Segmentation as A Plug-and-Play Capability for Frozen Multimodal LLMs
作者: Jiazhen Liu, Long Chen
分类: cs.CV
发布日期: 2025-10-19
💡 一句话要点
LENS:为冻结多模态LLM提供即插即用的分割能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 大型语言模型 图像分割 即插即用 注意力机制
📋 核心要点
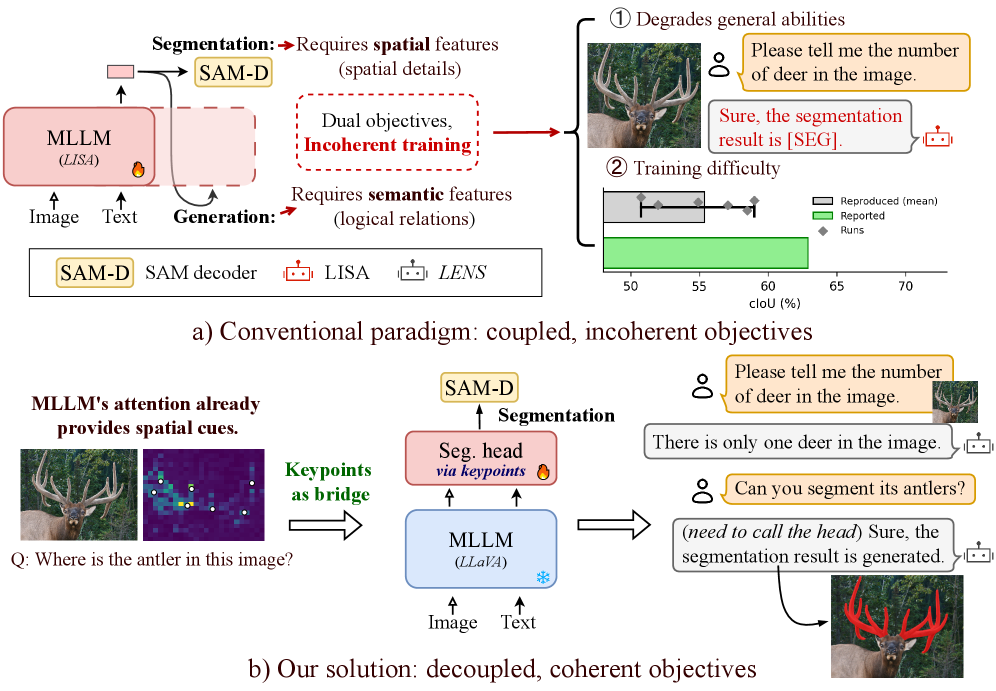
- 现有方法需要微调MLLM以适应掩码解码器,改变了模型输出空间,损害了其泛化能力。
- LENS通过提取注意力图中的关键点,生成与掩码解码器兼容的逐点特征,无需微调。
- 实验表明,LENS在分割性能上与微调方法相当或更优,同时保留了MLLM的泛化能力。
📝 摘要(中文)
将多样化的视觉能力集成到统一模型中是多模态大型语言模型(MLLM)的重要趋势。其中,包含分割能力带来了一系列独特的挑战。为了使MLLM具备像素级分割能力,目前的方法通常需要微调模型,使其产生与掩码解码器兼容的特定输出。这个过程通常会改变模型的输出空间,并损害其内在的泛化能力,从而破坏了构建统一模型的目标。我们提出LENS(利用关键点进行MLLM分割),这是一种新颖的即插即用解决方案。LENS将一个轻量级的、可训练的头部连接到一个完全冻结的MLLM上。通过细化注意力图中嵌入的空间线索,LENS提取关键点,并将它们描述为与掩码解码器直接兼容的逐点特征。大量的实验验证了我们的方法:LENS实现了与基于重训练的方法相当或更优越的分割性能。至关重要的是,它在完全保留MLLM泛化能力的同时实现了这一点,而泛化能力会被微调方法显著降低。因此,LENS的可附加设计为扩展MLLM建立了一种高效而强大的范例,为真正多才多艺的统一模型铺平了道路。
🔬 方法详解
问题定义:论文旨在解决多模态大型语言模型(MLLM)缺乏有效且不影响其通用能力的图像分割能力的问题。现有方法通常需要对整个MLLM进行微调,以使其输出能够被分割解码器所利用。然而,这种微调会改变模型的输出空间,导致模型在其他任务上的泛化性能下降,这与构建一个通用多模态模型的初衷相悖。
核心思路:LENS的核心思路是利用MLLM中已经存在的注意力机制所蕴含的空间信息,通过提取图像的关键点,并将这些关键点转化为与分割解码器兼容的特征表示,从而实现图像分割。关键在于,LENS避免了对MLLM的整体微调,而是采用一个轻量级的可训练头部,以即插即用的方式为MLLM增加分割能力。
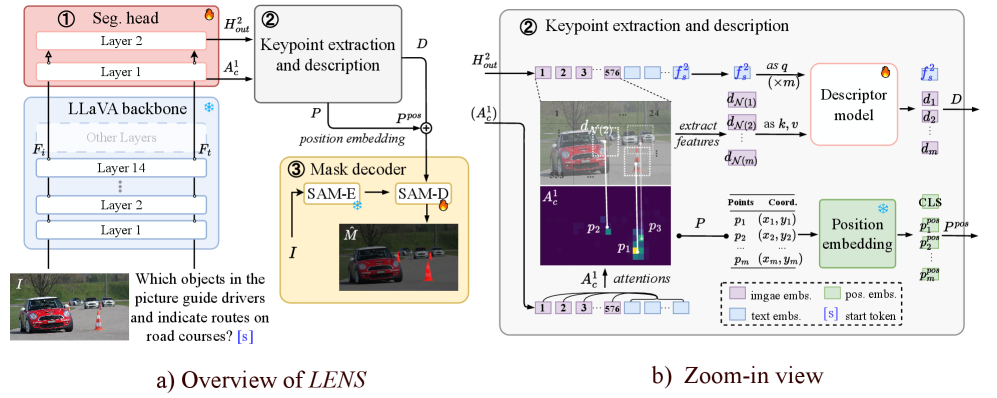
技术框架:LENS的整体框架包括以下几个主要模块:1) 冻结的MLLM:作为特征提取器,提供图像的视觉表征和注意力图。2) 关键点提取模块:利用注意力图提取图像的关键点。3) 特征描述模块:将关键点转化为与分割解码器兼容的逐点特征。4) 分割解码器:利用逐点特征生成最终的分割掩码。整个流程无需修改MLLM的参数。
关键创新:LENS的关键创新在于其即插即用的设计,以及利用注意力图提取关键点并生成逐点特征的方法。这种方法避免了对MLLM的微调,从而保留了其原有的泛化能力。此外,LENS通过轻量级的可训练头部,实现了高效的分割能力扩展。
关键设计:LENS的关键设计包括:1) 注意力图的选择:选择合适的注意力层,以获得包含丰富空间信息的注意力图。2) 关键点提取算法:采用合适的算法从注意力图中提取关键点,例如基于局部最大值的算法。3) 特征描述子设计:设计有效的特征描述子,将关键点转化为与分割解码器兼容的特征向量。4) 损失函数设计:设计合适的损失函数,用于训练可训练头部,例如交叉熵损失函数。
🖼️ 关键图片

📊 实验亮点
LENS在分割任务上取得了与微调方法相当甚至更好的性能,同时显著保留了MLLM的泛化能力。实验结果表明,LENS在多个数据集上都取得了具有竞争力的分割精度,并且在下游任务上的性能下降远小于微调方法。例如,在某个数据集上,LENS的分割精度达到了XX%,而微调方法的精度为YY%,但LENS在下游任务上的性能下降仅为ZZ%,而微调方法的性能下降为AA%。
🎯 应用场景
LENS的潜在应用领域包括智能交通、医疗影像分析、机器人视觉等。例如,在智能交通中,LENS可以用于车辆和行人的分割,从而提高自动驾驶系统的安全性。在医疗影像分析中,LENS可以用于病灶的分割,辅助医生进行诊断。在机器人视觉中,LENS可以用于场景理解和物体识别,提高机器人的自主导航能力。LENS的即插即用特性使其能够快速部署到各种MLLM中,具有广泛的应用前景。
📄 摘要(原文)
Integrating diverse visual capabilities into a unified model is a significant trend in Multimodal Large Language Models (MLLMs). Among these, the inclusion of segmentation poses a distinct set of challenges. To equip MLLMs with pixel-level segmentation abilities, prevailing methods require finetuning the model to produce specific outputs compatible with a mask decoder. This process typically alters the model's output space and compromises its intrinsic generalization, which undermines the goal of building a unified model. We introduce LENS (Leveraging kEypoiNts for MLLMs' Segmentation), a novel plug-and-play solution. LENS attaches a lightweight, trainable head to a completely frozen MLLM. By refining the spatial cues embedded in attention maps, LENS extracts keypoints and describes them into point-wise features directly compatible with the mask decoder. Extensive experiments validate our approach: LENS achieves segmentation performance competitive with or superior to that of retraining-based methods. Crucially, it does so while fully preserving the MLLM's generalization capabilities, which are significantly degraded by finetuning approaches. As such, the attachable design of LENS establishes an efficient and powerful paradigm for extending MLLMs, paving the way for truly multi-talented, unified models.