VIPAMIN: Visual Prompt Initialization via Embedding Selection and Subspace Expansion
作者: Jaekyun Park, Hye Won Chung
分类: cs.CV, cs.LG
发布日期: 2025-10-18
备注: NeurIPS 2025
🔗 代码/项目: GITHUB
💡 一句话要点
VIPAMIN:通过嵌入选择和子空间扩展实现视觉Prompt初始化,提升自监督模型在下游任务的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉Prompt调优 自监督学习 嵌入选择 子空间扩展 Prompt初始化
📋 核心要点
- 现有视觉Prompt调优方法在自监督模型上表现不佳,尤其是在数据稀缺和任务难度高的场景下,Prompt的专业化和表示空间的丰富度不足。
- VIPAMIN的核心思想是通过嵌入选择将Prompt与语义信息丰富的区域对齐,并通过子空间扩展注入新的表示方向,从而增强模型的适应性。
- VIPAMIN仅需一次前向传递和轻量级操作,即可在各种任务和数据集大小上持续提升性能,并在视觉Prompt调优领域达到新的state-of-the-art。
📝 摘要(中文)
在大规模预训练模型时代,为每个下游任务完全微调预训练网络通常需要大量的资源。Prompt调优提供了一种轻量级的替代方案,它引入可调Prompt,同时保持骨干网络冻结。然而,现有的视觉Prompt调优方法通常无法专门化Prompt或丰富表示空间,尤其是在应用于自监督骨干网络时。我们表明,这些限制在具有挑战性的任务和数据稀缺的环境中变得尤为明显,而在这些情况下,有效的适应至关重要。在这项工作中,我们介绍了一种视觉Prompt初始化策略VIPAMIN,它通过以下方式增强自监督模型的适应性:(1)将Prompt与嵌入空间中语义信息丰富的区域对齐,以及(2)注入超出预训练子空间的新表示方向。尽管其简单性——仅需要一次前向传递和轻量级操作——VIPAMIN始终如一地提高了各种任务和数据集大小的性能,并在视觉Prompt调优中设置了新的技术水平。我们的代码可在https://github.com/iamjaekyun/vipamin获得。
🔬 方法详解
问题定义:现有的视觉Prompt调优方法在应用于自监督模型时,尤其是在数据稀缺和任务难度高的场景下,存在Prompt专业化不足和表示空间不够丰富的问题。这导致模型无法有效地适应下游任务,性能受到限制。
核心思路:VIPAMIN的核心思路是通过两个关键步骤来解决上述问题:首先,通过嵌入选择将Prompt初始化到嵌入空间中语义信息丰富的区域,确保Prompt能够捕捉到重要的特征。其次,通过子空间扩展,在Prompt中注入新的表示方向,使其能够表达超出预训练子空间的信息,从而增强模型的表达能力。
技术框架:VIPAMIN的整体流程包括以下几个步骤:1) 使用预训练的自监督模型提取输入图像的特征嵌入。2) 通过嵌入选择模块,从特征嵌入中选择具有代表性的区域作为Prompt的初始化值。3) 通过子空间扩展模块,在Prompt中添加新的表示方向,以增强其表达能力。4) 将初始化后的Prompt添加到输入图像中,并将其输入到冻结的预训练模型中进行下游任务的训练。
关键创新:VIPAMIN的关键创新在于其Prompt初始化策略,该策略结合了嵌入选择和子空间扩展,能够有效地提升自监督模型在下游任务中的适应性。与现有方法相比,VIPAMIN无需复杂的训练过程,仅需一次前向传递和轻量级操作即可实现显著的性能提升。
关键设计:嵌入选择模块通过计算特征嵌入之间的相似度,选择具有代表性的区域作为Prompt的初始化值。子空间扩展模块通过随机生成一组正交向量,并将它们添加到Prompt中,从而注入新的表示方向。具体实现细节包括相似度度量方式的选择、正交向量的生成方法以及Prompt的添加方式等。这些设计旨在确保Prompt能够捕捉到重要的特征,并具有足够的表达能力。
🖼️ 关键图片


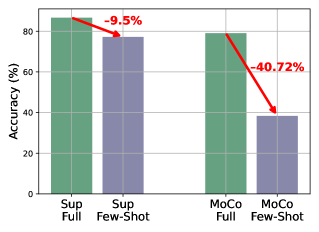
📊 实验亮点
VIPAMIN在多个视觉任务和数据集上取得了显著的性能提升,例如在ImageNet数据集上,VIPAMIN相比于现有的Prompt调优方法,取得了state-of-the-art的结果。即使在数据量较小的场景下,VIPAMIN也能展现出强大的适应能力,证明了其有效性和通用性。
🎯 应用场景
VIPAMIN具有广泛的应用前景,可应用于图像分类、目标检测、图像分割等各种计算机视觉任务。尤其适用于数据稀缺或计算资源有限的场景,能够帮助研究人员和开发者更高效地利用预训练的自监督模型,提升模型在下游任务中的性能。该方法还有潜力应用于其他模态的数据,例如文本和语音。
📄 摘要(原文)
In the era of large-scale foundation models, fully fine-tuning pretrained networks for each downstream task is often prohibitively resource-intensive. Prompt tuning offers a lightweight alternative by introducing tunable prompts while keeping the backbone frozen. However, existing visual prompt tuning methods often fail to specialize the prompts or enrich the representation space--especially when applied to self-supervised backbones. We show that these limitations become especially pronounced in challenging tasks and data-scarce settings, where effective adaptation is most critical. In this work, we introduce VIPAMIN, a visual prompt initialization strategy that enhances adaptation of self-supervised models by (1) aligning prompts with semantically informative regions in the embedding space, and (2) injecting novel representational directions beyond the pretrained subspace. Despite its simplicity--requiring only a single forward pass and lightweight operations--VIPAMIN consistently improves performance across diverse tasks and dataset sizes, setting a new state of the art in visual prompt tuning. Our code is available at https://github.com/iamjaekyun/vipamin.