EDVD-LLaMA: Explainable Deepfake Video Detection via Multimodal Large Language Model Reasoning
作者: Haoran Sun, Chen Cai, Huiping Zhuang, Kong Aik Lee, Lap-Pui Chau, Yi Wang
分类: cs.CV, cs.AI
发布日期: 2025-10-18 (更新: 2025-12-19)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出EDVD-LLaMA框架,通过多模态大语言模型推理实现可解释的深度伪造视频检测。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 深度伪造检测 多模态学习 大语言模型 可解释性 思维链 视频分析 时空特征 面部特征
📋 核心要点
- 现有深度伪造检测方法缺乏透明性,泛化能力不足,难以应对不断发展的伪造技术。
- EDVD-LLaMA框架通过时空信息Tokenization和细粒度多模态思维链,实现可解释的深度伪造视频检测。
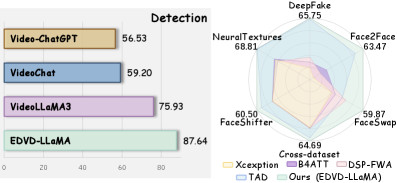
- 实验表明,EDVD-LLaMA在检测精度、可解释性和鲁棒性方面均优于现有方法,尤其在跨伪造和跨数据集场景下。
📝 摘要(中文)
深度伪造视频技术的快速发展在促进艺术创作的同时,也使得虚假信息的传播更加容易。传统的深度伪造视频检测(DVD)方法面临着原理缺乏透明性以及泛化能力不足等问题,难以应对不断演变的伪造技术。本文提出了可解释的深度伪造视频检测(EDVD)任务,并设计了EDVD-LLaMA多模态大语言模型(MLLM)推理框架,该框架在提供准确检测结果和可信解释的同时,还提供了可追溯的推理过程。该方法首先结合时空微妙信息Tokenization (ST-SIT)来提取和融合全局和局部跨帧深度伪造特征,为MLLM推理提供丰富的时空语义信息输入。其次,构建了细粒度多模态思维链(Fg-MCoT)机制,在推理过程中引入面部特征数据作为硬约束,以实现像素级时空视频定位,抑制幻觉输出,并增强思维链的可靠性。此外,构建了一个可解释推理FF++数据集(ER-FF++set),利用结构化数据来注释视频并确保质量控制,从而支持对推理和检测的双重监督。大量实验表明,EDVD-LLaMA在检测精度、可解释性以及处理跨伪造方法和跨数据集场景的能力方面均表现出卓越的性能和鲁棒性。与以往的DVD方法相比,它提供了一种更具解释性和更优越的解决方案。
🔬 方法详解
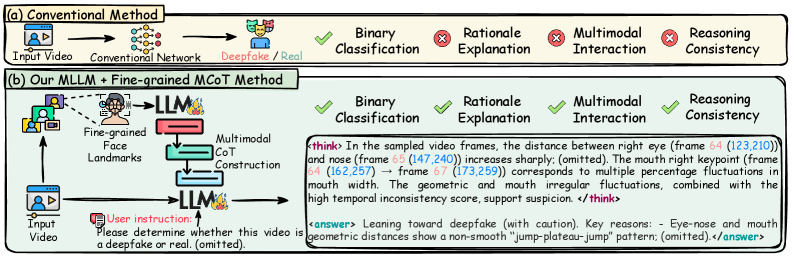
问题定义:当前深度伪造视频检测方法缺乏可解释性,难以让用户信任检测结果。同时,现有方法在面对新的伪造技术或跨数据集场景时,泛化能力不足,容易失效。因此,需要一种既能准确检测深度伪造视频,又能提供可信推理过程的检测方法。
核心思路:论文的核心思路是利用多模态大语言模型(MLLM)的推理能力,结合视频的时空特征和面部特征等信息,构建一个可解释的推理过程。通过思维链(Chain-of-Thought)的方式,让模型逐步推理并给出判断依据,从而提高检测结果的可信度。
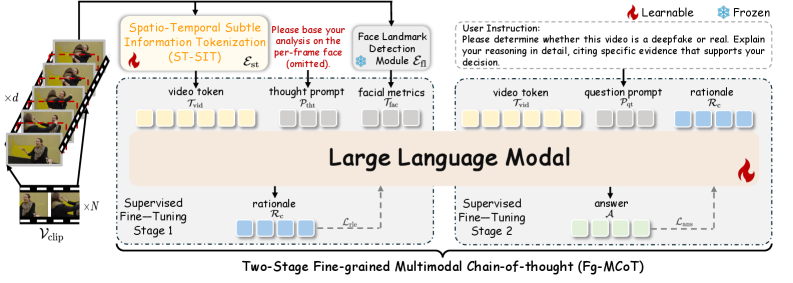
技术框架:EDVD-LLaMA框架主要包含以下几个模块: 1. 时空微妙信息Tokenization (ST-SIT):提取和融合视频的全局和局部跨帧深度伪造特征,为MLLM提供丰富的时空语义信息。 2. 细粒度多模态思维链(Fg-MCoT):在推理过程中引入面部特征数据作为硬约束,抑制幻觉输出,增强思维链的可靠性。 3. MLLM推理:利用大语言模型的推理能力,结合ST-SIT提取的特征和Fg-MCoT提供的约束,逐步推理并给出检测结果和解释。
关键创新:该论文的关键创新在于: 1. 提出了可解释的深度伪造视频检测(EDVD)任务。 2. 设计了EDVD-LLaMA多模态大语言模型推理框架,该框架能够提供可追溯的推理过程。 3. 构建了细粒度多模态思维链(Fg-MCoT)机制,利用面部特征数据作为硬约束,提高推理的可靠性。
关键设计: 1. ST-SIT模块:具体实现细节未知,但其目标是提取视频中的时空伪造痕迹。 2. Fg-MCoT模块:利用面部特征作为硬约束,具体实现方式未知,可能涉及到面部关键点检测、属性识别等技术。 3. ER-FF++set数据集:该数据集包含结构化标注,用于训练和评估模型的推理能力。具体标注方式未知,但需要支持对推理过程的监督。
🖼️ 关键图片
📊 实验亮点
实验结果表明,EDVD-LLaMA在检测精度、可解释性和鲁棒性方面均优于现有方法。尤其是在跨伪造方法和跨数据集场景下,EDVD-LLaMA表现出更强的泛化能力。具体性能数据未知,但论文强调了其在可解释性方面的显著提升。
🎯 应用场景
该研究成果可应用于新闻媒体、社交平台等领域,用于检测和识别深度伪造视频,防止虚假信息的传播。同时,该方法的可解释性使得用户能够理解检测结果的依据,增强了用户对检测系统的信任。未来,该技术可以进一步应用于数字身份验证、安全监控等领域。
📄 摘要(原文)
The rapid development of deepfake video technology has not only facilitated artistic creation but also made it easier to spread misinformation. Traditional deepfake video detection (DVD) methods face issues such as a lack of transparency in their principles and insufficient generalization capabilities to cope with evolving forgery techniques. This highlights an urgent need for detectors that can identify forged content and provide verifiable reasoning explanations. This paper proposes the explainable deepfake video detection (EDVD) task and designs the EDVD-LLaMA multimodal, a large language model (MLLM) reasoning framework, which provides traceable reasoning processes alongside accurate detection results and trustworthy explanations. Our approach first incorporates a Spatio-Temporal Subtle Information Tokenization (ST-SIT) to extract and fuse global and local cross-frame deepfake features, providing rich spatio-temporal semantic information input for MLLM reasoning. Second, we construct a Fine-grained Multimodal Chain-of-Thought (Fg-MCoT) mechanism, which introduces facial feature data as hard constraints during the reasoning process to achieve pixel-level spatio-temporal video localization, suppress hallucinated outputs, and enhance the reliability of the chain of thought. In addition, we build an Explainable Reasoning FF++ dataset (ER-FF++set), leveraging structured data to annotate videos and ensure quality control, thereby supporting dual supervision for reasoning and detection. Extensive experiments demonstrate that EDVD-LLaMA achieves outstanding performance and robustness in terms of detection accuracy, explainability, and its ability to handle cross-forgery methods and cross-dataset scenarios. Compared to previous DVD methods, it provides a more explainable and superior solution. The project page is available at: https://11ouo1.github.io/edvd-llama/.