Uniworld-V2: Reinforce Image Editing with Diffusion Negative-aware Finetuning and MLLM Implicit Feedback
作者: Zongjian Li, Zheyuan Liu, Qihui Zhang, Bin Lin, Feize Wu, Shenghai Yuan, Zhiyuan Yan, Yang Ye, Wangbo Yu, Yuwei Niu, Shaodong Wang, Xinhua Cheng, Li Yuan
分类: cs.CV
发布日期: 2025-10-19 (更新: 2025-11-04)
💡 一句话要点
Uniworld-V2:利用扩散负感知微调和MLLM隐式反馈增强图像编辑能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 指令驱动图像编辑 扩散模型 策略优化 多模态大语言模型 隐式反馈 流匹配 负感知微调
📋 核心要点
- 现有指令驱动图像编辑模型易于过拟合训练数据,泛化能力受限,难以探索训练分布之外的编辑。
- 提出Edit-R1框架,核心是DiffusionNFT策略优化和MLLM隐式反馈,无需训练奖励模型,提升编辑质量。
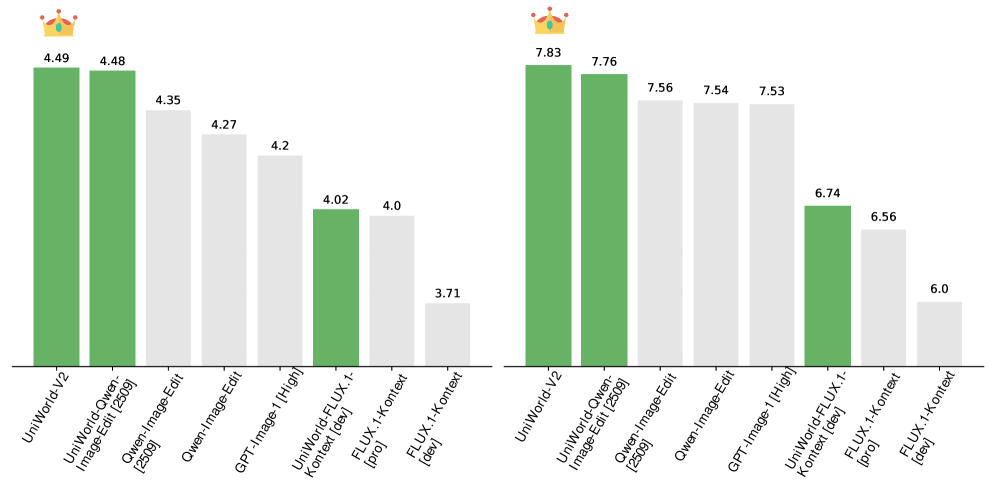
- UniWorld-V2在ImgEdit和GEdit-Bench上取得SOTA结果,且框架可应用于多种基础模型,提升显著。
📝 摘要(中文)
本文提出Edit-R1,一种基于策略优化的指令驱动图像编辑后训练框架。该框架利用扩散负感知微调(DiffusionNFT),这是一种与流匹配前向过程一致的无似然策略优化方法,从而可以使用更高阶的采样器和更高效的训练。此外,本文还采用多模态大型语言模型(MLLM)作为统一的、免训练的奖励模型,利用其输出logits提供细粒度的反馈,以解决缺乏通用奖励模型的问题。精心设计的低方差分组过滤机制用于减少MLLM评分噪声并稳定优化。使用该框架训练的UniWorld-V2在ImgEdit和GEdit-Bench基准测试中取得了最先进的结果,分别获得了4.49和7.83分。该框架具有模型无关性,应用于Qwen-Image-Edit和FLUX-Kontext等不同的基础模型时,性能均得到显著提升,证明了其广泛的适用性。代码和模型已公开。
🔬 方法详解
问题定义:指令驱动的图像编辑任务旨在根据给定的文本指令修改图像。现有方法主要依赖于监督微调,但容易过拟合训练数据中的模式,导致模型在未见过的指令或图像上表现不佳。缺乏通用的、可训练的奖励模型来指导编辑过程也是一个挑战。
核心思路:本文的核心思路是利用策略优化来增强模型的泛化能力和探索能力。通过DiffusionNFT,模型可以在没有显式奖励函数的情况下,学习如何更好地执行编辑指令。同时,利用MLLM的logits作为隐式反馈信号,指导模型的训练,避免了手动设计奖励函数的困难。
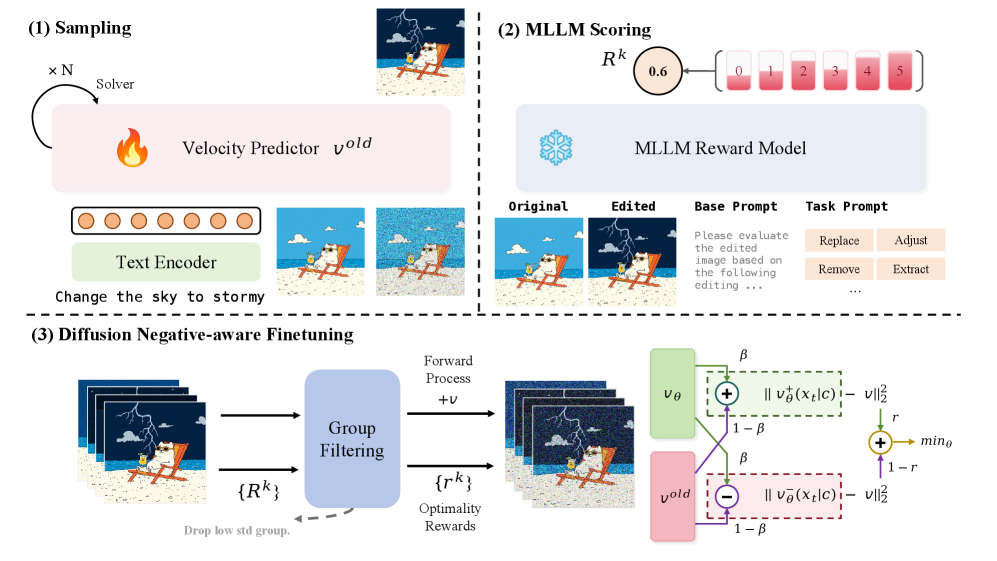
技术框架:Edit-R1框架包含以下主要模块:1) 扩散模型:使用预训练的扩散模型作为图像编辑的基础。2) DiffusionNFT:利用流匹配的前向过程,进行无似然的策略优化。3) MLLM奖励模型:使用MLLM(如GPT-4)作为奖励模型,评估编辑结果的质量,并提供logits作为反馈信号。4) 低方差分组过滤:减少MLLM评分噪声,稳定优化过程。
关键创新:1) DiffusionNFT:将策略优化与扩散模型相结合,无需显式奖励函数,即可进行有效的训练。2) MLLM隐式反馈:利用MLLM的logits作为奖励信号,避免了手动设计奖励函数的困难,并提高了编辑质量。3) 低方差分组过滤:有效降低了MLLM评分的噪声,提高了训练的稳定性。
关键设计:1) DiffusionNFT的损失函数与流匹配前向过程一致,保证了训练的稳定性。2) MLLM奖励模型使用GPT-4等大型语言模型,并使用logits作为反馈信号。3) 低方差分组过滤机制通过对多个MLLM评分进行平均,降低了噪声的影响。4) 框架具有模型无关性,可以应用于不同的基础扩散模型。
🖼️ 关键图片

📊 实验亮点
UniWorld-V2在ImgEdit和GEdit-Bench基准测试中取得了最先进的结果,分别获得了4.49和7.83分,显著优于现有方法。此外,该框架具有模型无关性,应用于Qwen-Image-Edit和FLUX-Kontext等不同的基础模型时,性能均得到显著提升,证明了其广泛的适用性。
🎯 应用场景
该研究成果可广泛应用于图像编辑、内容创作、艺术设计等领域。例如,用户可以通过简单的文本指令,快速修改图像的风格、内容和场景。该技术还可以用于生成个性化的图像内容,满足不同用户的需求。未来,该技术有望应用于虚拟现实、增强现实等领域,为用户提供更加沉浸式的体验。
📄 摘要(原文)
Instruction-based image editing has achieved remarkable progress; however, models solely trained via supervised fine-tuning often overfit to annotated patterns, hindering their ability to explore and generalize beyond training distributions. To this end, we introduce Edit-R1, a novel post-training framework for instruction-based image editing based on policy optimization. Specifically, we utilize Diffusion Negative-aware Finetuning (DiffusionNFT), a likelihood-free policy optimization method consistent with the flow matching forward process, thereby enabling the use of higher-order samplers and more efficient training. Another key challenge here is the absence of a universal reward model, resulting from the diverse nature of editing instructions and tasks. To bridge this gap, we employ a Multimodal Large Language Model (MLLM) as a unified, training-free reward model, leveraging its output logits to provide fine-grained feedback. Furthermore, we carefully design a low-variance group filtering mechanism to reduce MLLM scoring noise and stabilize optimization. \texttt{UniWorld-V2}, trained with this framework, achieves \textbf{state-of-the-art} results on the ImgEdit and GEdit-Bench benchmarks, scoring 4.49 and 7.83, respectively. Crucially, our framework is model-agnostic, delivering substantial performance gains when applied to diverse base models like Qwen-Image-Edit and FLUX-Kontext, demonstrating its wide applicability. Code and models are publicly available to support further research.