DriveVLA-W0: World Models Amplify Data Scaling Law in Autonomous Driving
作者: Yingyan Li, Shuyao Shang, Weisong Liu, Bing Zhan, Haochen Wang, Yuqi Wang, Yuntao Chen, Xiaoman Wang, Yasong An, Chufeng Tang, Lu Hou, Lue Fan, Zhaoxiang Zhang
分类: cs.CV, cs.AI
发布日期: 2025-10-14 (更新: 2025-12-18)
💡 一句话要点
DriveVLA-W0:利用世界模型放大自动驾驶中的数据缩放定律
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 视觉-语言-动作模型 世界模型 自监督学习 数据缩放定律
📋 核心要点
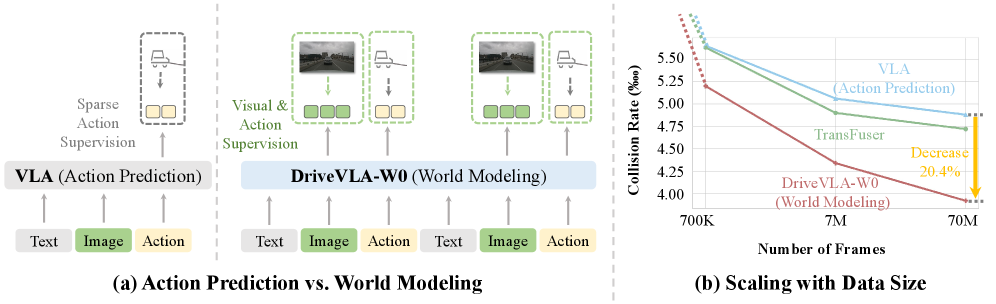
- 现有VLA模型面临“监督不足”问题,模型容量远大于稀疏动作监督信号,导致表征能力未充分利用。
- DriveVLA-W0通过世界建模预测未来图像,生成密集的自监督信号,驱动模型学习驾驶环境动态。
- 实验表明,DriveVLA-W0显著优于BEV和VLA基线,并有效放大数据缩放定律,提升性能。
📝 摘要(中文)
大规模视觉-语言-动作(VLA)模型为实现更通用的驾驶智能提供了一条有希望的途径。然而,VLA模型受到“监督不足”的限制:庞大的模型容量由稀疏的、低维的动作进行监督,导致其大部分表征能力未被充分利用。为了解决这个问题,我们提出了DriveVLA-W0,一种利用世界建模来预测未来图像的训练范式。这项任务生成了一个密集的、自监督的信号,迫使模型学习驾驶环境的潜在动态。我们通过为两种主要的VLA原型实例化它来展示该范式的多功能性:用于使用离散视觉token的VLA的自回归世界模型,以及用于在连续视觉特征上操作的VLA的扩散世界模型。在从世界建模中学习到的丰富表征的基础上,我们引入了一个轻量级的动作专家来解决实时部署的推理延迟问题。在NAVSIM v1/v2基准测试和一个大680倍的内部数据集上的大量实验表明,DriveVLA-W0显著优于BEV和VLA基线。至关重要的是,它放大了数据缩放定律,表明随着训练数据集大小的增加,性能增益会加速。
🔬 方法详解
问题定义:现有的视觉-语言-动作(VLA)模型在自动驾驶领域面临着“监督不足”的问题。具体来说,这些模型拥有巨大的参数量和表征能力,但训练时主要依赖于稀疏的、低维的动作指令作为监督信号。这种监督信号的匮乏导致模型无法充分学习驾驶环境的复杂动态,限制了其泛化能力和性能表现。现有方法难以有效利用大规模数据集的潜力。
核心思路:DriveVLA-W0的核心思路是引入世界模型,通过预测未来图像来生成密集的自监督信号。世界模型能够学习环境的潜在动态,从而为VLA模型提供更丰富、更全面的监督信息。这种自监督学习方式可以有效弥补动作监督的不足,提升模型的表征能力和泛化性能。通过预测未来,模型能够更好地理解环境变化,从而做出更合理的决策。
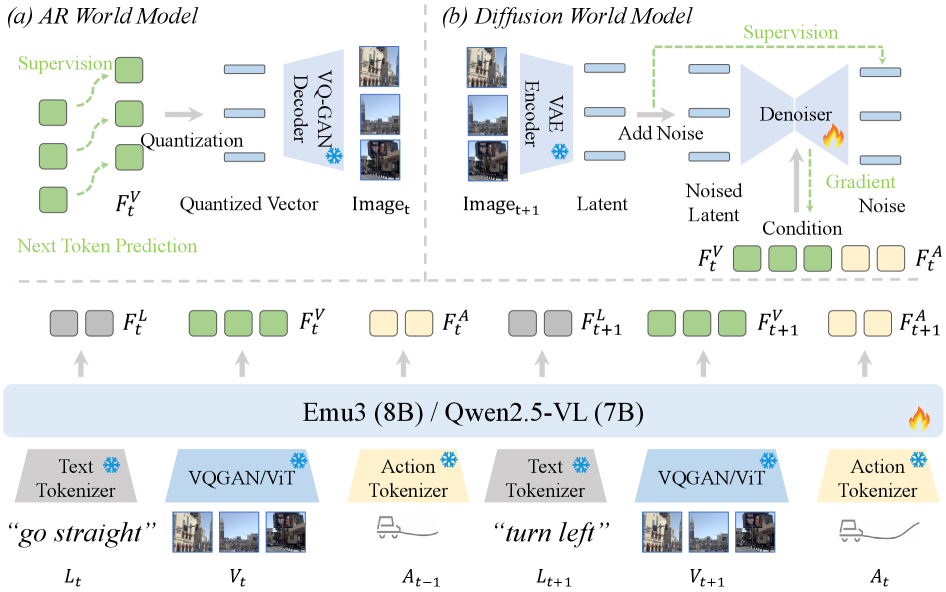
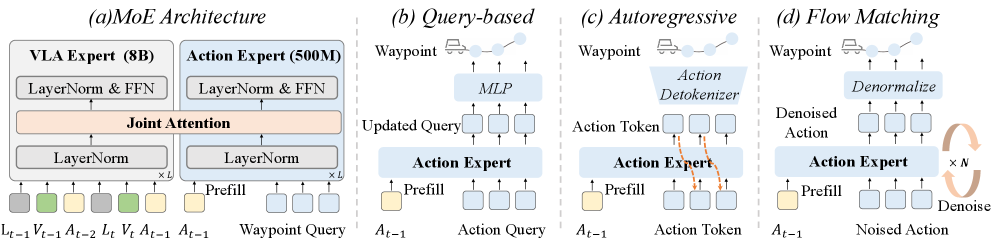
技术框架:DriveVLA-W0的整体框架包括两个主要部分:世界模型和动作专家。首先,利用大规模驾驶数据训练世界模型,使其能够预测未来图像。世界模型可以采用自回归模型(用于离散视觉token)或扩散模型(用于连续视觉特征)。然后,基于世界模型学习到的丰富表征,训练一个轻量级的动作专家,用于预测车辆的控制指令。动作专家旨在降低推理延迟,满足实时部署的需求。
关键创新:DriveVLA-W0最重要的创新点在于将世界建模引入到VLA模型的训练中,通过预测未来图像来生成密集的自监督信号。与传统的基于动作监督的方法相比,DriveVLA-W0能够更有效地利用大规模数据集,学习驾驶环境的潜在动态,从而提升模型的表征能力和泛化性能。此外,轻量级动作专家的设计也保证了模型的实时性。
关键设计:DriveVLA-W0的关键设计包括:1) 针对不同VLA模型选择合适的的世界模型架构(自回归或扩散模型);2) 设计合适的损失函数,用于训练世界模型,例如像素级别的重构损失或感知损失;3) 设计轻量级的动作专家网络结构,例如使用卷积神经网络或Transformer;4) 优化训练策略,例如使用 curriculum learning 或 adversarial training 来提升模型的鲁棒性。
🖼️ 关键图片
📊 实验亮点
DriveVLA-W0在NAVSIM v1/v2基准测试和一个大680倍的内部数据集上进行了广泛的实验。实验结果表明,DriveVLA-W0显著优于BEV和VLA基线。更重要的是,DriveVLA-W0放大了数据缩放定律,表明随着训练数据集大小的增加,性能增益会加速。这表明DriveVLA-W0能够更有效地利用大规模数据集,从而实现更高的性能。
🎯 应用场景
DriveVLA-W0具有广泛的应用前景,可用于提升自动驾驶系统的性能和安全性。该方法可以应用于各种自动驾驶场景,例如城市道路、高速公路和越野环境。通过学习驾驶环境的潜在动态,DriveVLA-W0可以帮助自动驾驶系统更好地理解环境变化,做出更合理的决策,从而提高驾驶安全性。此外,该方法还可以用于训练更强大的驾驶辅助系统,例如自动泊车和车道保持。
📄 摘要(原文)
Scaling Vision-Language-Action (VLA) models on large-scale data offers a promising path to achieving a more generalized driving intelligence. However, VLA models are limited by a ``supervision deficit'': the vast model capacity is supervised by sparse, low-dimensional actions, leaving much of their representational power underutilized. To remedy this, we propose \textbf{DriveVLA-W0}, a training paradigm that employs world modeling to predict future images. This task generates a dense, self-supervised signal that compels the model to learn the underlying dynamics of the driving environment. We showcase the paradigm's versatility by instantiating it for two dominant VLA archetypes: an autoregressive world model for VLAs that use discrete visual tokens, and a diffusion world model for those operating on continuous visual features. Building on the rich representations learned from world modeling, we introduce a lightweight action expert to address the inference latency for real-time deployment. Extensive experiments on the NAVSIM v1/v2 benchmark and a 680x larger in-house dataset demonstrate that DriveVLA-W0 significantly outperforms BEV and VLA baselines. Crucially, it amplifies the data scaling law, showing that performance gains accelerate as the training dataset size increases.