Enhanced Motion Forecasting with Plug-and-Play Multimodal Large Language Models
作者: Katie Luo, Jingwei Ji, Tong He, Runsheng Xu, Yichen Xie, Dragomir Anguelov, Mingxing Tan
分类: cs.CV
发布日期: 2025-10-20
备注: In proceedings of IROS 2025
💡 一句话要点
提出Plug-and-Forecast,利用多模态大语言模型增强运动预测模型,提升泛化能力。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 运动预测 多模态大语言模型 自动驾驶 场景理解 零样本学习
📋 核心要点
- 现有运动预测模型在复杂场景泛化能力不足,难以应对多样化的真实世界情况。
- PnF利用多模态大语言模型理解场景,提取结构化信息并融入现有运动预测模型。
- 实验表明,PnF无需微调即可显著提升运动预测性能,并在多个数据集上验证了有效性。
📝 摘要(中文)
当前自动驾驶系统依赖于专门的模型进行感知和运动预测,这些模型在标准条件下表现可靠。然而,以经济高效的方式推广到各种真实世界场景仍然是一个重大挑战。为了解决这个问题,我们提出Plug-and-Forecast (PnF),一种即插即用的方法,用多模态大语言模型(MLLM)增强现有的运动预测模型。PnF建立在自然语言提供了一种更有效的方式来描述和处理复杂场景的洞察力之上,从而能够快速适应目标行为。我们设计提示来从MLLM中提取结构化的场景理解,并将这些信息提炼成可学习的嵌入,以增强现有的行为预测模型。我们的方法利用MLLM的零样本推理能力,在运动预测性能方面取得了显著的改进,而无需微调——使其具有实际应用价值。我们在Waymo Open Motion Dataset和nuScenes Dataset上使用两种最先进的运动预测模型验证了我们的方法,证明了在两个基准测试中性能的持续改进。
🔬 方法详解
问题定义:现有自动驾驶系统的运动预测模型在特定场景下表现良好,但面对复杂、多变的真实世界环境时,泛化能力不足。主要痛点在于难以有效利用场景中的上下文信息,例如交通规则、行人意图等,导致预测精度下降。
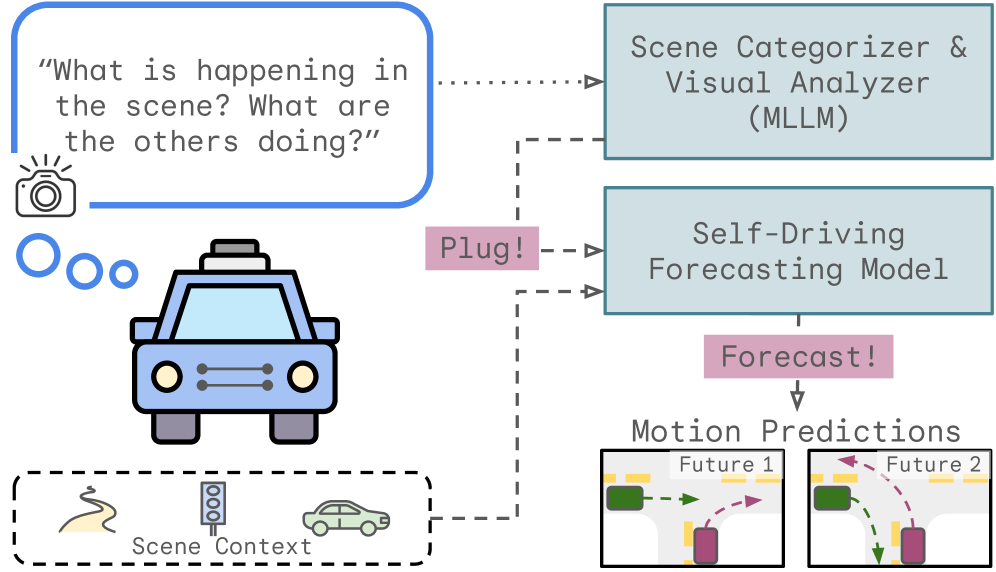
核心思路:论文的核心思路是利用多模态大语言模型(MLLMs)强大的场景理解和推理能力,将场景信息转化为结构化表示,并将其融入到现有的运动预测模型中。通过这种方式,可以增强模型对复杂场景的理解,提高预测的准确性和鲁棒性。
技术框架:PnF框架包含以下几个主要步骤:1) 使用MLLM对场景进行理解,并设计特定的prompt,提取结构化的场景信息,例如交通参与者的类型、位置、行为意图等。2) 将提取的场景信息编码为可学习的嵌入向量。3) 将这些嵌入向量作为额外输入,融入到现有的运动预测模型中,增强模型对场景上下文的感知能力。4) 利用现有的运动预测模型进行运动轨迹预测。
关键创新:该方法最重要的创新点在于利用MLLM的零样本推理能力,无需对MLLM进行微调,即可将其应用于运动预测任务。这种即插即用的方式大大降低了使用成本,并提高了模型的泛化能力。此外,将MLLM的输出转化为可学习的嵌入向量,也使得信息融合更加灵活和高效。
关键设计:Prompt的设计是关键。论文设计了特定的prompt,引导MLLM提取与运动预测相关的结构化信息。嵌入向量的设计也需要考虑如何有效地表示场景信息,并将其融入到现有的运动预测模型中。损失函数方面,可以使用现有的运动预测模型的损失函数,并根据需要进行调整,以更好地利用MLLM提供的场景信息。
🖼️ 关键图片


📊 实验亮点
该研究在Waymo Open Motion Dataset和nuScenes Dataset上进行了验证,结果表明,PnF能够显著提升现有运动预测模型的性能。具体而言,在两个数据集上,PnF都取得了持续的性能改进,证明了其有效性和泛化能力。更重要的是,该方法无需对MLLM进行微调,即可实现性能提升,降低了使用成本。
🎯 应用场景
该研究成果可广泛应用于自动驾驶、机器人导航等领域,提升系统在复杂环境下的感知和决策能力。通过利用多模态大语言模型,可以使自动驾驶系统更好地理解交通参与者的行为意图,从而做出更安全、更合理的驾驶决策。此外,该方法还可以应用于其他需要场景理解和预测的任务,例如智能监控、人机交互等。
📄 摘要(原文)
Current autonomous driving systems rely on specialized models for perceiving and predicting motion, which demonstrate reliable performance in standard conditions. However, generalizing cost-effectively to diverse real-world scenarios remains a significant challenge. To address this, we propose Plug-and-Forecast (PnF), a plug-and-play approach that augments existing motion forecasting models with multimodal large language models (MLLMs). PnF builds on the insight that natural language provides a more effective way to describe and handle complex scenarios, enabling quick adaptation to targeted behaviors. We design prompts to extract structured scene understanding from MLLMs and distill this information into learnable embeddings to augment existing behavior prediction models. Our method leverages the zero-shot reasoning capabilities of MLLMs to achieve significant improvements in motion prediction performance, while requiring no fine-tuning -- making it practical to adopt. We validate our approach on two state-of-the-art motion forecasting models using the Waymo Open Motion Dataset and the nuScenes Dataset, demonstrating consistent performance improvements across both benchmarks.