Enrich and Detect: Video Temporal Grounding with Multimodal LLMs
作者: Shraman Pramanick, Effrosyni Mavroudi, Yale Song, Rama Chellappa, Lorenzo Torresani, Triantafyllos Afouras
分类: cs.CV, cs.MM
发布日期: 2025-10-19
备注: ICCV 2025 (Highlights)
💡 一句话要点
提出ED-VTG,利用多模态LLM进行细粒度视频时序定位
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频时序定位 多模态LLM 查询增强 多示例学习 视频理解
📋 核心要点
- 现有视频时序定位方法难以有效利用文本信息,且易受噪声和幻觉影响。
- ED-VTG通过多模态LLM增强查询信息,并使用轻量级解码器进行精确定位。
- 实验表明,ED-VTG在多个基准测试中达到SOTA,并在零样本评估中表现出色。
📝 摘要(中文)
本文提出ED-VTG,一种利用多模态大型语言模型进行细粒度视频时序定位的方法。该方法利用多模态LLM联合处理文本和视频,通过两阶段过程有效地在视频中定位自然语言查询。首先,语言查询被转换为富含信息的句子,其中包含了缺失的细节和线索,以辅助定位。其次,使用一个轻量级解码器对这些增强的查询进行定位,该解码器专门用于预测基于增强查询上下文表示的精确边界。为了减轻噪声并减少幻觉的影响,该模型采用多示例学习目标进行训练,该目标动态地为每个训练样本选择查询的最佳版本。实验结果表明,该方法在时序视频定位和段落定位的各种基准测试中都取得了最先进的结果。实验表明,该方法显著优于所有先前提出的基于LLM的时序定位方法,并且优于或可与专用模型相媲美,同时在零样本评估场景中保持了明显的优势。
🔬 方法详解
问题定义:视频时序定位旨在根据给定的自然语言查询,在视频中找到对应的时间片段。现有方法在处理复杂或模糊的查询时,容易受到噪声和幻觉的影响,并且难以充分利用文本信息进行准确定位。特别是基于LLM的方法,虽然具备一定的理解能力,但在时序定位精度上仍有提升空间。
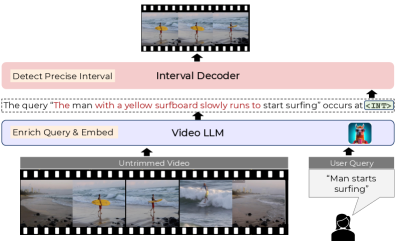
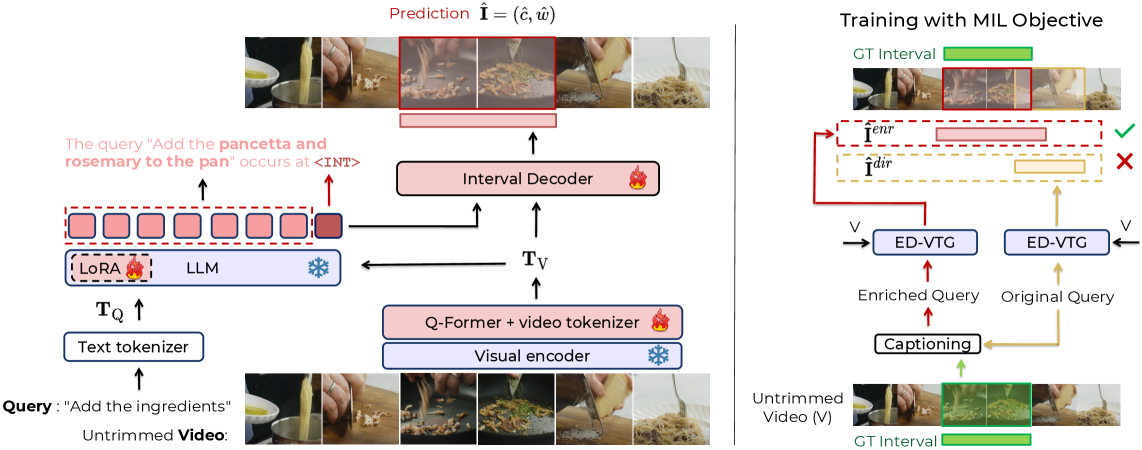
核心思路:ED-VTG的核心思路是首先利用多模态LLM对原始查询进行增强,补充缺失的细节和上下文信息,从而生成更易于定位的“富信息”查询。然后,使用一个轻量级的解码器,基于增强查询的上下文表示,预测视频片段的精确边界。这种两阶段的方法旨在提高定位的准确性和鲁棒性。
技术框架:ED-VTG包含两个主要阶段:查询增强阶段和时序定位阶段。在查询增强阶段,多模态LLM接收原始查询和视频信息(例如视频帧),生成增强后的查询。在时序定位阶段,一个轻量级的解码器接收增强后的查询和视频特征,预测视频片段的起始和结束时间。整个框架采用端到端的方式进行训练。
关键创新:ED-VTG的关键创新在于利用多模态LLM进行查询增强,从而有效地利用了文本和视频信息,提高了定位的准确性。此外,使用多示例学习目标来减轻噪声和幻觉的影响,进一步提升了模型的鲁棒性。与现有方法相比,ED-VTG能够更好地理解复杂的查询,并生成更精确的定位结果。
关键设计:ED-VTG使用预训练的多模态LLM(例如,BLIP-2)作为查询增强器。解码器采用轻量级结构,例如简单的线性层或Transformer层,以提高效率。多示例学习目标通过动态选择每个训练样本的最佳查询版本来优化模型。损失函数通常包括定位损失(例如,IoU损失)和分类损失(如果需要)。
🖼️ 关键图片

📊 实验亮点
ED-VTG在多个视频时序定位基准测试中取得了最先进的结果,显著优于现有的基于LLM的方法。例如,在某些数据集上,ED-VTG的性能提升超过了10%。此外,ED-VTG在零样本评估中也表现出色,表明其具有良好的泛化能力。实验结果证明了ED-VTG在视频时序定位任务中的有效性和优越性。
🎯 应用场景
ED-VTG可应用于视频检索、视频编辑、智能监控等领域。例如,用户可以通过自然语言查询快速找到视频中的特定片段,视频编辑人员可以根据文本描述精确地剪辑视频,智能监控系统可以根据事件描述自动定位异常行为。该研究有助于提升人机交互的效率和智能化水平。
📄 摘要(原文)
We introduce ED-VTG, a method for fine-grained video temporal grounding utilizing multi-modal large language models. Our approach harnesses the capabilities of multimodal LLMs to jointly process text and video, in order to effectively localize natural language queries in videos through a two-stage process. Rather than being directly grounded, language queries are initially transformed into enriched sentences that incorporate missing details and cues to aid in grounding. In the second stage, these enriched queries are grounded, using a lightweight decoder, which specializes at predicting accurate boundaries conditioned on contextualized representations of the enriched queries. To mitigate noise and reduce the impact of hallucinations, our model is trained with a multiple-instance-learning objective that dynamically selects the optimal version of the query for each training sample. We demonstrate state-of-the-art results across various benchmarks in temporal video grounding and paragraph grounding settings. Experiments reveal that our method significantly outperforms all previously proposed LLM-based temporal grounding approaches and is either superior or comparable to specialized models, while maintaining a clear advantage against them in zero-shot evaluation scenarios.