$\mathcal{V}isi\mathcal{P}runer$: Decoding Discontinuous Cross-Modal Dynamics for Efficient Multimodal LLMs
作者: Yingqi Fan, Anhao Zhao, Jinlan Fu, Junlong Tong, Hui Su, Yijie Pan, Wei Zhang, Xiaoyu Shen
分类: cs.CV, cs.CL
发布日期: 2025-10-20
备注: EMNLP 2025 Main
🔗 代码/项目: GITHUB
💡 一句话要点
提出VisiPruner以解决多模态大语言模型的计算开销问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 剪枝技术 计算效率 跨模态交互 视觉-语言任务 模型优化 深度学习
📋 核心要点
- 现有的多模态大语言模型在处理多模态信息时存在计算开销大的问题,尤其是注意力计算的平方增长。
- 本文提出的VisiPruner通过分析跨模态交互过程,设计了一种无训练的剪枝框架,显著减少计算量。
- 实验结果表明,VisiPruner在LLaVA-v1.5 7B模型上减少了99%的视觉相关注意力计算,提升了53.9%的FLOPs效率。
📝 摘要(中文)
多模态大语言模型(MLLMs)在视觉-语言任务中表现出色,但由于多模态标记数量的平方增长,计算开销显著。尽管已有研究尝试对MLLMs进行标记剪枝,但缺乏对其处理和融合多模态信息的基本理解。通过系统分析,本文揭示了一个三阶段的跨模态交互过程,并提出了VisiPruner,一个无训练的剪枝框架,能够减少高达99%的视觉相关注意力计算和53.9%的FLOPs,显著优于现有的标记剪枝方法,并在多种MLLMs中具有良好的泛化能力。
🔬 方法详解
问题定义:本文旨在解决多模态大语言模型在处理多模态信息时的计算开销问题,现有方法在剪枝过程中缺乏对模型内部信息处理的深入理解,导致效果不佳。
核心思路:通过对多模态信息处理的系统分析,提出了一个三阶段的跨模态交互过程,进而设计出VisiPruner剪枝框架,旨在高效减少计算量而不损失性能。
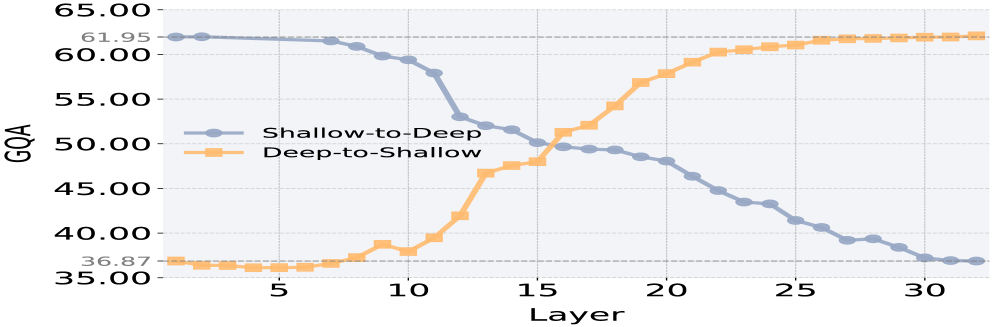
技术框架:整体架构分为三个主要阶段:第一阶段为浅层识别任务意图,视觉标记作为被动注意力接收器;第二阶段为中层的跨模态融合,依赖少量关键视觉标记;第三阶段为深层专注于语言的精炼,丢弃视觉标记。
关键创新:最重要的创新在于提出了VisiPruner剪枝框架,能够在不需要训练的情况下,显著减少视觉相关的计算,且对多种MLLMs具有良好的泛化能力。
关键设计:在设计中,VisiPruner通过分析层级处理动态,提供了有效的剪枝策略,确保在减少计算的同时,保持模型性能的稳定性。
🖼️ 关键图片


📊 实验亮点
实验结果显示,VisiPruner在LLaVA-v1.5 7B模型上成功减少了99%的视觉相关注意力计算和53.9%的FLOPs,相较于现有的标记剪枝方法,性能提升显著,展示了其在多模态大语言模型中的有效性和广泛适用性。
🎯 应用场景
该研究的潜在应用领域包括智能助手、自动驾驶、医疗影像分析等多模态任务,能够显著提高模型的计算效率和响应速度,降低资源消耗,具有重要的实际价值和未来影响。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have achieved strong performance across vision-language tasks, but suffer from significant computational overhead due to the quadratic growth of attention computations with the number of multimodal tokens. Though efforts have been made to prune tokens in MLLMs, \textit{they lack a fundamental understanding of how MLLMs process and fuse multimodal information.} Through systematic analysis, we uncover a \textbf{three-stage} cross-modal interaction process: (1) Shallow layers recognize task intent, with visual tokens acting as passive attention sinks; (2) Cross-modal fusion occurs abruptly in middle layers, driven by a few critical visual tokens; (3) Deep layers discard vision tokens, focusing solely on linguistic refinement. Based on these findings, we propose \emph{VisiPruner}, a training-free pruning framework that reduces up to 99\% of vision-related attention computations and 53.9\% of FLOPs on LLaVA-v1.5 7B. It significantly outperforms existing token pruning methods and generalizes across diverse MLLMs. Beyond pruning, our insights further provide actionable guidelines for training efficient MLLMs by aligning model architecture with its intrinsic layer-wise processing dynamics. Our code is available at: https://github.com/EIT-NLP/VisiPruner.