DeepDetect: Learning All-in-One Dense Keypoints
作者: Shaharyar Ahmed Khan Tareen, Filza Khan Tareen, Xiaojing Yuan
分类: cs.CV
发布日期: 2025-10-20 (更新: 2026-01-19)
备注: 8 pages, 8 figures, 3 tables, 6 equations
💡 一句话要点
DeepDetect:提出一种融合经典检测器优势的端到端密集关键点检测方法
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 关键点检测 深度学习 图像配准 3D重建 视觉里程计 SLAM 特征提取 密集关键点
📋 核心要点
- 现有关键点检测方法对光照变化敏感,关键点密度低,难以适应复杂场景,且缺乏语义理解能力。
- DeepDetect通过融合多个经典检测器的优势,并利用深度学习进行训练,从而实现对图像的语义理解和高密度关键点检测。
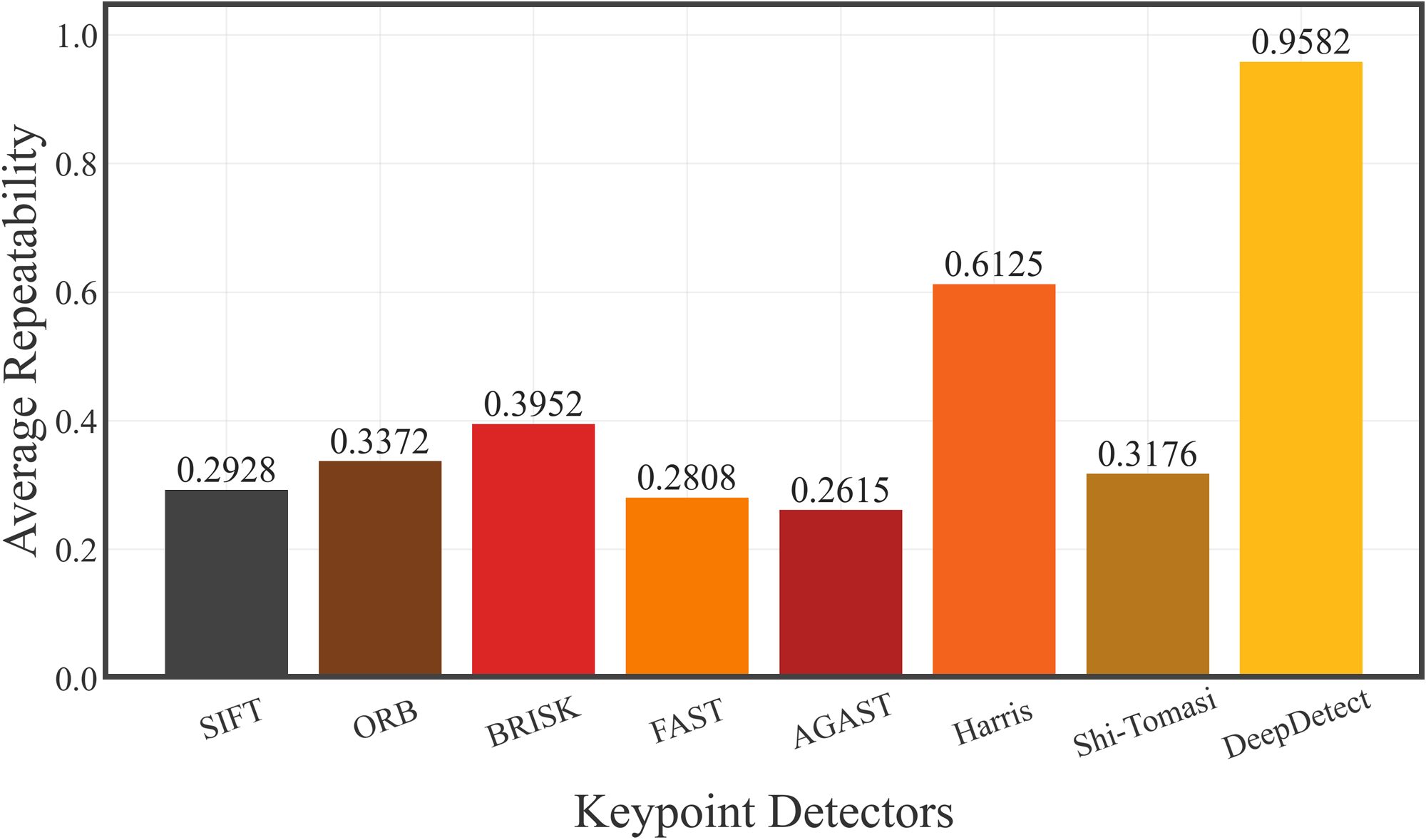
- 实验结果表明,DeepDetect在关键点密度、重复性和匹配数量等方面均优于其他检测器,并在3D重建任务中表现出色。
📝 摘要(中文)
关键点检测是诸多计算机视觉任务的基础,包括图像配准、运动结构恢复、3D重建、视觉里程计和SLAM。传统检测器(SIFT、ORB、BRISK、FAST等)和基于学习的方法(SuperPoint、R2D2、QuadNet、LIFT等)虽然取得了显著进展,但仍存在局限性:对光度变化敏感、关键点密度和重复性低、对复杂场景的适应性有限,且缺乏语义理解,常常无法优先考虑视觉上重要的区域。我们提出了DeepDetect,一种智能的、一体化的密集检测器,它利用深度学习统一了经典检测器的优势。首先,我们通过融合7个关键点检测器和2个边缘检测器的输出,创建ground-truth掩码,从图像中的角点、斑点到显著边缘和纹理中提取多样化的视觉线索。然后,使用轻量且高效的模型ESPNet,以融合的掩码作为标签进行训练,使DeepDetect能够语义地关注图像,同时产生高度密集的关键点,并适应多样化和视觉退化的条件。在Oxford、HPatches和Middlebury数据集上的评估表明,DeepDetect超越了其他检测器,实现了最大值:0.5143(平均关键点密度)、0.9582(平均重复性)、338,118(正确匹配)和842,045(立体3D重建中的体素)。
🔬 方法详解
问题定义:现有关键点检测方法在光照变化、关键点密度、场景适应性和语义理解方面存在不足。传统方法对光照变化敏感,学习方法关键点密度低,难以适应复杂场景,且无法有效区分图像中的重要区域。
核心思路:DeepDetect的核心思路是融合多种经典关键点检测器的优势,利用它们提取的多样化视觉线索,并通过深度学习模型进行学习,从而获得对图像的语义理解能力和高密度关键点检测能力。这种融合策略旨在克服单一检测器的局限性,提高检测器的鲁棒性和适应性。
技术框架:DeepDetect的整体框架包括两个主要阶段:1) Ground-truth掩码生成阶段:融合7个关键点检测器和2个边缘检测器的输出,生成用于训练的ground-truth掩码。2) 模型训练阶段:使用轻量级ESPNet模型,以生成的ground-truth掩码作为标签进行训练,使模型学习到图像的语义信息和关键点分布。
关键创新:DeepDetect的关键创新在于其融合多种经典检测器输出的策略,以及利用深度学习模型学习语义信息的能力。与传统方法相比,DeepDetect能够更好地适应复杂场景和光照变化,并生成高密度的关键点。与现有的学习方法相比,DeepDetect通过融合经典检测器的优势,提高了关键点检测的鲁棒性和准确性。
关键设计:Ground-truth掩码的生成过程至关重要,需要仔细选择融合的检测器和融合策略。ESPNet模型的选择考虑了其轻量性和高效性,使其能够在资源有限的设备上运行。损失函数的设计需要平衡关键点密度和准确性,以获得最佳的检测性能。具体参数设置和训练策略未知。
🖼️ 关键图片


📊 实验亮点
DeepDetect在Oxford、HPatches和Middlebury数据集上取得了显著的性能提升。在关键点密度方面,DeepDetect达到了0.5143,优于其他检测器。在平均重复性方面,DeepDetect达到了0.9582。在正确匹配数量方面,DeepDetect达到了338,118。在立体3D重建中,DeepDetect生成的体素数量达到了842,045,表明其在3D重建任务中具有出色的表现。
🎯 应用场景
DeepDetect在图像配准、运动结构恢复、3D重建、视觉里程计和SLAM等计算机视觉任务中具有广泛的应用前景。其高密度和高重复性的关键点检测能力可以提高这些任务的准确性和鲁棒性。此外,DeepDetect还可以应用于机器人导航、增强现实和虚拟现实等领域,为这些应用提供更可靠的视觉感知能力。
📄 摘要(原文)
Keypoint detection is the foundation of many computer vision tasks, including image registration, structure-from-motion, 3D reconstruction, visual odometry, and SLAM. Traditional detectors (SIFT, ORB, BRISK, FAST, etc.) and learning-based methods (SuperPoint, R2D2, QuadNet, LIFT, etc.) have shown strong performance gains yet suffer from key limitations: sensitivity to photometric changes, low keypoint density and repeatability, limited adaptability to challenging scenes, and lack of semantic understanding, often failing to prioritize visually important regions. We present DeepDetect, an intelligent, all-in-one, dense detector that unifies the strengths of classical detectors using deep learning. Firstly, we create ground-truth masks by fusing outputs of 7 keypoint and 2 edge detectors, extracting diverse visual cues from corners and blobs to prominent edges and textures in the images. Afterwards, a lightweight and efficient model: ESPNet, is trained using fused masks as labels, enabling DeepDetect to focus semantically on images while producing highly dense keypoints, that are adaptable to diverse and visually degraded conditions. Evaluations on Oxford, HPatches, and Middlebury datasets demonstrate that DeepDetect surpasses other detectors achieving maximum values of 0.5143 (average keypoint density), 0.9582 (average repeatability), 338,118 (correct matches), and 842,045 (voxels in stereo 3D reconstruction).