MUG-V 10B: High-efficiency Training Pipeline for Large Video Generation Models
作者: Yongshun Zhang, Zhongyi Fan, Yonghang Zhang, Zhangzikang Li, Weifeng Chen, Zhongwei Feng, Chaoyue Wang, Peng Hou, Anxiang Zeng
分类: cs.CV, cs.AI
发布日期: 2025-10-20 (更新: 2025-10-22)
备注: Technical Report; Project Page: https://github.com/Shopee-MUG/MUG-V
🔗 代码/项目: GITHUB
💡 一句话要点
MUG-V 10B:面向大规模视频生成模型的高效训练框架
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 视频生成 大规模模型 高效训练 Megatron-Core 电商视频 文本-视频对齐 课程学习 开源
📋 核心要点
- 大规模视频生成模型训练面临跨模态对齐、长序列依赖和时空复杂度等挑战,计算资源需求巨大。
- 论文提出一个四支柱优化的训练框架,涵盖数据处理、模型架构、训练策略和基础设施,提升训练效率。
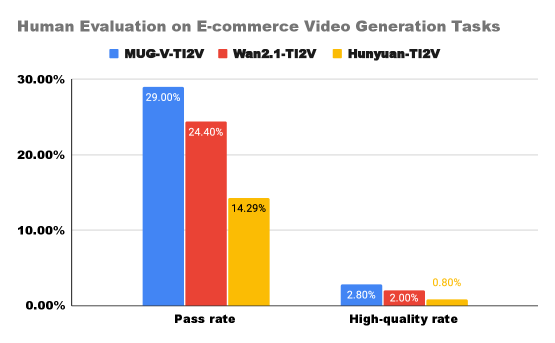
- MUG-V 10B模型在电商视频生成任务上超越现有开源模型,并开源了模型权重和基于Megatron-Core的训练代码。
📝 摘要(中文)
近年来,视觉内容生成模型(如图像、视频和3D对象/场景)取得了显著进展。然而,由于跨模态文本-视频对齐、长序列处理以及复杂的时空依赖关系,大规模视频生成模型的训练仍然极具挑战性且资源密集。为了应对这些挑战,我们提出了一个训练框架,该框架优化了四个关键方面:(i)数据处理,(ii)模型架构,(iii)训练策略,以及(iv)大规模视频生成模型的基础设施。这些优化在数据预处理、视频压缩、参数缩放、基于课程的预训练和以对齐为中心的后训练的各个阶段都带来了显著的效率提升和性能改进。我们最终的模型MUG-V 10B在整体上与最新的视频生成器相匹配,并且在面向电商的视频生成任务中,在人工评估中超过了领先的开源基线。更重要的是,我们开源了完整的技术栈,包括模型权重、基于Megatron-Core的大规模训练代码以及用于视频生成和增强的推理管道。据我们所知,这是首次公开发布利用Megatron-Core实现高训练效率和近线性多节点扩展的大规模视频生成训练代码。
🔬 方法详解
问题定义:大规模视频生成模型训练面临着计算资源消耗大、训练效率低下的问题。现有的方法难以有效处理长视频序列中的时空依赖关系,并且在跨模态文本-视频对齐方面存在挑战,导致生成视频的质量和相关性受到限制。
核心思路:论文的核心思路是通过系统性地优化数据处理、模型架构、训练策略和基础设施四个关键方面,从而提升大规模视频生成模型的训练效率和生成质量。这种多维度的优化方法旨在解决视频生成中的各种瓶颈,并实现更好的性能。
技术框架:整体框架包含数据预处理、视频压缩、模型构建、预训练和后训练等阶段。数据预处理阶段负责清洗和准备训练数据;视频压缩阶段旨在减少计算负担;模型构建阶段选择合适的模型架构;预训练阶段使用课程学习策略;后训练阶段则专注于文本-视频对齐。整个流程利用Megatron-Core实现高效的分布式训练。
关键创新:论文的关键创新在于对训练流程的全面优化,包括数据处理流程的改进、模型架构的调整、训练策略的优化以及基础设施的升级。特别是,利用Megatron-Core实现了近线性的多节点扩展,显著提升了训练效率。此外,针对电商场景的视频生成进行了专门优化。
关键设计:论文采用了课程学习策略进行预训练,逐步增加训练难度,从而提高模型的泛化能力。在后训练阶段,设计了专门的损失函数来增强文本-视频对齐。模型架构方面,可能采用了Transformer或类似的模型结构来捕捉时空依赖关系。具体的参数设置和网络结构细节在论文中可能未完全公开,需要参考开源代码。
🖼️ 关键图片


📊 实验亮点
MUG-V 10B模型在电商视频生成任务上的人工评估中超越了领先的开源基线。论文开源了完整的技术栈,包括模型权重、基于Megatron-Core的大规模训练代码和推理管道,为研究人员和开发者提供了宝贵的资源。该模型在训练效率和生成质量上都取得了显著提升,为大规模视频生成领域做出了重要贡献。
🎯 应用场景
该研究成果可广泛应用于电商、广告、教育等领域,用于自动生成商品展示视频、广告创意视频和教学视频等。通过降低视频生成成本和提高生成效率,可以赋能各行业的内容创作,并为用户提供更丰富、更个性化的视频体验。未来,该技术有望进一步拓展到游戏、电影等领域,实现更高级的视频内容生成。
📄 摘要(原文)
In recent years, large-scale generative models for visual content (\textit{e.g.,} images, videos, and 3D objects/scenes) have made remarkable progress. However, training large-scale video generation models remains particularly challenging and resource-intensive due to cross-modal text-video alignment, the long sequences involved, and the complex spatiotemporal dependencies. To address these challenges, we present a training framework that optimizes four pillars: (i) data processing, (ii) model architecture, (iii) training strategy, and (iv) infrastructure for large-scale video generation models. These optimizations delivered significant efficiency gains and performance improvements across all stages of data preprocessing, video compression, parameter scaling, curriculum-based pretraining, and alignment-focused post-training. Our resulting model, MUG-V 10B, matches recent state-of-the-art video generators overall and, on e-commerce-oriented video generation tasks, surpasses leading open-source baselines in human evaluations. More importantly, we open-source the complete stack, including model weights, Megatron-Core-based large-scale training code, and inference pipelines for video generation and enhancement. To our knowledge, this is the first public release of large-scale video generation training code that exploits Megatron-Core to achieve high training efficiency and near-linear multi-node scaling, details are available in https://github.com/Shopee-MUG/MUG-V.