Video Reasoning without Training
作者: Deepak Sridhar, Kartikeya Bhardwaj, Jeya Pradha Jeyaraj, Nuno Vasconcelos, Ankita Nayak, Harris Teague
分类: cs.CV, cs.AI, cs.LG
发布日期: 2025-10-19
💡 一句话要点
提出V-Reason,无需训练即可提升大模型在视频推理任务中的性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频推理 大型多模态模型 无训练学习 熵优化 价值缓存
📋 核心要点
- 现有视频推理LMM依赖强化学习和思维链,计算开销大,且推理过程控制机制有限。
- V-Reason通过熵分析发现模型推理过程中的微探索和微利用行为,并以此为基础优化模型。
- V-Reason无需训练,仅在推理时调整模型,在多个数据集上接近RL模型性能,并显著提升效率。
📝 摘要(中文)
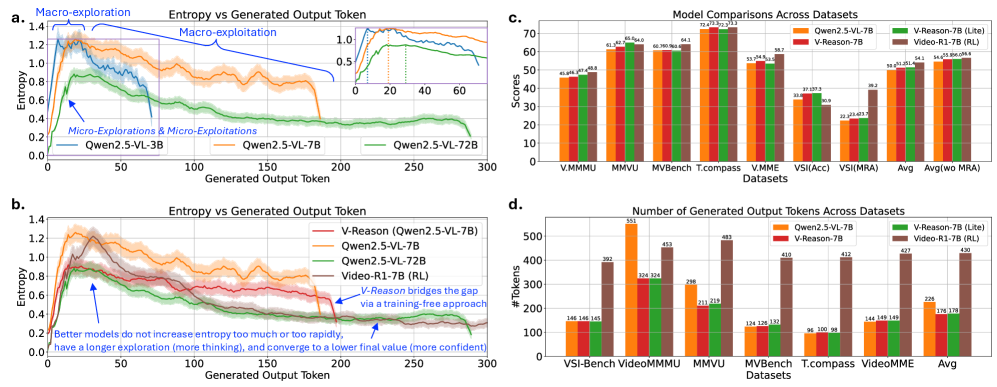
本文提出了一种无需训练的视频推理方法V-Reason,旨在解决大型多模态模型(LMMs)在视频推理中依赖昂贵的强化学习(RL)和冗长的思维链,导致训练和推理过程中计算开销大的问题。通过分析模型输出的熵,发现高质量模型会经历一系列微探索和微利用,从而保持推理过程的可靠性。此外,更准确的模型在“思考”过程结束后,通过最终的利用阶段显著降低熵,表现出更好的收敛性。V-Reason利用这些理论基础,在推理过程中直接调整LMM的价值缓存,通过基于熵的目标函数对小型可训练控制器进行优化,无需任何数据集或RL的监督。实验表明,该方法在多个视频推理数据集上显著优于指令调优的基础模型,在不进行任何训练的情况下,将与RL训练模型的平均准确率差距缩小到0.6%,同时显著提高效率:输出token减少了58.6%。
🔬 方法详解
问题定义:现有基于大型多模态模型(LMMs)的视频推理方法,通常需要大量的强化学习(RL)训练或复杂的思维链(Chain-of-Thought)提示,导致训练成本高昂,推理效率低下。此外,现有方法对模型推理过程的控制能力有限,难以保证推理的可靠性和准确性。
核心思路:论文的核心思路是,通过分析模型在推理过程中的熵值变化,揭示高质量模型在探索和利用之间的平衡关系。具体来说,模型在推理过程中会经历微探索(探索多种可能性)和微利用(利用已知信息)两个阶段。高质量的模型能够有效地控制这两个阶段,并在推理结束时快速收敛到正确的答案。基于这一观察,论文提出了一种无需训练的方法,通过优化模型在推理过程中的探索和利用行为来提高推理性能。
技术框架:V-Reason 的整体框架是在推理阶段,对预训练的 LMM 进行微调。具体流程如下:1) 使用 LMM 对视频进行初步推理;2) 监控 LMM 输出的熵值,以此评估模型的探索和利用状态;3) 使用一个小型可训练控制器,基于熵值优化 LMM 的价值缓存(Value Cache);4) 重复步骤 1-3 若干次,直到模型收敛或达到最大迭代次数。该框架的关键在于控制器的设计和熵值的使用。
关键创新:V-Reason 的最重要创新点在于,它提出了一种无需训练的视频推理方法。与传统的需要大量训练数据和计算资源的 RL 方法不同,V-Reason 仅在推理阶段对模型进行微调,大大降低了成本。此外,V-Reason 通过分析模型输出的熵值,揭示了模型推理过程中的探索和利用行为,为理解和控制 LMM 的推理过程提供了新的视角。
关键设计:V-Reason 的关键设计包括:1) 使用熵值作为模型探索和利用状态的指标;2) 设计了一个小型可训练控制器,用于优化 LMM 的价值缓存;3) 使用基于熵值的目标函数,引导控制器优化模型的探索和利用行为。具体来说,目标函数旨在降低模型在推理结束时的熵值,鼓励模型快速收敛到正确的答案。控制器的具体结构和优化算法(例如,Adam)等细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
V-Reason 在多个视频推理数据集上取得了显著的性能提升。在不进行任何训练的情况下,V-Reason 将与 RL 训练模型的平均准确率差距缩小到 0.6%。同时,V-Reason 显著提高了推理效率,输出 token 减少了 58.6%。这些结果表明,V-Reason 是一种高效且有效的视频推理方法。
🎯 应用场景
V-Reason 有潜力应用于各种需要视频理解和推理的场景,例如智能监控、自动驾驶、视频内容分析和机器人导航。该方法无需训练的特性使其能够快速部署到新的任务和环境中,降低了应用门槛。未来,可以进一步研究如何将 V-Reason 与其他技术相结合,例如知识图谱和符号推理,以提高视频推理的准确性和可解释性。
📄 摘要(原文)
Video reasoning using Large Multimodal Models (LMMs) relies on costly reinforcement learning (RL) and verbose chain-of-thought, resulting in substantial computational overhead during both training and inference. Moreover, the mechanisms that control the thinking process in these reasoning models are very limited. In this paper, using entropy of the model's output as a signal, we discover that the high-quality models go through a series of micro-explorations and micro-exploitations which keep the reasoning process grounded (i.e., avoid excessive randomness while the model is exploring or thinking through an answer). We further observe that once this "thinking" process is over, more accurate models demonstrate a better convergence by reducing the entropy significantly via a final exploitation phase (i.e., a more certain convergence towards a solution trajectory). We then use these novel, theoretically-grounded insights to tune the model's behavior directly at inference, without using any RL or supervised fine-tuning. Specifically, during inference, our proposed approach called V-Reason (Video-Reason) adapts the value cache of the LMM via a few optimization steps on a small, trainable controller using an entropy-based objective, i.e., no supervision from any dataset or RL is necessary. This tuning improves the model's micro-exploration and exploitation behavior during inference. Our experiments show that our proposed method achieves significant improvements over the base instruction-tuned models across several video reasoning datasets, narrowing the gap with RL-trained models to within 0.6% average accuracy without any training, while offering massive efficiency benefits: output tokens are reduced by 58.6% compared to the RL model.