QDepth-VLA: Quantized Depth Prediction as Auxiliary Supervision for Vision-Language-Action Models
作者: Yixuan Li, Yuhui Chen, Mingcai Zhou, Haoran Li, Zhengtao Zhang, Dongbin Zhao
分类: cs.CV, cs.RO
发布日期: 2025-10-16 (更新: 2025-12-22)
💡 一句话要点
QDepth-VLA:利用量化深度预测作为视觉-语言-动作模型的辅助监督
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱四:生成式动作 (Generative Motion) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 深度预测 辅助监督 空间推理 机器人操作
📋 核心要点
- 现有的视觉-语言-动作模型在理解和推理精细操作任务所需的3D结构方面存在不足。
- QDepth-VLA通过引入深度预测作为辅助任务,使模型能够学习深度感知的空间表示,从而提升空间推理能力。
- 实验结果表明,QDepth-VLA在模拟和真实世界的操作任务中均取得了有竞争力的性能。
📝 摘要(中文)
本文提出QDepth-VLA,一个通用的框架,通过辅助深度预测任务来增强视觉-语言-动作(VLA)模型。该框架设计了一个专门的深度专家,用于预测从VQ-VAE编码器获得的深度图的量化潜在tokens,使模型能够学习捕获关键几何线索的深度感知表示。在模拟基准和真实世界任务上的实验结果表明,QDepth-VLA在操作任务上产生了强大的空间推理和有竞争力的性能。
🔬 方法详解
问题定义:现有的视觉-语言-动作(VLA)模型在执行精细操作任务时,缺乏对场景中3D结构的有效理解和推理能力。这限制了模型在需要精确控制的任务中的表现,例如机器人操作。现有方法难以充分利用图像中的深度信息,导致空间推理能力不足。
核心思路:本文的核心思路是将深度预测作为一个辅助任务引入VLA模型中。通过让模型学习预测场景的深度信息,可以增强模型对空间几何结构的理解,从而提升其在操作任务中的表现。这种方法利用深度信息作为一种监督信号,引导模型学习更丰富的空间表示。
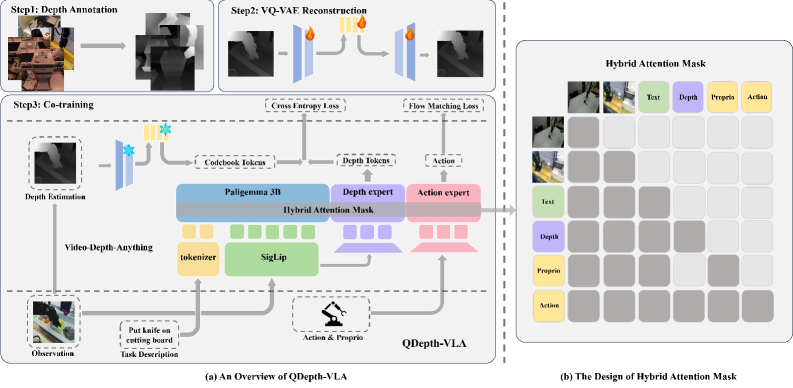
技术框架:QDepth-VLA框架包含一个VLA模型和一个深度专家。VLA模型负责执行视觉-语言-动作任务,深度专家则负责预测深度图的量化潜在tokens。深度图首先通过VQ-VAE编码器进行编码,得到量化的潜在tokens。深度专家学习预测这些tokens,从而学习深度信息。VLA模型的训练同时考虑操作任务的损失和深度预测的损失。
关键创新:该方法最重要的创新点在于将量化的深度预测作为VLA模型的辅助监督信号。通过使用VQ-VAE对深度图进行编码,可以将深度信息表示为离散的tokens,从而方便深度专家进行预测。这种方法避免了直接预测连续的深度值,降低了学习难度,并提高了模型的鲁棒性。
关键设计:深度专家通常是一个轻量级的神经网络,例如卷积神经网络或Transformer。深度预测的损失函数通常是交叉熵损失,用于衡量预测的深度tokens与真实tokens之间的差异。VQ-VAE的训练可以与VLA模型的训练联合进行,也可以预先训练好。关键参数包括VQ-VAE的码本大小、深度专家的网络结构和学习率等。
🖼️ 关键图片

📊 实验亮点
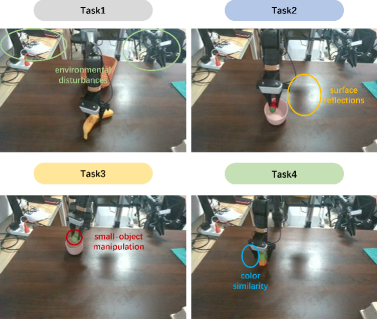
实验结果表明,QDepth-VLA在模拟和真实世界的操作任务中均取得了显著的性能提升。具体来说,QDepth-VLA在多个基准测试中超越了现有的VLA模型,并在真实世界的机器人操作任务中表现出强大的泛化能力。这些结果证明了深度预测作为辅助监督信号的有效性。
🎯 应用场景
QDepth-VLA框架可应用于各种需要精细操作的机器人任务,例如物体抓取、装配和操作。该方法可以提高机器人在复杂环境中的操作能力,使其能够更好地理解和利用场景中的3D信息。此外,该方法还可以应用于虚拟现实和增强现实等领域,提升用户与虚拟环境的交互体验。
📄 摘要(原文)
Spatial perception and reasoning are crucial for Vision-Language-Action (VLA) models to accomplish fine-grained manipulation tasks. However, existing approaches often lack the ability to understand and reason over the essential 3D structures necessary for precise control. To address this limitation, we propose QDepth-VLA, a general framework that augments VLA models with an auxiliary depth prediction task. A dedicated depth expert is designed to predict quantized latent tokens of depth maps obtained from a VQ-VAE encoder, enabling the model to learn depth-aware representations that capture critical geometric cues. Experimental results on the simulation benchmarks and real-world tasks demonstrate that QDepth-VLA yields strong spatial reasoning and competitive performance on manipulation tasks.