CrossRay3D: Geometry and Distribution Guidance for Efficient Multimodal 3D Detection
作者: Huiming Yang, Wenzhuo Liu, Yicheng Qiao, Lei Yang, Xianzhu Zeng, Li Wang, Zhiwei Li, Zijian Zeng, Zhiying Jiang, Huaping Liu, Kunfeng Wang
分类: cs.CV
发布日期: 2025-10-14 (更新: 2025-11-04)
备注: 13 pages
💡 一句话要点
CrossRay3D:利用几何与分布引导的高效多模态3D检测
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态3D检测 稀疏检测器 几何信息 类别平衡 射线感知监督 自动驾驶 nuScenes数据集
📋 核心要点
- 现有稀疏多模态3D检测器忽略了token表征的质量,导致检测性能受限,尤其是在小物体检测方面。
- CrossRay3D通过引入射线感知监督和类别平衡监督,增强token表征的几何信息和类别语义,从而提升检测性能。
- CrossRay3D在nuScenes数据集上取得了领先的性能,并且在数据缺失的情况下表现出良好的鲁棒性,同时保持了较高的效率。
📝 摘要(中文)
本文提出了一种名为CrossRay3D的端到端稀疏多模态3D检测器,旨在解决现有稀疏检测器token表征质量不佳,导致前景质量次优和性能受限的问题。该方法通过引入稀疏选择器(SS)来提升token表征,SS的核心模块是射线感知监督(RAS),它在训练阶段保留丰富的几何信息,以及类别平衡监督,自适应地重新加权类别语义的显著性,确保与小物体相关的token在token采样过程中被保留。此外,设计了射线位置编码(Ray PE)来解决激光雷达模态和图像之间的分布差异。在nuScenes基准测试中,CrossRay3D取得了state-of-the-art的性能,mAP达到72.4,NDS达到74.7,并且比其他领先方法快1.84倍。CrossRay3D在激光雷达或相机数据部分或完全缺失的情况下也表现出强大的鲁棒性。
🔬 方法详解
问题定义:现有的稀疏多模态3D检测器在token表征质量上存在不足,导致前景质量较差,尤其是在小物体检测方面,最终限制了整体的检测性能。这些方法没有充分利用几何结构信息,并且对不同类别的语义信息处理不够平衡。
核心思路:论文的核心思路是通过保留丰富的几何信息和平衡类别语义来提升token表征的质量。具体来说,通过射线感知监督(RAS)来保留几何信息,并通过类别平衡监督来确保小物体相关的token被保留。此外,还考虑了激光雷达和图像模态之间的分布差异。
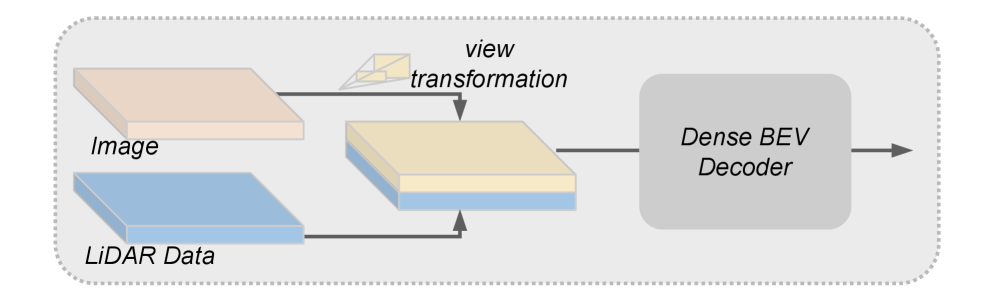
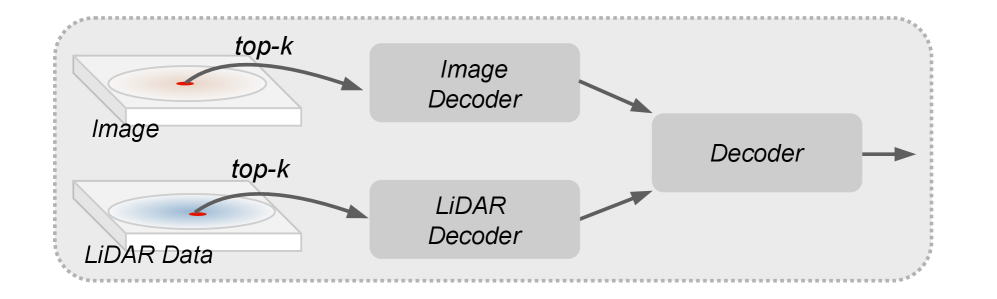
技术框架:CrossRay3D是一个端到端的稀疏多模态3D检测器。其主要模块包括:1) 特征提取模块(从激光雷达和图像数据中提取特征);2) 稀疏选择器(SS),包含射线感知监督(RAS)和类别平衡监督;3) 射线位置编码(Ray PE);4) 检测头(用于最终的3D目标检测)。整体流程是首先提取多模态特征,然后通过SS选择高质量的token,利用Ray PE进行位置编码,最后通过检测头进行目标检测。
关键创新:论文的关键创新在于提出了稀疏选择器(SS),它通过射线感知监督(RAS)和类别平衡监督来提升token表征的质量。RAS通过在训练阶段引入射线信息,保留了丰富的几何结构。类别平衡监督则自适应地调整不同类别的权重,确保小物体相关的token被保留。与现有方法相比,CrossRay3D更注重token表征的质量,从而提升了检测性能。
关键设计:射线感知监督(RAS)通过计算每个token与其对应射线之间的距离来引入几何信息。类别平衡监督通过计算每个类别的样本数量,并根据样本数量调整损失函数的权重,从而平衡不同类别之间的影响。射线位置编码(Ray PE)通过将射线信息编码到位置信息中,来解决激光雷达和图像模态之间的分布差异。损失函数包括分类损失、回归损失和方向损失。
🖼️ 关键图片

📊 实验亮点
CrossRay3D在nuScenes数据集上取得了state-of-the-art的性能,mAP达到72.4,NDS达到74.7,并且比其他领先方法快1.84倍。此外,CrossRay3D在激光雷达或相机数据部分或完全缺失的情况下也表现出强大的鲁棒性,证明了其在复杂环境下的适应能力。
🎯 应用场景
CrossRay3D可应用于自动驾驶、机器人导航、智能交通等领域。通过提高3D目标检测的精度和效率,可以提升自动驾驶系统的安全性,增强机器人对周围环境的感知能力,并优化交通管理系统的效率。该研究对于推动智能交通系统的发展具有重要意义。
📄 摘要(原文)
The sparse cross-modality detector offers more advantages than its counterpart, the Bird's-Eye-View (BEV) detector, particularly in terms of adaptability for downstream tasks and computational cost savings. However, existing sparse detectors overlook the quality of token representation, leaving it with a sub-optimal foreground quality and limited performance. In this paper, we identify that the geometric structure preserved and the class distribution are the key to improving the performance of the sparse detector, and propose a Sparse Selector (SS). The core module of SS is Ray-Aware Supervision (RAS), which preserves rich geometric information during the training stage, and Class-Balanced Supervision, which adaptively reweights the salience of class semantics, ensuring that tokens associated with small objects are retained during token sampling. Thereby, outperforming other sparse multi-modal detectors in the representation of tokens. Additionally, we design Ray Positional Encoding (Ray PE) to address the distribution differences between the LiDAR modality and the image. Finally, we integrate the aforementioned module into an end-to-end sparse multi-modality detector, dubbed CrossRay3D. Experiments show that, on the challenging nuScenes benchmark, CrossRay3D achieves state-of-the-art performance with 72.4 mAP and 74.7 NDS, while running 1.84 faster than other leading methods. Moreover, CrossRay3D demonstrates strong robustness even in scenarios where LiDAR or camera data are partially or entirely missing.