Cerberus: Real-Time Video Anomaly Detection via Cascaded Vision-Language Models
作者: Yue Zheng, Xiufang Shi, Jiming Chen, Yuanchao Shu
分类: cs.CV, cs.CL
发布日期: 2025-10-18
💡 一句话要点
Cerberus:基于级联视觉-语言模型的实时视频异常检测系统
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频异常检测 视觉-语言模型 实时视频分析 运动掩码 规则推理 级联系统
📋 核心要点
- 现有基于视觉-语言模型的视频异常检测方法计算成本高昂,视觉基础性能不稳定,难以实现实时部署。
- Cerberus通过两阶段级联系统,结合轻量级过滤和细粒度VLM推理,实现高效准确的实时异常检测。
- Cerberus在NVIDIA L40S GPU上实现了57.68 fps,速度提升151.79倍,准确率达到97.2%,与SOTA方法相当。
📝 摘要(中文)
视频异常检测(VAD)随着视觉-语言模型(VLMs)的快速发展而取得了显著进展。虽然这些模型提供了卓越的零样本检测能力,但其巨大的计算成本和不稳定的视觉基础性能阻碍了实时部署。为了克服这些挑战,我们提出了Cerberus,一个为高效且准确的实时VAD设计的两阶段级联系统。Cerberus离线学习正常行为规则,并在在线推理期间结合轻量级过滤和细粒度的VLM推理。Cerberus的性能提升来自两个关键创新:运动掩码提示和基于规则的偏差检测。前者将VLM的注意力引导到与运动相关的区域,而后者将异常识别为与学习到的规范的偏差,而不是枚举可能的异常。在四个数据集上的广泛评估表明,Cerberus在NVIDIA L40S GPU上平均实现了57.68 fps,速度提升了151.79倍,并且达到了与最先进的基于VLM的VAD方法相当的97.2%的准确率,使其成为实时视频分析的实用解决方案。
🔬 方法详解
问题定义:视频异常检测旨在识别视频中不符合正常模式的事件。现有基于视觉-语言模型的方法虽然具有强大的零样本检测能力,但计算复杂度高,难以满足实时性要求。此外,视觉-语言模型的视觉 grounding 性能不稳定,影响了检测精度。
核心思路:Cerberus的核心思路是利用级联结构,首先通过轻量级的运动分析进行快速过滤,然后仅对可能存在异常的区域进行细粒度的视觉-语言推理。这种方法可以显著降低计算量,同时保证检测精度。通过学习正常行为的规则,将异常定义为与正常行为的偏差,避免了枚举所有可能的异常情况。
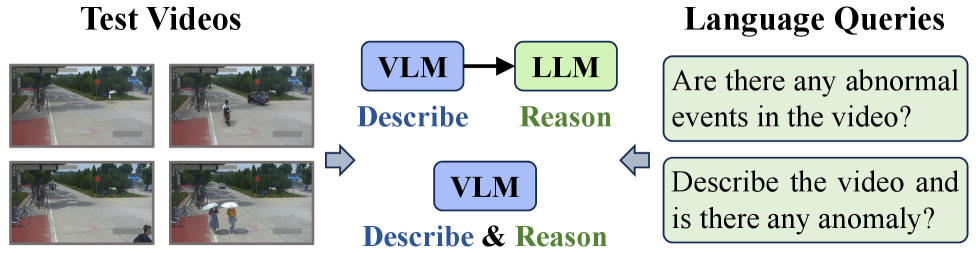
技术框架:Cerberus系统包含两个主要阶段:离线学习阶段和在线推理阶段。在离线学习阶段,系统学习正常行为的规则。在线推理阶段,首先使用运动掩码提示将VLM的注意力引导到与运动相关的区域,然后利用基于规则的偏差检测识别异常。整体流程为:输入视频帧 -> 运动掩码生成 -> 区域过滤 -> VLM推理 -> 异常检测。
关键创新:Cerberus的关键创新在于:1) 运动掩码提示,通过引导VLM关注运动区域,提高检测效率和精度;2) 基于规则的偏差检测,将异常定义为与正常行为的偏差,避免了枚举所有可能的异常,提高了泛化能力。
关键设计:运动掩码的生成方式未知,论文中未详细描述。基于规则的偏差检测的具体规则也未知,论文中未详细描述。VLM的具体选择也未知,论文中未详细描述。
🖼️ 关键图片

📊 实验亮点
Cerberus在四个数据集上进行了广泛评估,结果表明,该系统在NVIDIA L40S GPU上平均实现了57.68 fps,速度比现有基于VLM的VAD方法提高了151.79倍,同时保持了97.2%的准确率,与最先进的方法相当。这表明Cerberus在实时性和准确性方面都具有显著优势。
🎯 应用场景
Cerberus可应用于各种需要实时视频分析的场景,例如智能监控、工业安全、自动驾驶和医疗诊断。该系统能够快速准确地检测异常事件,从而提高安全性、效率和可靠性。未来,Cerberus可以扩展到处理更复杂的视频数据,并与其他智能系统集成,实现更高级的视频分析功能。
📄 摘要(原文)
Video anomaly detection (VAD) has rapidly advanced by recent development of Vision-Language Models (VLMs). While these models offer superior zero-shot detection capabilities, their immense computational cost and unstable visual grounding performance hinder real-time deployment. To overcome these challenges, we introduce Cerberus, a two-stage cascaded system designed for efficient yet accurate real-time VAD. Cerberus learns normal behavioral rules offline, and combines lightweight filtering with fine-grained VLM reasoning during online inference. The performance gains of Cerberus come from two key innovations: motion mask prompting and rule-based deviation detection. The former directs the VLM's attention to regions relevant to motion, while the latter identifies anomalies as deviations from learned norms rather than enumerating possible anomalies. Extensive evaluations on four datasets show that Cerberus on average achieves 57.68 fps on an NVIDIA L40S GPU, a 151.79$\times$ speedup, and 97.2\% accuracy comparable to the state-of-the-art VLM-based VAD methods, establishing it as a practical solution for real-time video analytics.