Accelerated Feature Detectors for Visual SLAM: A Comparative Study of FPGA vs GPU
作者: Ruiqi Ye, Mikel Luján
分类: cs.CV, cs.ET, cs.PF, cs.RO
发布日期: 2025-10-15
备注: 12 pages, 7 figures
💡 一句话要点
对比FPGA与GPU加速的特征检测器在视觉SLAM中的性能与能效
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视觉SLAM 特征检测 GPU加速 FPGA加速 硬件加速 性能评估 能效优化
📋 核心要点
- 视觉SLAM中的特征检测模块耗时较长,且越来越多地部署在无人机等功耗受限的平台上,需要高效的加速方案。
- 本文对比研究了GPU和FPGA加速的FAST、Harris和SuperPoint特征检测器在V-SLAM中的性能和能效。
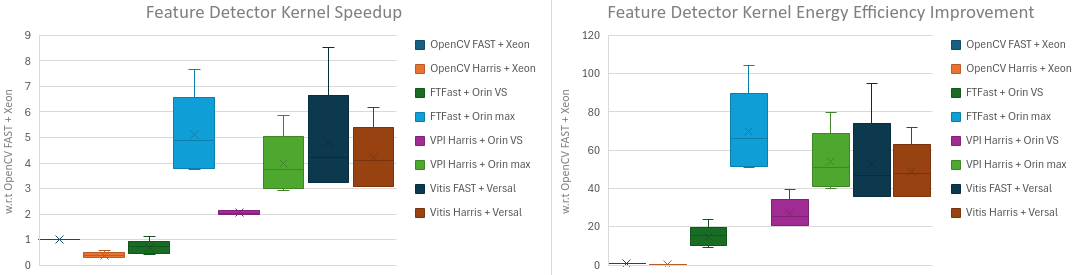
- 实验结果表明,非学习型检测器GPU加速更优,学习型检测器FPGA加速更优,且硬件加速能提升V-SLAM整体性能。
📝 摘要(中文)
本文首次研究了硬件加速的特征检测器在视觉SLAM(V-SLAM)流水线中的应用。通过在现代SoC(Nvidia Jetson Orin和AMD Versal)上比较GPU加速的FAST、Harris和SuperPoint实现与FPGA加速的对应实现,提供了新的见解。评估表明,对于非学习型特征检测器(如FAST和Harris),其GPU实现以及GPU加速的V-SLAM在运行时性能和能效方面优于FPGA实现。然而,对于学习型检测器(如SuperPoint),其FPGA实现可以实现更好的运行时性能和能效(分别高达3.1倍和1.4倍的提升)。FPGA加速的V-SLAM在运行时性能方面与GPU加速的V-SLAM相当,在5个数据集序列中的2个中具有更好的FPS。在精度方面,GPU加速的V-SLAM通常比FPGA加速的V-SLAM更准确。最后,硬件加速特征检测可以进一步提高V-SLAM流水线的性能,减少全局BA模块的调用频率而不牺牲精度。
🔬 方法详解
问题定义:视觉SLAM中的特征检测是计算密集型任务,尤其是在资源受限的平台上,如何高效地加速特征检测过程,以满足实时性和低功耗的需求,是本文要解决的核心问题。现有方法主要依赖于CPU或GPU,但在特定场景下可能存在性能瓶颈或能效问题。
核心思路:本文的核心思路是探索FPGA在加速特征检测方面的潜力,并与GPU进行对比。通过针对不同类型的特征检测器(传统算法和深度学习算法)选择合适的硬件加速平台,以实现最佳的性能和能效。
技术框架:本文的整体框架包括以下几个主要步骤:1) 选择代表性的特征检测算法(FAST、Harris、SuperPoint);2) 分别在GPU(Nvidia Jetson Orin)和FPGA(AMD Versal)上实现这些算法的加速版本;3) 将加速后的特征检测模块集成到V-SLAM流水线中;4) 在多个数据集上评估V-SLAM的性能(运行时、能效、精度)。
关键创新:本文的关键创新在于首次系统性地对比了GPU和FPGA在加速V-SLAM特征检测方面的性能,并针对不同类型的特征检测器给出了硬件加速平台的选择建议。特别地,本文发现对于学习型特征检测器(如SuperPoint),FPGA加速可以实现比GPU加速更好的性能和能效。
关键设计:对于FPGA加速,作者可能采用了定制化的硬件架构来优化数据流和计算过程,例如使用流水线和并行计算来提高吞吐量。对于SuperPoint等深度学习模型,可能采用了模型量化、剪枝等技术来降低计算复杂度和内存占用。具体的参数设置和网络结构细节可能依赖于所使用的FPGA开发工具和硬件平台。
🖼️ 关键图片


📊 实验亮点
实验结果表明,对于非学习型特征检测器,GPU加速的V-SLAM性能和能效更优。而对于学习型特征检测器SuperPoint,FPGA加速的性能和能效分别提升高达3.1倍和1.4倍。在精度方面,GPU加速的V-SLAM总体上更准确。硬件加速特征检测能减少全局BA模块调用频率而不牺牲精度。
🎯 应用场景
该研究成果可应用于无人机、机器人、增强现实等领域,尤其是在资源受限的移动平台上。通过选择合适的硬件加速方案,可以提高V-SLAM系统的实时性和能效,从而扩展其应用范围,例如在低功耗无人机上实现更复杂的导航和避障功能。
📄 摘要(原文)
Feature detection is a common yet time-consuming module in Simultaneous Localization and Mapping (SLAM) implementations, which are increasingly deployed on power-constrained platforms, such as drones. Graphics Processing Units (GPUs) have been a popular accelerator for computer vision in general, and feature detection and SLAM in particular. On the other hand, System-on-Chips (SoCs) with integrated Field Programmable Gate Array (FPGA) are also widely available. This paper presents the first study of hardware-accelerated feature detectors considering a Visual SLAM (V-SLAM) pipeline. We offer new insights by comparing the best GPU-accelerated FAST, Harris, and SuperPoint implementations against the FPGA-accelerated counterparts on modern SoCs (Nvidia Jetson Orin and AMD Versal). The evaluation shows that when using a non-learning-based feature detector such as FAST and Harris, their GPU implementations, and the GPU-accelerated V-SLAM can achieve better run-time performance and energy efficiency than the FAST and Harris FPGA implementations as well as the FPGA-accelerated V-SLAM. However, when considering a learning-based detector such as SuperPoint, its FPGA implementation can achieve better run-time performance and energy efficiency (up to 3.1$\times$ and 1.4$\times$ improvements, respectively) than the GPU implementation. The FPGA-accelerated V-SLAM can also achieve comparable run-time performance compared to the GPU-accelerated V-SLAM, with better FPS in 2 out of 5 dataset sequences. When considering the accuracy, the results show that the GPU-accelerated V-SLAM is more accurate than the FPGA-accelerated V-SLAM in general. Last but not least, the use of hardware acceleration for feature detection could further improve the performance of the V-SLAM pipeline by having the global bundle adjustment module invoked less frequently without sacrificing accuracy.