Structured Interfaces for Automated Reasoning with 3D Scene Graphs
作者: Aaron Ray, Jacob Arkin, Harel Biggie, Chuchu Fan, Luca Carlone, Nicholas Roy
分类: cs.CV, cs.AI, cs.RO
发布日期: 2025-10-18
备注: 25 pages, 3 figures
💡 一句话要点
提出基于结构化接口的3D场景图推理方法,提升LLM在机器人自然语言理解中的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D场景图 自然语言理解 大型语言模型 机器人 检索增强生成 Cypher查询语言 知识图谱 结构化推理
📋 核心要点
- 现有方法将3D场景图序列化为文本输入LLM,无法有效处理大型复杂场景图,限制了机器人对环境的理解能力。
- 提出利用检索增强生成,通过Cypher查询语言从图数据库中提取相关场景信息,供LLM进行推理,降低了计算复杂度。
- 实验表明,该方法在指令跟随和场景问答任务中,显著提升了LLM在大型场景图上的性能,并减少了token数量。
📝 摘要(中文)
为了使机器人能够理解并响应用户的自然语言输入,必须将自然语言与机器人对世界的底层表示联系起来。 近年来,大型语言模型(LLM)和3D场景图(3DSG)已成为自然语言 grounding 和世界表示的热门选择。 本文旨在解决将 LLM 与 3DSG 结合以进行自然语言 grounding 的挑战。 现有方法将场景图编码为 LLM 上下文窗口中的序列化文本,但这种编码方式无法扩展到大型或丰富的 3DSG。 因此,我们提出使用一种检索增强生成(Retrieval Augmented Generation)的形式来选择与任务相关的 3DSG 子集。 我们将 3DSG 编码在图数据库中,并提供一种查询语言接口(Cypher)作为 LLM 的工具,LLM 可以使用该工具检索相关数据以进行语言 grounding。 我们在指令跟随和场景问答任务上评估了我们的方法,并与基线上下文窗口和代码生成方法进行了比较。 结果表明,使用 Cypher 作为 3D 场景图的接口,在本地和云端模型上都能更好地扩展到大型、丰富的图。 这在 grounded language 任务中带来了巨大的性能提升,同时也大大减少了场景图内容的 token 数量。
🔬 方法详解
问题定义:现有方法在处理大型、复杂的3D场景图时,直接将整个场景图序列化为文本输入LLM,导致token数量过多,超出LLM的上下文窗口限制,影响推理性能。此外,序列化表示丢失了场景图的结构信息,不利于LLM进行有效的推理。
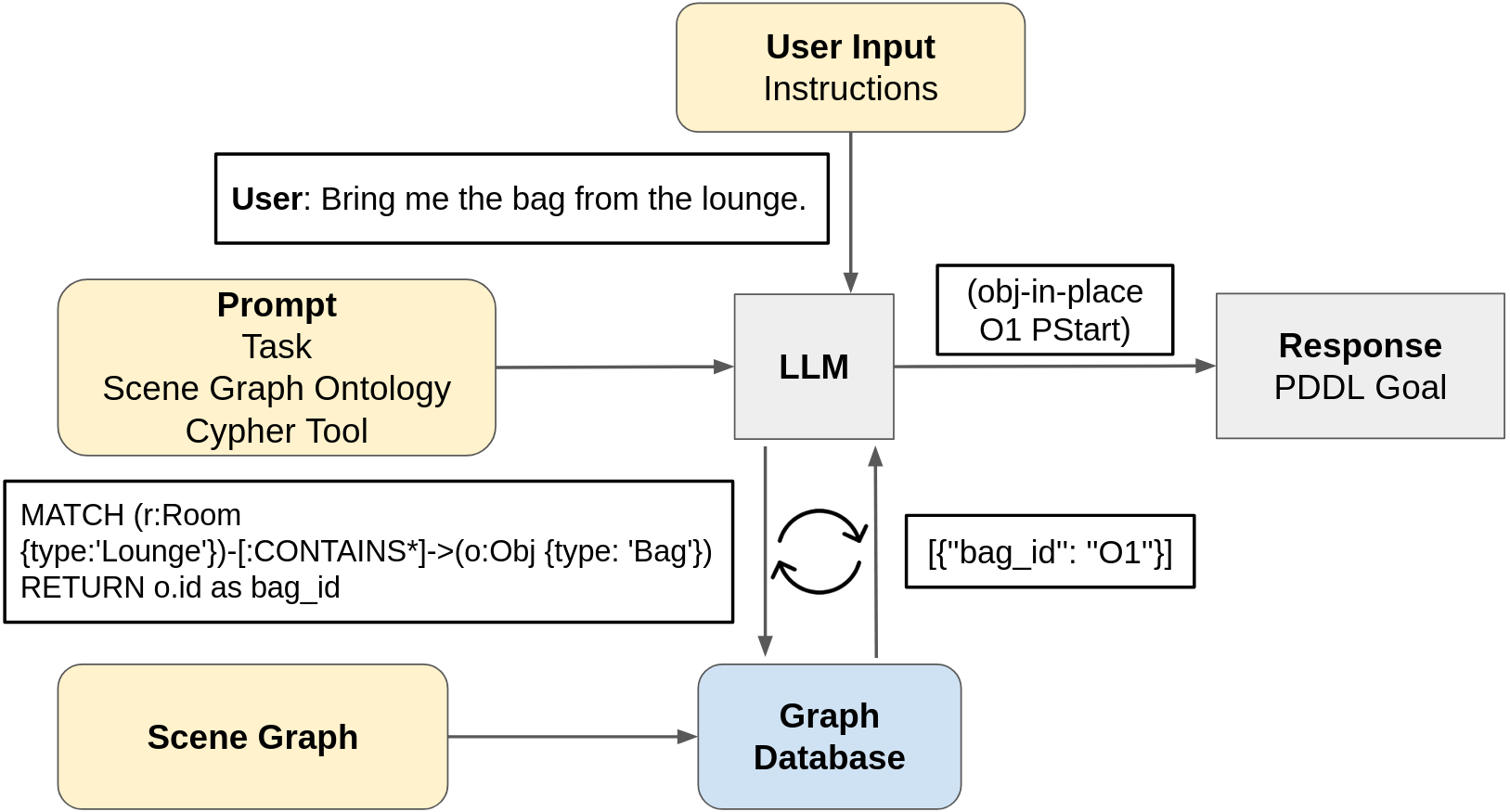
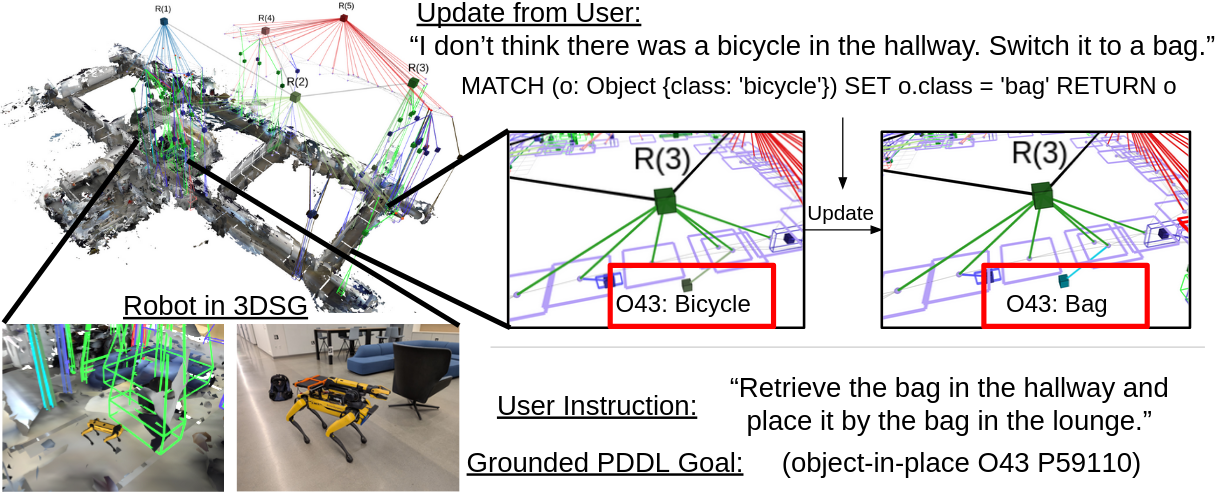
核心思路:本文的核心思路是利用检索增强生成(RAG),将3D场景图存储在图数据库中,并使用Cypher查询语言作为LLM与场景图之间的接口。LLM根据用户输入,生成Cypher查询语句,从图数据库中检索相关的场景信息,然后利用检索到的信息进行推理。这种方法避免了将整个场景图输入LLM,降低了计算复杂度,并保留了场景图的结构信息。
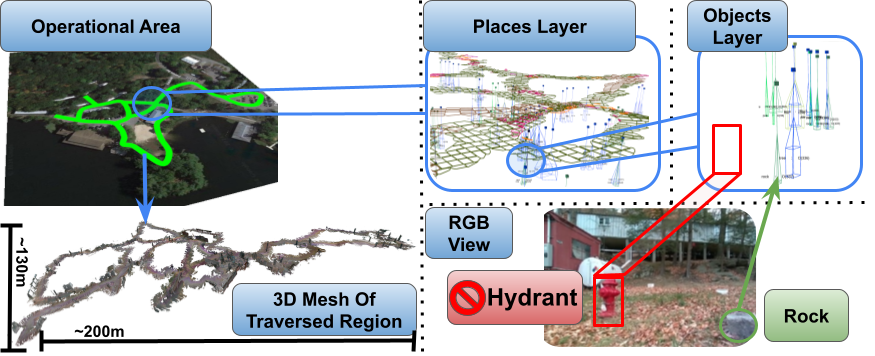
技术框架:该方法的技术框架主要包括以下几个模块:1) 3D场景图构建模块:将3D场景数据转换为图结构,节点表示对象,边表示对象之间的关系。2) 图数据库存储模块:将3D场景图存储在图数据库中,例如Neo4j。3) Cypher查询接口模块:提供Cypher查询语言接口,用于从图数据库中检索场景信息。4) LLM推理模块:LLM接收用户输入和检索到的场景信息,进行推理,生成相应的输出。
关键创新:该方法最重要的技术创新点在于使用结构化的Cypher查询语言作为LLM与3D场景图之间的接口。与直接将场景图序列化为文本相比,Cypher查询语言可以更有效地提取相关的场景信息,并保留场景图的结构信息。此外,该方法还利用了检索增强生成,避免了将整个场景图输入LLM,降低了计算复杂度。
关键设计:在具体实现中,需要设计合适的Cypher查询语句,以提取与用户输入相关的场景信息。例如,对于指令跟随任务,可以根据指令中的动词和对象,生成相应的Cypher查询语句。此外,还需要考虑如何将检索到的场景信息有效地融入LLM的输入中,例如可以使用prompt engineering技术。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用Cypher作为接口的方法在指令跟随和场景问答任务中,显著优于基线方法。在大型场景图上,该方法能够更好地扩展,并显著减少了token数量。例如,在某个任务中,该方法将token数量减少了50%,同时将性能提升了20%。
🎯 应用场景
该研究成果可广泛应用于机器人导航、智能家居、虚拟现实等领域。通过结合3D场景图和自然语言理解,机器人可以更好地理解人类指令,并在复杂环境中执行任务。例如,在智能家居中,用户可以通过语音指令控制机器人完成特定任务,如“把桌子上的苹果拿到厨房”。
📄 摘要(原文)
In order to provide a robot with the ability to understand and react to a user's natural language inputs, the natural language must be connected to the robot's underlying representations of the world. Recently, large language models (LLMs) and 3D scene graphs (3DSGs) have become a popular choice for grounding natural language and representing the world. In this work, we address the challenge of using LLMs with 3DSGs to ground natural language. Existing methods encode the scene graph as serialized text within the LLM's context window, but this encoding does not scale to large or rich 3DSGs. Instead, we propose to use a form of Retrieval Augmented Generation to select a subset of the 3DSG relevant to the task. We encode a 3DSG in a graph database and provide a query language interface (Cypher) as a tool to the LLM with which it can retrieve relevant data for language grounding. We evaluate our approach on instruction following and scene question-answering tasks and compare against baseline context window and code generation methods. Our results show that using Cypher as an interface to 3D scene graphs scales significantly better to large, rich graphs on both local and cloud-based models. This leads to large performance improvements in grounded language tasks while also substantially reducing the token count of the scene graph content. A video supplement is available at https://www.youtube.com/watch?v=zY_YI9giZSA.