HumanCM: One Step Human Motion Prediction
作者: Liu Haojie, Gao Suixiang
分类: cs.CV, cs.AI
发布日期: 2025-10-19 (更新: 2025-10-23)
备注: 6 pages, 3 figures, 2 tables
💡 一句话要点
提出HumanCM,一种基于一致性模型的人体运动单步预测框架
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 人体运动预测 一致性模型 单步预测 Transformer 时空建模
📋 核心要点
- 扩散模型在人体运动预测中表现出色,但其多步去噪过程计算成本高昂,限制了实时应用。
- HumanCM利用一致性模型,学习噪声和干净运动状态间的直接映射,实现单步预测,显著提升效率。
- 实验表明,HumanCM在Human3.6M和HumanEva-I数据集上,以更少的推理步骤达到或超过现有扩散模型的精度。
📝 摘要(中文)
本文提出HumanCM,一个基于一致性模型的人体运动预测框架。与基于扩散模型的多步去噪方法不同,HumanCM通过学习噪声运动状态和干净运动状态之间的自洽映射,实现高效的单步生成。该框架采用基于Transformer的时空架构,并结合时间嵌入来建模长程依赖关系,保持运动连贯性。在Human3.6M和HumanEva-I数据集上的实验表明,HumanCM在减少高达两个数量级的推理步骤的同时,实现了与最先进的扩散模型相当或更优的精度。
🔬 方法详解
问题定义:人体运动预测旨在根据过去一段时间的运动序列预测未来一段时间的运动轨迹。现有基于扩散模型的方法虽然取得了不错的效果,但需要进行多次迭代的去噪过程,计算复杂度高,难以满足实时性要求。因此,如何降低推理时间,提高预测效率是亟待解决的问题。
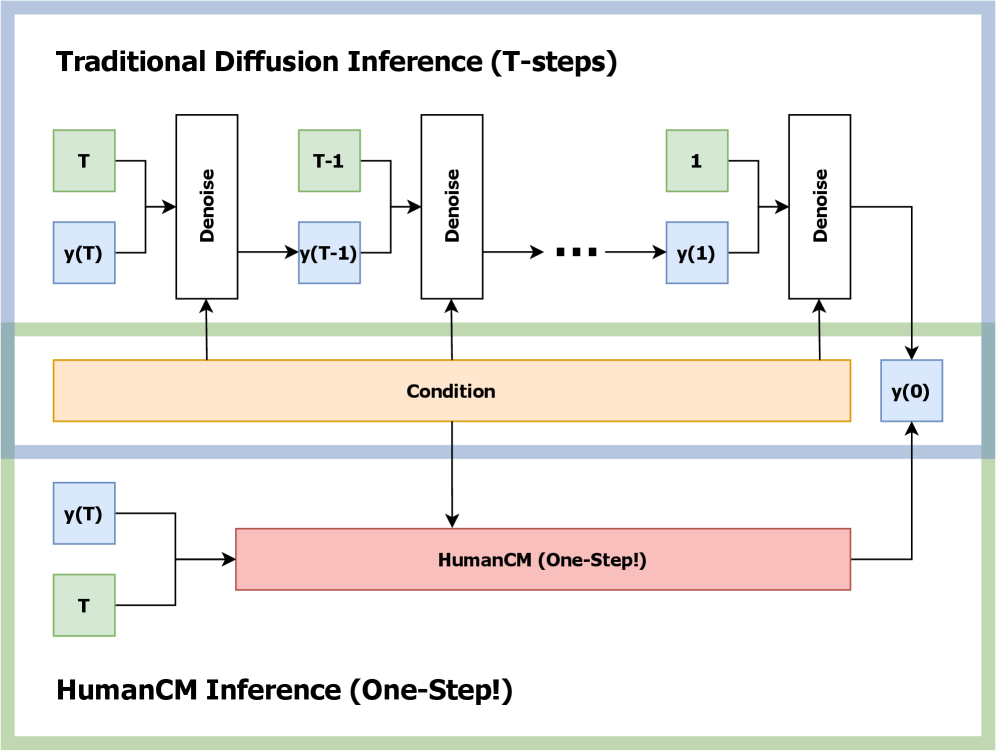
核心思路:HumanCM的核心在于利用一致性模型,直接学习从噪声运动状态到干净运动状态的映射。一致性模型能够训练一个函数,使得从噪声数据出发,经过该函数一步迭代后,得到的结果与从干净数据出发,经过该函数迭代后得到的结果一致。这样,就可以避免扩散模型中耗时的多步去噪过程,实现单步预测。
技术框架:HumanCM的整体框架包括一个基于Transformer的时空架构。该架构首先使用Transformer编码器提取输入运动序列的时空特征,然后使用Transformer解码器预测未来的运动轨迹。为了更好地建模长程时间依赖关系,框架中还引入了时间嵌入,将时间信息融入到特征表示中。整个框架通过一致性损失进行训练,鼓励模型学习噪声和干净运动状态之间的自洽映射。
关键创新:HumanCM的关键创新在于将一致性模型引入到人体运动预测任务中,实现了单步预测。与传统的扩散模型相比,HumanCM无需进行多步去噪,显著降低了推理时间。此外,HumanCM还采用了Transformer-based的时空架构和时间嵌入,有效地建模了运动序列的时空依赖关系。
关键设计:HumanCM使用了一种改进的一致性损失函数,以提高训练的稳定性和收敛速度。具体来说,该损失函数不仅考虑了噪声和干净运动状态之间的一致性,还考虑了不同噪声水平下的一致性。此外,为了更好地利用历史运动信息,HumanCM还设计了一种多尺度的特征融合机制,将不同时间尺度的特征进行融合,以提高预测精度。
🖼️ 关键图片


📊 实验亮点
HumanCM在Human3.6M和HumanEva-I数据集上进行了评估,实验结果表明,HumanCM在减少高达两个数量级的推理步骤的同时,实现了与最先进的扩散模型相当或更优的精度。例如,在Human3.6M数据集上,HumanCM在短期预测(例如400ms)上取得了与ProMotion相当的精度,但在长期预测(例如1000ms)上优于ProMotion。
🎯 应用场景
HumanCM在人机交互、虚拟现实、游戏开发、动画制作等领域具有广泛的应用前景。它可以用于预测虚拟角色的运动,使其更加自然流畅;也可以用于预测用户的运动意图,从而提供更加智能的服务。此外,HumanCM还可以应用于运动分析和康复训练等领域,帮助人们更好地了解和改善自己的运动能力。
📄 摘要(原文)
We present HumanCM, a one-step human motion prediction framework built upon consistency models. Instead of relying on multi-step denoising as in diffusion-based methods, HumanCM performs efficient single-step generation by learning a self-consistent mapping between noisy and clean motion states. The framework adopts a Transformer-based spatiotemporal architecture with temporal embeddings to model long-range dependencies and preserve motion coherence. Experiments on Human3.6M and HumanEva-I demonstrate that HumanCM achieves comparable or superior accuracy to state-of-the-art diffusion models while reducing inference steps by up to two orders of magnitude.