Towards a Generalizable Fusion Architecture for Multimodal Object Detection
作者: Jad Berjawi, Yoann Dupas, Christophe C'erin
分类: cs.CV
发布日期: 2025-10-20
备注: 8 pages, 8 figures, accepted at ICCV 2025 MIRA Workshop
💡 一句话要点
提出FMCAF架构,提升多模态目标检测的泛化能力与鲁棒性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态融合 目标检测 交叉注意力 频域滤波 泛化能力 RGB-IR 低照度 通用架构
📋 核心要点
- 现有方法在多模态目标检测中泛化性不足,依赖特定数据集的调优,限制了其应用范围。
- FMCAF通过频域滤波抑制冗余特征,并利用交叉注意力机制促进不同模态特征的有效融合,提升泛化性。
- 实验表明,FMCAF在LLVIP和VEDAI数据集上均优于传统融合方法,验证了其作为通用多模态融合架构的潜力。
📝 摘要(中文)
本文提出了一种名为过滤多模态交叉注意力融合(FMCAF)的预处理架构,旨在增强RGB和红外(IR)图像融合的多模态目标检测性能。FMCAF结合了频域滤波模块(Freq-Filter)来抑制冗余频谱特征,以及基于交叉注意力的融合模块(MCAF)来改善模态间特征共享。与针对特定数据集的方法不同,FMCAF致力于提高泛化能力,无需数据集特定调整即可提升不同多模态挑战下的性能。在LLVIP(低光行人检测)和VEDAI(航空车辆检测)数据集上,FMCAF优于传统融合(拼接)方法,在VEDAI上实现了+13.9%的mAP@50,在LLVIP上实现了+1.1%的mAP@50。这些结果表明FMCAF有潜力成为未来检测流程中鲁棒多模态融合的灵活基础。
🔬 方法详解
问题定义:多模态目标检测旨在利用来自不同传感器(如RGB和红外)的互补信息,提高在复杂环境下的检测鲁棒性。然而,现有方法往往针对特定数据集进行优化,泛化能力较差,难以适应新的场景和数据集。这些方法通常需要针对每个数据集进行精细的调优,增加了开发成本和部署难度。
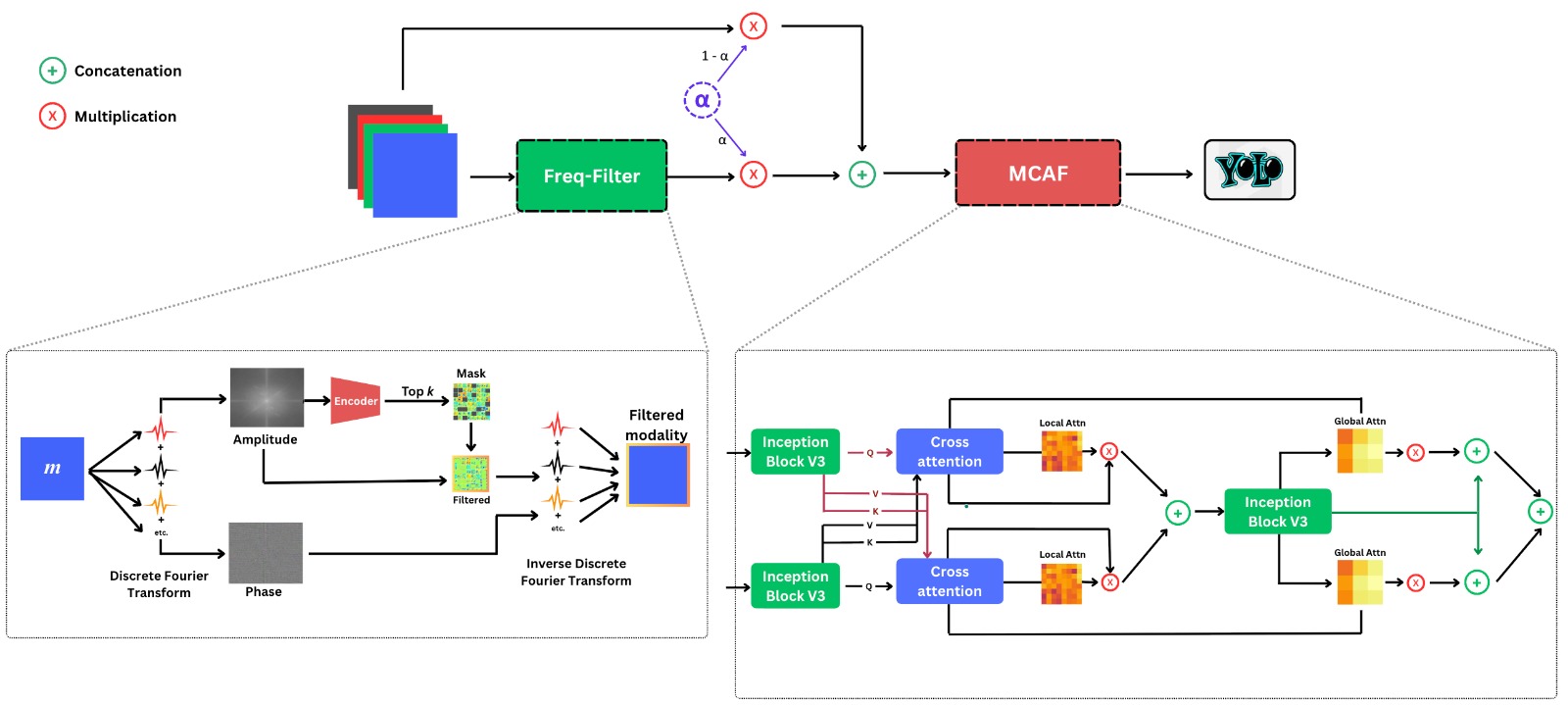
核心思路:本文的核心思路是通过预处理架构FMCAF来增强多模态特征的融合,提高模型的泛化能力。FMCAF包含频域滤波模块(Freq-Filter)和交叉注意力融合模块(MCAF)。Freq-Filter旨在抑制冗余的频谱特征,减少模态间的干扰;MCAF则通过交叉注意力机制,学习不同模态特征之间的相关性,从而实现更有效的特征融合。
技术框架:FMCAF作为一个预处理模块,可以嵌入到现有的目标检测pipeline中。其主要流程是:首先,RGB和IR图像分别经过特征提取网络得到特征图;然后,这些特征图输入到FMCAF模块进行处理,包括Freq-Filter和MCAF两个阶段;最后,经过FMCAF处理后的特征图被送入目标检测网络的后续模块进行目标检测。
关键创新:FMCAF的关键创新在于其通用性设计。不同于以往针对特定数据集的方法,FMCAF旨在通过频域滤波和交叉注意力机制,自适应地学习不同模态特征之间的关系,从而提高模型的泛化能力。这种设计使得FMCAF可以在不同的多模态目标检测任务中应用,而无需进行数据集特定的调优。
关键设计:Freq-Filter模块使用可学习的滤波器来抑制冗余的频谱特征。MCAF模块采用交叉注意力机制,计算不同模态特征之间的注意力权重,从而实现特征的加权融合。具体来说,MCAF模块首先将RGB和IR特征图分别进行线性变换,得到query、key和value;然后,计算query和key之间的注意力权重,并将其应用于value,得到融合后的特征图。损失函数采用标准的交叉熵损失和边界框回归损失。
🖼️ 关键图片


📊 实验亮点
实验结果表明,FMCAF在LLVIP和VEDAI数据集上均取得了显著的性能提升。在VEDAI数据集上,FMCAF相比于传统的拼接融合方法,mAP@50提升了13.9%。在LLVIP数据集上,FMCAF相比于传统的拼接融合方法,mAP@50提升了1.1%。这些结果验证了FMCAF作为通用多模态融合架构的有效性。
🎯 应用场景
该研究成果可广泛应用于自动驾驶、安防监控、机器人等领域。在自动驾驶中,可以利用RGB和红外图像进行全天候的目标检测,提高驾驶安全性。在安防监控中,可以利用红外图像进行夜间监控,提高监控效率。在机器人领域,可以利用多模态信息进行环境感知,提高机器人的自主导航能力。
📄 摘要(原文)
Multimodal object detection improves robustness in chal- lenging conditions by leveraging complementary cues from multiple sensor modalities. We introduce Filtered Multi- Modal Cross Attention Fusion (FMCAF), a preprocess- ing architecture designed to enhance the fusion of RGB and infrared (IR) inputs. FMCAF combines a frequency- domain filtering block (Freq-Filter) to suppress redun- dant spectral features with a cross-attention-based fusion module (MCAF) to improve intermodal feature sharing. Unlike approaches tailored to specific datasets, FMCAF aims for generalizability, improving performance across different multimodal challenges without requiring dataset- specific tuning. On LLVIP (low-light pedestrian detec- tion) and VEDAI (aerial vehicle detection), FMCAF outper- forms traditional fusion (concatenation), achieving +13.9% mAP@50 on VEDAI and +1.1% on LLVIP. These results support the potential of FMCAF as a flexible foundation for robust multimodal fusion in future detection pipelines.