NavQ: Learning a Q-Model for Foresighted Vision-and-Language Navigation
作者: Peiran Xu, Xicheng Gong, Yadong MU
分类: cs.CV, cs.RO
发布日期: 2025-10-18
备注: ICCV 2025
💡 一句话要点
NavQ:学习Q-模型以实现具有前瞻性的视觉-语言导航
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言导航 强化学习 Q-learning 前瞻性决策 跨模态融合
📋 核心要点
- 现有VLN方法依赖历史信息决策,缺乏对未来行动影响的考虑,导致导航效率降低。
- 提出NavQ,通过学习Q-模型预测未来潜在信息,为每个动作生成Q-特征,指导导航决策。
- 实验结果表明,NavQ能有效提升VLN任务的性能,验证了其在探索目标区域方面的优势。
📝 摘要(中文)
本文致力于解决面向目标的视觉-语言导航(VLN)任务。现有方法通常基于历史信息进行决策,忽略了行动的未来影响和长期结果。为了解决这个问题,我们旨在开发一种具有前瞻性的智能体。具体来说,我们利用Q-learning,使用大规模无标签轨迹数据训练一个Q-模型,以学习室内场景中关于布局和对象关系的一般知识。该模型可以为每个候选动作生成一个Q-特征,类似于传统Q网络中的Q值,描述了采取特定动作后可能观察到的潜在未来信息。随后,一个跨模态未来编码器将任务无关的Q-特征与导航指令集成,以产生一组反映未来前景的动作分数。这些分数与基于历史的原始分数相结合,有助于A*-风格的搜索策略,从而有效地探索更有可能通往目的地的区域。在广泛使用的面向目标的VLN数据集上进行的大量实验验证了所提出方法的有效性。
🔬 方法详解
问题定义:现有的视觉-语言导航(VLN)方法主要依赖于历史观测信息进行决策,缺乏对未来行动的预测和规划能力。这种短视的决策方式可能导致智能体陷入局部最优,无法有效地探索环境并到达目标位置。因此,如何让智能体具备前瞻性,能够预测未来行动的影响,是VLN任务中的一个重要挑战。
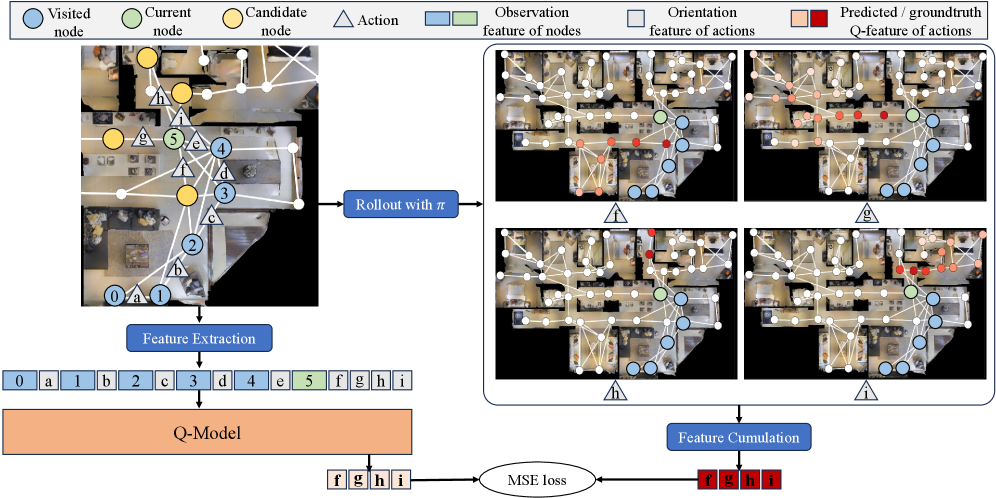
核心思路:本文的核心思路是借鉴强化学习中的Q-learning思想,训练一个Q-模型来预测每个动作的潜在未来价值。通过学习大规模无标签轨迹数据,Q-模型能够捕捉室内场景中布局和对象关系的一般知识。这样,智能体在做出决策时,不仅考虑当前观测,还能评估采取不同动作后可能获得的长期回报,从而做出更明智的选择。
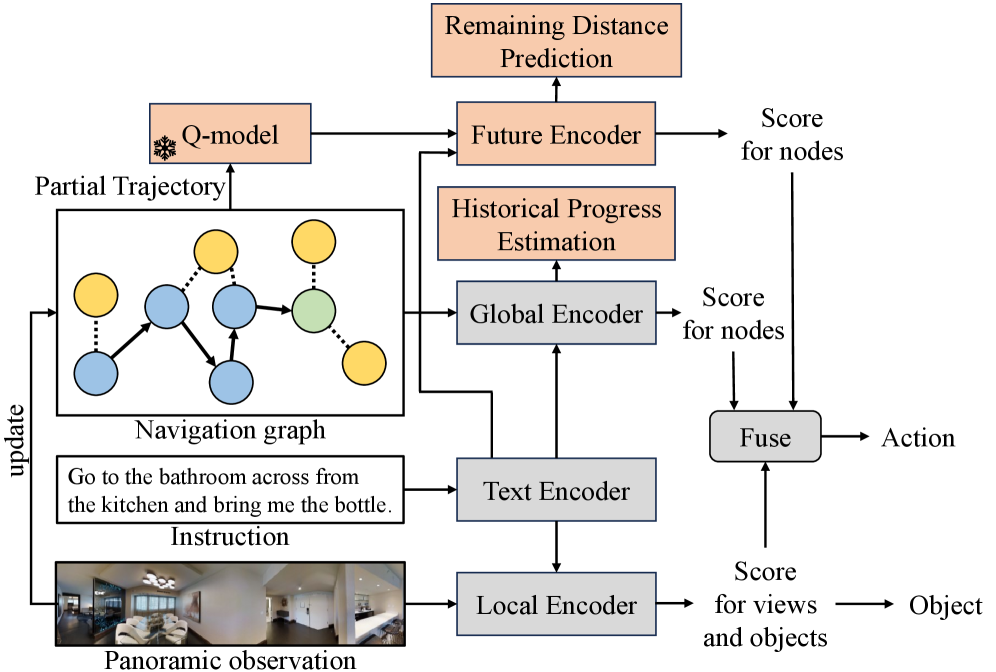
技术框架:NavQ的整体框架包括以下几个主要模块:1) Q-模型:使用大规模无标签轨迹数据训练,用于预测每个动作的Q-特征,代表未来潜在价值。2) 跨模态未来编码器:将Q-特征与导航指令进行融合,生成反映未来前景的动作分数。3) A-风格搜索策略:结合基于历史的原始分数和未来动作分数,指导智能体进行更有效的探索。整个流程可以概括为:输入视觉信息和导航指令 -> Q-模型生成Q-特征 -> 跨模态编码器融合信息 -> A搜索选择最优动作。
关键创新:NavQ的关键创新在于引入了Q-learning的思想,将VLN任务建模为一个序列决策问题,并学习一个Q-模型来预测未来价值。与现有方法相比,NavQ不再局限于历史观测,而是具备了预测未来行动影响的能力,从而能够做出更具有前瞻性的决策。此外,跨模态未来编码器的设计也使得Q-特征能够有效地与导航指令进行融合,指导动作选择。
关键设计:Q-模型的训练采用了大规模无标签轨迹数据,损失函数采用标准的Q-learning损失。跨模态未来编码器可以使用Transformer等结构,将Q-特征和导航指令进行编码和融合。A*搜索策略中的启发式函数可以结合历史信息和未来动作分数,以平衡探索和利用。具体的网络结构和参数设置需要根据具体的数据集和任务进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,NavQ在多个VLN数据集上取得了显著的性能提升。例如,在R2R数据集上,NavQ相较于基线方法,在成功率和路径长度方面均有明显改善。这些结果验证了NavQ在提升智能体导航能力方面的有效性,并证明了Q-模型在VLN任务中的潜力。
🎯 应用场景
NavQ的研究成果可应用于室内服务机器人、智能家居、虚拟现实导航等领域。通过提升机器人在复杂环境中的导航能力,可以实现更高效的物品递送、环境探索和用户引导。此外,该方法还可以扩展到其他需要长期规划和决策的任务中,例如自动驾驶、游戏AI等。
📄 摘要(原文)
In this work we concentrate on the task of goal-oriented Vision-and-Language Navigation (VLN). Existing methods often make decisions based on historical information, overlooking the future implications and long-term outcomes of the actions. In contrast, we aim to develop a foresighted agent. Specifically, we draw upon Q-learning to train a Q-model using large-scale unlabeled trajectory data, in order to learn the general knowledge regarding the layout and object relations within indoor scenes. This model can generate a Q-feature, analogous to the Q-value in traditional Q-network, for each candidate action, which describes the potential future information that may be observed after taking the specific action. Subsequently, a cross-modal future encoder integrates the task-agnostic Q-feature with navigation instructions to produce a set of action scores reflecting future prospects. These scores, when combined with the original scores based on history, facilitate an A*-style searching strategy to effectively explore the regions that are more likely to lead to the destination. Extensive experiments conducted on widely used goal-oriented VLN datasets validate the effectiveness of the proposed method.