SRUM: Fine-Grained Self-Rewarding for Unified Multimodal Models
作者: Weiyang Jin, Yuwei Niu, Jiaqi Liao, Chengqi Duan, Aoxue Li, Shenghua Gao, Xihui Liu
分类: cs.CV, cs.CL
发布日期: 2025-10-14
备注: 20 pages, 8 figures, webpage can be seen in https://waynejin0918.github.io/srum_web/
💡 一句话要点
提出SRUM:一种用于统一多模态模型的细粒度自奖励框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 统一多模态模型 自奖励学习 文本到图像生成 视觉理解 全局-局部奖励 后训练 图像生成质量
📋 核心要点
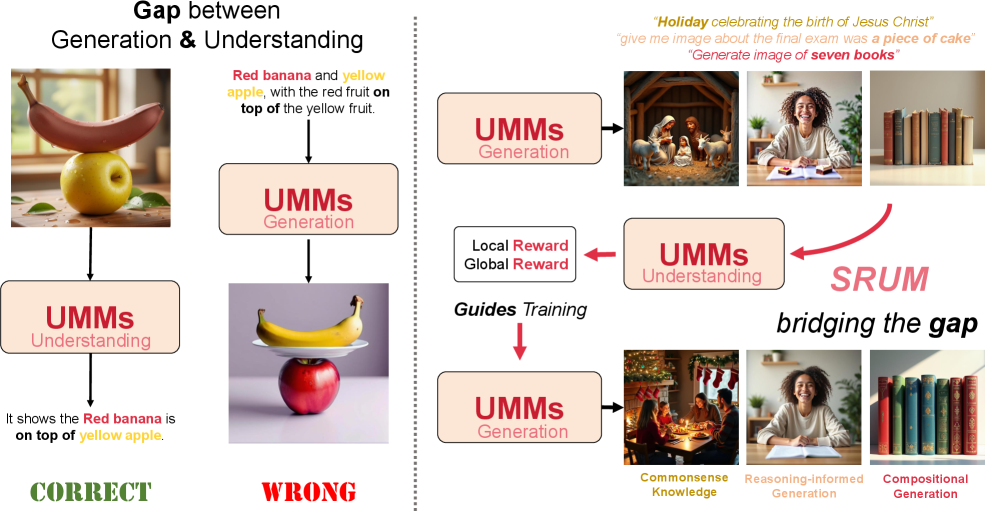
- 现有统一多模态模型在视觉理解和生成之间存在能力鸿沟,理解能力强但生成效果不佳。
- SRUM 提出利用模型自身的理解模块作为奖励信号,指导生成模块的改进,实现自我提升。
- SRUM 采用全局-局部双重奖励机制,在语义布局和对象细节层面提升生成图像的质量,实验结果显著。
📝 摘要(中文)
统一多模态模型(UMMs)在视觉-语言生成和理解方面取得了显著进展。然而,模型强大的视觉理解能力往往无法迁移到视觉生成能力上。模型可以根据用户指令正确理解图像,但无法从文本提示生成逼真的图像。为了弥合这一差距并实现自我改进,我们提出了SRUM,一种自奖励后训练框架,可直接应用于各种设计的现有UMM。SRUM创建了一个反馈循环,其中模型自身的理解模块充当内部“评估器”,提供纠正信号以改进其生成模块,而无需额外的人工标注数据。为了确保反馈的全面性,我们设计了一个全局-局部双重奖励系统,提供多尺度指导:全局奖励确保整体视觉语义和布局的正确性,而局部奖励细化细粒度的对象级保真度。SRUM 提升了 T2I-CompBench 的性能从 82.18 到 88.37,T2I-ReasonBench 的性能从 43.82 到 46.75。
🔬 方法详解
问题定义:现有统一多模态模型(UMMs)在视觉理解方面表现出色,但在文本到图像生成(T2I)任务中,模型的生成能力与其理解能力不匹配,无法生成与文本描述完全一致的图像。现有方法缺乏有效的机制来利用模型的理解能力来指导生成过程,导致生成质量受限。
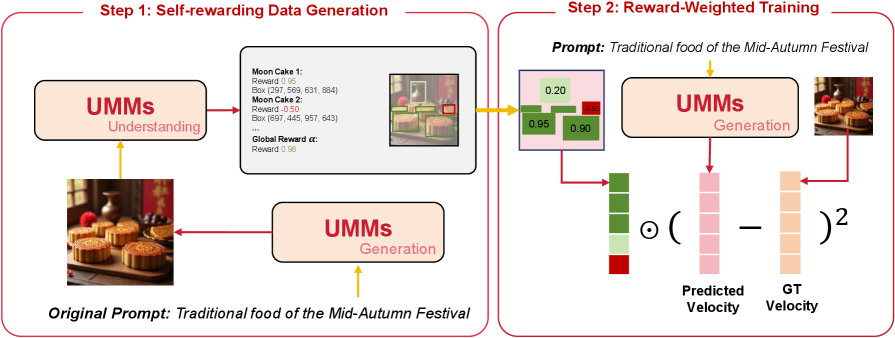
核心思路:SRUM 的核心思路是构建一个自奖励的反馈循环。模型自身的视觉理解模块被用作“评估器”,评估生成图像的质量,并提供奖励信号给生成模块。通过这种方式,生成模块可以学习生成更符合文本描述的图像,从而实现自我改进。这种方法避免了对额外人工标注数据的依赖。
技术框架:SRUM 是一个后训练框架,可以应用于现有的 UMMs。其主要流程如下:1) 使用文本提示生成图像;2) 使用模型的理解模块评估生成图像的质量,生成全局和局部奖励信号;3) 使用奖励信号优化生成模块的参数。框架包含两个关键模块:全局奖励模块和局部奖励模块。全局奖励关注整体图像的语义和布局,局部奖励关注对象级别的细节保真度。
关键创新:SRUM 的关键创新在于提出了自奖励的训练范式,利用模型自身的理解能力来指导生成能力的提升。与传统的监督学习方法不同,SRUM 不需要额外的人工标注数据,而是通过内部的反馈循环实现自我改进。全局-局部双重奖励机制是另一个创新点,它能够从多个尺度评估生成图像的质量,从而提供更全面的指导信号。
关键设计:全局奖励模块通常基于图像分类或语义分割等任务,评估生成图像的整体语义一致性。局部奖励模块则关注图像中各个对象的细节,例如使用目标检测或图像修复等技术来评估对象级别的保真度。奖励信号可以被用作生成模块的损失函数,例如使用强化学习算法来优化生成模块的参数。具体的网络结构和参数设置取决于所使用的 UMM 的具体设计。
🖼️ 关键图片
📊 实验亮点
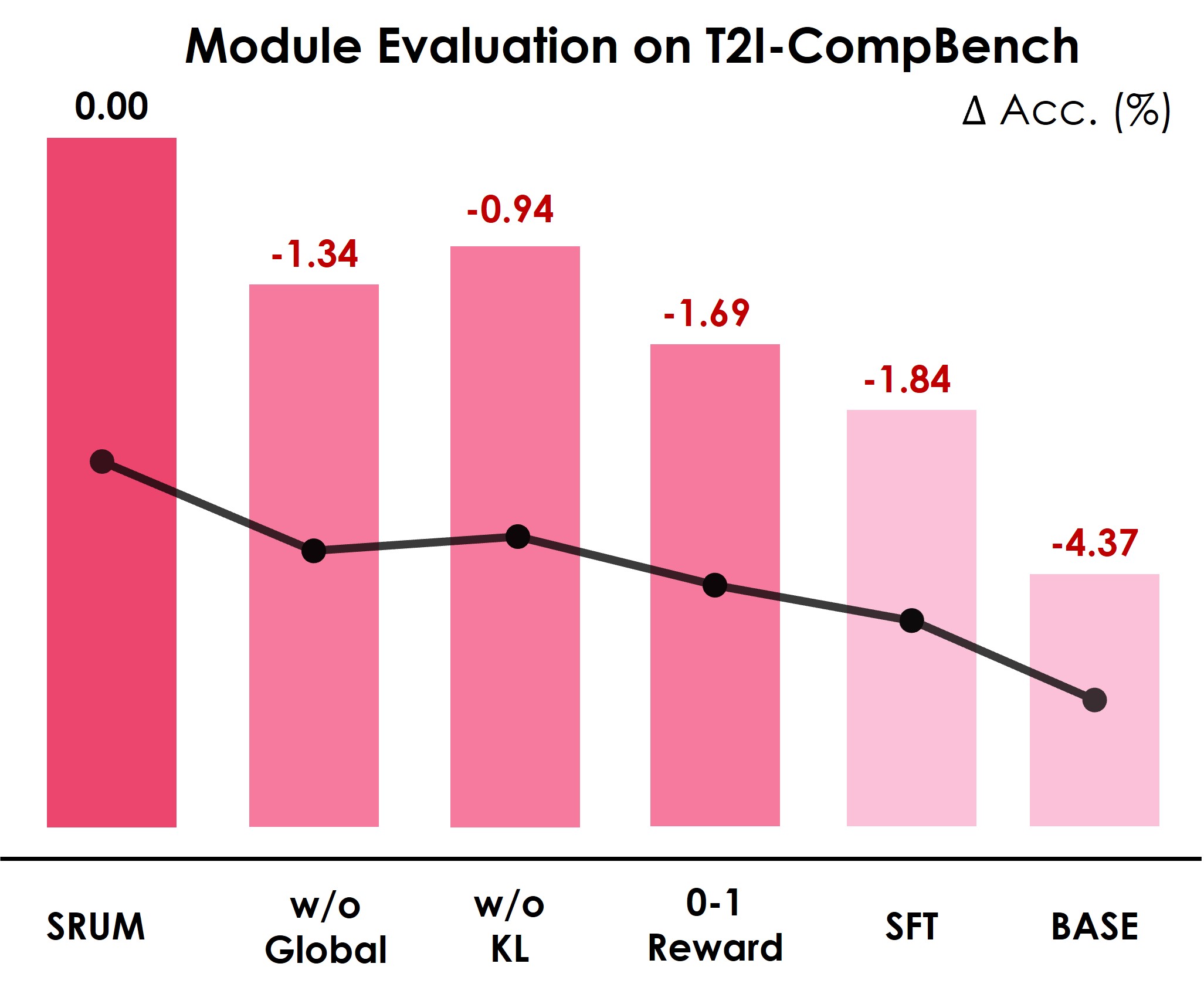
SRUM 在 T2I-CompBench 和 T2I-ReasonBench 数据集上取得了显著的性能提升。在 T2I-CompBench 上,性能从 82.18 提升到 88.37,提升了 6.19 个百分点。在 T2I-ReasonBench 上,性能从 43.82 提升到 46.75,提升了 2.93 个百分点。这些结果表明 SRUM 能够有效地提升统一多模态模型的图像生成能力。
🎯 应用场景
SRUM 具有广泛的应用前景,可用于提升各种统一多模态模型的图像生成质量,例如文本到图像生成、图像编辑和视觉故事生成等。该方法可以应用于创意设计、内容生成、虚拟现实和增强现实等领域,提高生成内容的相关性和真实感,降低对人工标注数据的依赖。
📄 摘要(原文)
Recently, remarkable progress has been made in Unified Multimodal Models (UMMs), which integrate vision-language generation and understanding capabilities within a single framework. However, a significant gap exists where a model's strong visual understanding often fails to transfer to its visual generation. A model might correctly understand an image based on user instructions, yet be unable to generate a faithful image from text prompts. This phenomenon directly raises a compelling question: Can a model achieve self-improvement by using its understanding module to reward its generation module? To bridge this gap and achieve self-improvement, we introduce SRUM, a self-rewarding post-training framework that can be directly applied to existing UMMs of various designs. SRUM creates a feedback loop where the model's own understanding module acts as an internal ``evaluator'', providing corrective signals to improve its generation module, without requiring additional human-labeled data. To ensure this feedback is comprehensive, we designed a global-local dual reward system. To tackle the inherent structural complexity of images, this system offers multi-scale guidance: a \textbf{global reward} ensures the correctness of the overall visual semantics and layout, while a \textbf{local reward} refines fine-grained, object-level fidelity. SRUM leads to powerful capabilities and shows strong generalization, boosting performance on T2I-CompBench from 82.18 to \textbf{88.37} and on T2I-ReasonBench from 43.82 to \textbf{46.75}. Overall, our work establishes a powerful new paradigm for enabling a UMMs' understanding module to guide and enhance its own generation via self-rewarding.