Context-Aware Pseudo-Label Scoring for Zero-Shot Video Summarization
作者: Yuanli Wu, Long Zhang, Yue Du, Bin Li
分类: cs.CV, cs.AI
发布日期: 2025-10-20 (更新: 2025-10-22)
💡 一句话要点
提出一种基于上下文感知伪标签评分的零样本视频摘要框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 零样本学习 视频摘要 大型语言模型 伪标签 上下文感知
📋 核心要点
- 现有零样本视频摘要方法难以兼顾局部显著性和全局连贯性,导致摘要质量不稳定。
- 利用少量人工标注构建伪标签和规则,结合上下文提示,引导大型语言模型进行视频摘要评分。
- 实验表明,该方法在三个基准数据集上均优于现有零样本方法,且无需参数调整。
📝 摘要(中文)
本文提出了一种基于规则引导、伪标签和提示驱动的零样本视频摘要框架,该框架将大型语言模型与结构化语义推理相结合。少量的人工标注被转换为高置信度的伪标签,并组织成数据集自适应的规则,定义了清晰的评估维度,如主题相关性、动作细节和叙事进展。在推理过程中,包括开头和结尾片段的边界场景根据其自身的描述独立评分,而中间场景则结合相邻片段的简洁摘要来评估叙事连贯性和冗余度。这种设计使语言模型能够在没有任何参数调整的情况下平衡局部显著性和全局连贯性。在三个基准测试中,该方法取得了稳定且具有竞争力的结果,在SumMe上F1得分为57.58,在TVSum上为63.05,在QFVS上为53.79,分别超过零样本基线+0.85、+0.84和+0.37。这些结果表明,规则引导的伪标签结合上下文提示有效地稳定了基于LLM的评分,并为通用和查询聚焦的视频摘要建立了一个通用的、可解释的和免训练的范例。
🔬 方法详解
问题定义:现有的零样本视频摘要方法通常难以在局部显著性和全局连贯性之间取得平衡。它们可能过度关注单个片段的重要性,而忽略了视频整体的叙事结构和流畅性,导致生成的摘要缺乏连贯性和代表性。此外,现有方法通常依赖于复杂的模型设计或需要大量的训练数据,限制了其在实际应用中的灵活性和可扩展性。
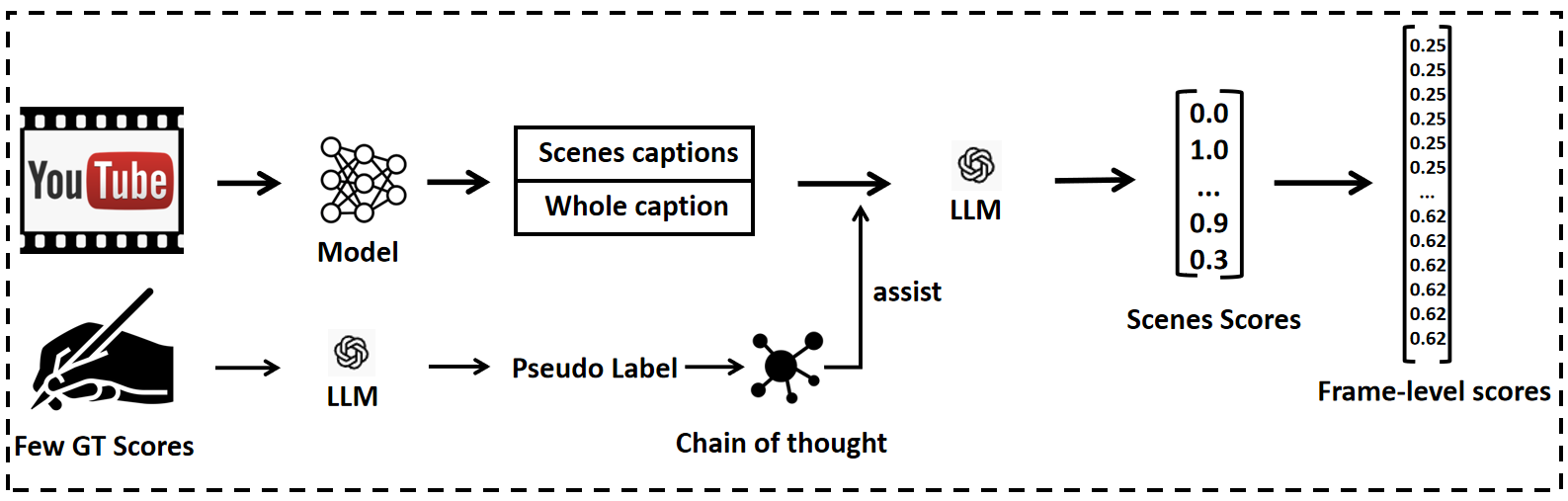
核心思路:本文的核心思路是利用少量人工标注构建高质量的伪标签,并将其组织成数据集自适应的规则(rubrics),这些规则定义了视频摘要的关键评估维度,如主题相关性、动作细节和叙事进展。通过结合上下文提示,引导大型语言模型(LLM)对视频片段进行评分,从而在无需任何参数调整的情况下,实现局部显著性和全局连贯性的平衡。
技术框架:该框架主要包含以下几个阶段:1) 伪标签生成:将少量人工标注转换为高置信度的伪标签。2) 规则构建:将伪标签组织成数据集自适应的规则,定义视频摘要的评估维度。3) 上下文提示:在评分过程中,边界场景独立评分,中间场景结合相邻片段的摘要进行评分,以评估叙事连贯性。4) LLM评分:利用大型语言模型对视频片段进行评分,生成视频摘要。
关键创新:该方法最重要的技术创新点在于结合了规则引导的伪标签和上下文提示,有效地稳定了基于LLM的评分。与现有方法相比,该方法无需任何参数调整,即可在多个基准数据集上取得具有竞争力的结果。此外,该方法具有良好的可解释性,可以清晰地了解LLM的评分依据。
关键设计:该方法的关键设计包括:1) 数据集自适应的规则:根据不同数据集的特点,构建不同的规则,以适应不同视频的摘要需求。2) 上下文提示策略:通过结合相邻片段的摘要,使LLM能够更好地理解视频的叙事结构和流畅性。3) 免训练范例:该方法无需任何参数调整,即可在多个基准数据集上取得良好的效果,降低了使用门槛。
🖼️ 关键图片


📊 实验亮点
该方法在SumMe、TVSum和QFVS三个基准数据集上分别取得了57.58、63.05和53.79的F1得分,分别超过零样本基线+0.85、+0.84和+0.37。这些结果表明,该方法能够有效地提高零样本视频摘要的性能,并且具有良好的泛化能力。
🎯 应用场景
该研究成果可应用于多种视频摘要场景,例如新闻视频摘要、体育赛事视频摘要、电影预告片生成等。该方法能够自动生成高质量的视频摘要,节省人工标注成本,提高视频内容理解和检索效率。未来,该方法有望应用于智能监控、在线教育等领域,实现更智能化的视频内容分析和管理。
📄 摘要(原文)
We propose a rubric-guided, pseudo-labeled, and prompt-driven zero-shot video summarization framework that bridges large language models with structured semantic reasoning. A small subset of human annotations is converted into high-confidence pseudo labels and organized into dataset-adaptive rubrics defining clear evaluation dimensions such as thematic relevance, action detail, and narrative progression. During inference, boundary scenes, including the opening and closing segments, are scored independently based on their own descriptions, while intermediate scenes incorporate concise summaries of adjacent segments to assess narrative continuity and redundancy. This design enables the language model to balance local salience with global coherence without any parameter tuning. Across three benchmarks, the proposed method achieves stable and competitive results, with F1 scores of 57.58 on SumMe, 63.05 on TVSum, and 53.79 on QFVS, surpassing zero-shot baselines by +0.85, +0.84, and +0.37, respectively. These outcomes demonstrate that rubric-guided pseudo labeling combined with contextual prompting effectively stabilizes LLM-based scoring and establishes a general, interpretable, and training-free paradigm for both generic and query-focused video summarization.