ViCO: A Training Strategy towards Semantic Aware Dynamic High-Resolution
作者: Long Cui, Weiyun Wang, Jie Shao, Zichen Wen, Gen Luo, Linfeng Zhang, Yanting Zhang, Yu Qiao, Wenhai Wang
分类: cs.CV
发布日期: 2025-10-14 (更新: 2025-12-15)
💡 一句话要点
ViCO:面向语义感知的动态高分辨率多模态大模型训练策略
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大模型 视觉tokens 动态分辨率 语义感知 视觉一致性学习
📋 核心要点
- 现有多模态大模型因图像输入引入大量视觉tokens,导致推理成本显著增加,限制了其应用。
- ViCO通过多个MLP连接器根据图像语义复杂度动态调整视觉tokens数量,实现高效的图像表示。
- 实验表明,ViCO能在保持模型性能的同时,显著减少视觉tokens数量,降低计算成本。
📝 摘要(中文)
本文提出了一种名为视觉一致性学习(ViCO)的训练算法,旨在解决多模态大语言模型(MLLM)因图像输入引入额外视觉tokens而导致的推理成本增加问题。ViCO的核心思想是利用多个具有不同图像压缩比的MLP连接器,根据图像的语义复杂性对视觉tokens进行下采样。在训练过程中,ViCO最小化以不同MLP连接器为条件的响应之间的KL散度。在推理时,引入一个名为视觉分辨率路由器(ViR)的图像路由器,自动为每个图像块选择合适的压缩率。实验结果表明,该方法可以在保持模型感知、推理和OCR能力的同时,减少高达50%的视觉tokens。该研究旨在推动更高效的MLLM的发展。
🔬 方法详解
问题定义:现有多模态大语言模型(MLLM)在处理图像输入时,需要将图像转换为视觉tokens。图像分辨率越高,视觉tokens的数量就越多,从而导致推理成本显著增加。现有的动态高分辨率策略主要基于图像分辨率调整视觉tokens数量,忽略了图像的语义复杂性,可能导致计算资源的浪费。
核心思路:ViCO的核心思路是根据图像的语义复杂性动态调整视觉tokens的数量。对于语义简单的图像区域,使用较少的视觉tokens即可充分表达;对于语义复杂的区域,则需要更多的视觉tokens。通过这种方式,可以在保证模型性能的同时,减少视觉tokens的总数,从而降低计算成本。
技术框架:ViCO的整体框架包括多个MLP连接器和一个视觉分辨率路由器(ViR)。每个MLP连接器具有不同的图像压缩比,用于将图像转换为不同数量的视觉tokens。在训练阶段,模型使用不同的MLP连接器处理同一图像,并通过最小化不同连接器输出之间的KL散度来学习视觉一致性。在推理阶段,ViR根据图像块的语义复杂性,自动选择合适的MLP连接器进行处理。
关键创新:ViCO的关键创新在于其语义感知的动态高分辨率策略。与现有方法不同,ViCO不是基于图像分辨率,而是基于图像的语义复杂性来调整视觉tokens的数量。这种方法能够更有效地利用计算资源,并在保证模型性能的同时,显著降低计算成本。
关键设计:ViCO的关键设计包括:1) 多个具有不同压缩比的MLP连接器,用于生成不同数量的视觉tokens;2) KL散度损失函数,用于保证不同MLP连接器输出的一致性;3) 视觉分辨率路由器(ViR),用于在推理阶段自动选择合适的MLP连接器。ViR的具体实现方式未知,论文中可能未详细描述。
🖼️ 关键图片

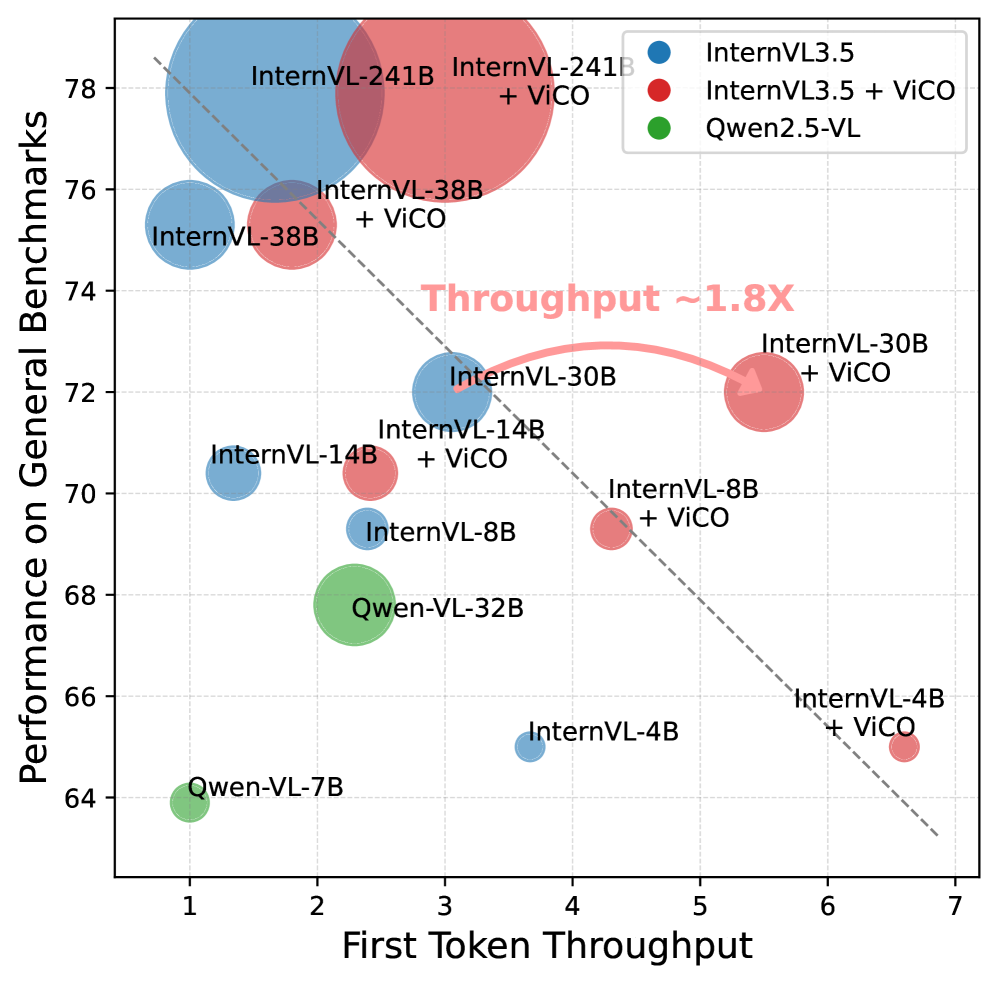

📊 实验亮点
实验结果表明,ViCO可以在保持模型感知、推理和OCR能力的同时,减少高达50%的视觉tokens。这意味着在相同的计算资源下,模型可以处理更高分辨率的图像,或者在相同的图像分辨率下,可以显著降低计算成本。具体的性能数据和对比基线未知,需要参考论文原文。
🎯 应用场景
ViCO具有广泛的应用前景,可用于各种需要处理图像输入的多模态大语言模型,例如图像描述、视觉问答、视觉推理等。通过降低计算成本,ViCO可以使这些模型更容易部署在资源受限的设备上,并提高其在实际应用中的效率。此外,ViCO还可以促进多模态大模型在移动设备、嵌入式系统等领域的应用。
📄 摘要(原文)
Existing Multimodal Large Language Models (MLLMs) suffer from increased inference costs due to the additional vision tokens introduced by image inputs. In this work, we propose Visual Consistency Learning (ViCO), a novel training algorithm that enables the model to represent images of varying semantic complexities using different numbers of vision tokens. The key idea behind our method is to employ multiple MLP connectors, each with a different image compression ratio, to downsample the vision tokens based on the semantic complexity of the image. During training, we minimize the KL divergence between the responses conditioned on different MLP connectors. At inference time, we introduce an image router, termed Visual Resolution Router (ViR), that automatically selects the appropriate compression rate for each image patch. Compared with existing dynamic high-resolution strategies, which adjust the number of visual tokens based on image resolutions, our method dynamically adapts the number of visual tokens according to semantic complexity. Experimental results demonstrate that our method can reduce the number of vision tokens by up to 50% while maintaining the model's perception, reasoning, and OCR capabilities. We hope this work will contribute to the development of more efficient MLLMs. The code and models will be released to facilitate future research.