Closed-Loop Transfer for Weakly-supervised Affordance Grounding
作者: Jiajin Tang, Zhengxuan Wei, Ge Zheng, Sibei Yang
分类: cs.CV
发布日期: 2025-10-20
备注: Accepted at ICCV 2025
💡 一句话要点
提出LoopTrans闭环框架,解决弱监督可供性定位中的知识迁移问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 弱监督学习 可供性定位 知识迁移 闭环学习 跨模态学习
📋 核心要点
- 现有弱监督可供性定位方法依赖单向知识迁移,限制了其在复杂交互场景中的应用。
- LoopTrans通过闭环知识迁移,同时增强外部视角和自我视角的知识,弥合领域差距。
- 实验表明,LoopTrans在图像和视频基准测试中取得了显著提升,尤其是在遮挡场景下。
📝 摘要(中文)
本文提出了一种名为LoopTrans的闭环框架,用于解决弱监督可供性定位问题。该方法旨在模仿人类通过观察他人互动来学习与新物体交互的能力。LoopTrans不仅将知识从以外部视角拍摄的交互图像迁移到以自我为中心的图像,还反向迁移以增强外部视角知识的提取。该框架引入了统一的跨模态定位和去噪知识蒸馏等创新机制,以弥合物体中心自我图像和交互中心外部图像之间的领域差距,并增强知识迁移。实验结果表明,LoopTrans在图像和视频基准测试中均取得了持续的性能提升,即使在物体交互区域完全被人体遮挡的具有挑战性的场景中也能有效工作。
🔬 方法详解
问题定义:论文旨在解决弱监督可供性定位问题,即在只有图像级别标注的情况下,定位自我中心图像中能够执行特定动作的物体区域。现有方法主要依赖于从外部视角图像到自我中心图像的单向知识迁移,忽略了自我中心图像中蕴含的丰富信息,并且容易受到领域差异的影响,导致性能受限。
核心思路:论文的核心思路是构建一个闭环的知识迁移框架,LoopTrans。该框架不仅将知识从外部视角图像迁移到自我中心图像,还反向迁移知识,从而相互促进,迭代提升。通过这种方式,可以更好地利用两种视角的信息,并减小领域差异带来的影响。
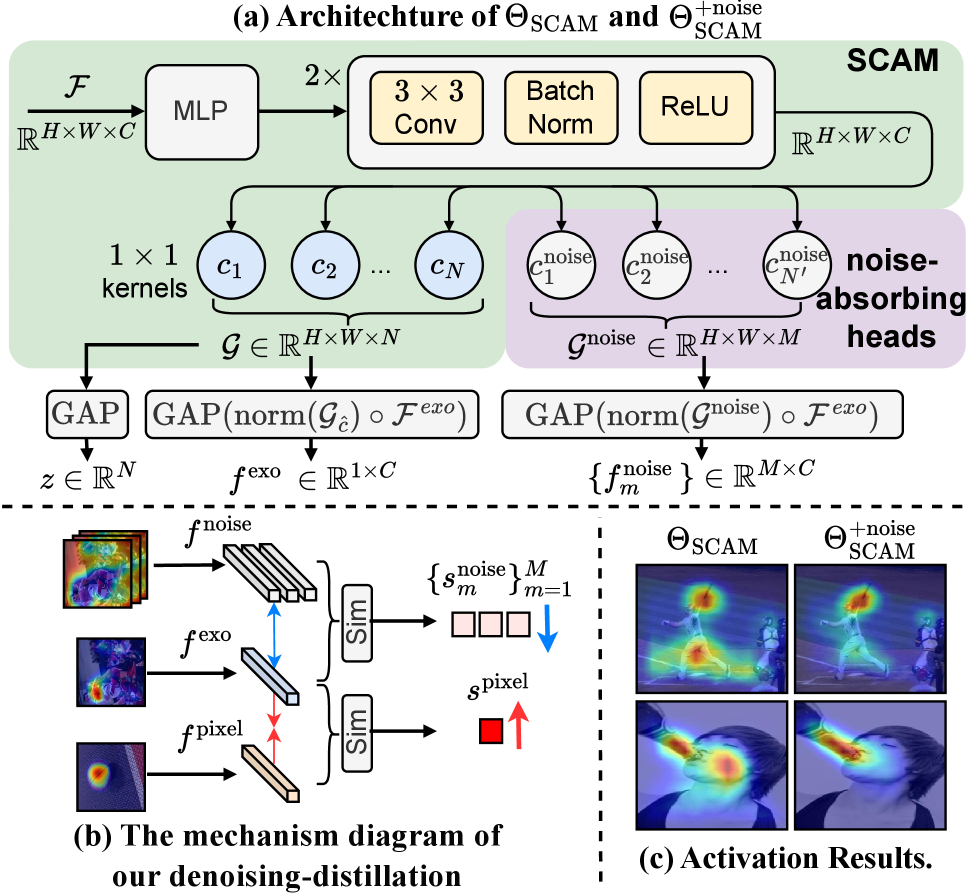
技术框架:LoopTrans框架包含两个主要的知识迁移方向:从外部视角到自我视角,以及从自我视角到外部视角。框架包含统一的跨模态定位模块,用于学习两种视角下的物体区域表示。同时,采用去噪知识蒸馏方法,减少噪声数据对知识迁移的影响。整体流程是,首先利用外部视角图像进行初始的可供性定位,然后将这些知识迁移到自我中心图像,并利用自我中心图像进行反向知识迁移,最终迭代优化两个视角的定位结果。
关键创新:LoopTrans的关键创新在于闭环的知识迁移机制。与以往的单向迁移方法不同,LoopTrans通过双向迁移,实现了知识的相互增强和迭代优化。此外,统一的跨模态定位模块和去噪知识蒸馏方法也为知识迁移的有效性提供了保障。
关键设计:在统一的跨模态定位模块中,论文可能采用了共享的特征提取网络,并针对不同视角设计了特定的注意力机制。在去噪知识蒸馏中,可能使用了对抗训练或置信度加权等方法,以减少噪声数据的影响。具体的损失函数可能包括定位损失、知识蒸馏损失和对抗损失等。网络结构细节和参数设置在论文中会有更详细的描述。
🖼️ 关键图片


📊 实验亮点
LoopTrans在图像和视频基准测试中均取得了显著的性能提升。尤其是在物体交互区域被完全遮挡的具有挑战性的场景中,LoopTrans依然能够有效地定位可供性区域,表明其具有较强的鲁棒性和泛化能力。具体的性能数据和对比基线需要在论文中查找。
🎯 应用场景
该研究成果可应用于机器人操作、人机交互、辅助驾驶等领域。例如,机器人可以通过观察人类的交互行为,学习如何操作新的物体,从而提高其自主性和适应性。在辅助驾驶中,该技术可以帮助车辆更好地理解驾驶员的意图,并提供更智能的辅助功能。未来,该技术有望在更多需要理解和预测人类行为的场景中发挥重要作用。
📄 摘要(原文)
Humans can perform previously unexperienced interactions with novel objects simply by observing others engage with them. Weakly-supervised affordance grounding mimics this process by learning to locate object regions that enable actions on egocentric images, using exocentric interaction images with image-level annotations. However, extracting affordance knowledge solely from exocentric images and transferring it one-way to egocentric images limits the applicability of previous works in complex interaction scenarios. Instead, this study introduces LoopTrans, a novel closed-loop framework that not only transfers knowledge from exocentric to egocentric but also transfers back to enhance exocentric knowledge extraction. Within LoopTrans, several innovative mechanisms are introduced, including unified cross-modal localization and denoising knowledge distillation, to bridge domain gaps between object-centered egocentric and interaction-centered exocentric images while enhancing knowledge transfer. Experiments show that LoopTrans achieves consistent improvements across all metrics on image and video benchmarks, even handling challenging scenarios where object interaction regions are fully occluded by the human body.