM能够更好地理解和执行建模指令。与直接生成网格的方法相比,GPS能够生成结构化的、可编辑的3D模型,并支持交互式编辑和动画制作。
关键设计:GPS的节点表示建模操作,例如拉伸、旋转、缩放等。边表示操作之间的依赖关系,例如父子关系、顺序关系等。LLM智能体使用Transformer架构,并经过微调,以更好地理解和执行建模指令。损失函数包括几何损失、纹理损失和语义损失,用于评估生成模型的质量。
🖼️ 关键图片

📊 实验亮点
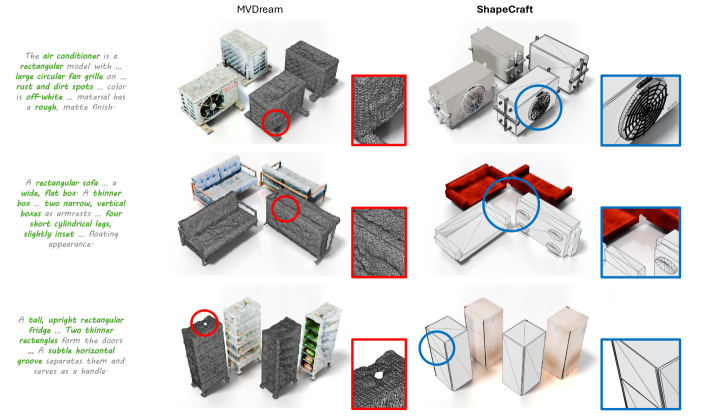
实验结果表明,ShapeCraft在生成几何精确和语义丰富的3D资产方面优于现有的基于LLM的智能体。定性结果显示,ShapeCraft能够生成更符合文本描述的3D模型,并且具有更好的结构性和可编辑性。定量评估(具体指标未知)也证实了ShapeCraft的优越性能。此外,ShapeCraft还展示了在动画和用户自定义编辑方面的潜力。
🎯 应用场景
ShapeCraft在游戏开发、动画制作、工业设计、建筑设计等领域具有广泛的应用前景。它可以帮助设计师快速生成3D模型,提高工作效率。同时,ShapeCraft的交互式编辑功能使得用户可以轻松地定制3D模型,满足个性化需求。未来,ShapeCraft有望成为3D内容创作的重要工具,推动3D技术的普及和发展。
📄 摘要(原文)
3D generation from natural language offers significant potential to reduce expert manual modeling efforts and enhance accessibility to 3D assets. However, existing methods often yield unstructured meshes and exhibit poor interactivity, making them impractical for artistic workflows. To address these limitations, we represent 3D assets as shape programs and introduce ShapeCraft, a novel multi-agent framework for text-to-3D generation. At its core, we propose a Graph-based Procedural Shape (GPS) representation that decomposes complex natural language into a structured graph of sub-tasks, thereby facilitating accurate LLM comprehension and interpretation of spatial relationships and semantic shape details. Specifically, LLM agents hierarchically parse user input to initialize GPS, then iteratively refine procedural modeling and painting to produce structured, textured, and interactive 3D assets. Qualitative and quantitative experiments demonstrate ShapeCraft's superior performance in generating geometrically accurate and semantically rich 3D assets compared to existing LLM-based agents. We further show the versatility of ShapeCraft through examples of animated and user-customized editing, highlighting its potential for broader interactive applications.