What If : Understanding Motion Through Sparse Interactions
作者: Stefan Andreas Baumann, Nick Stracke, Timy Phan, Björn Ommer
分类: cs.CV
发布日期: 2025-10-14
备注: Project page and code: https://compvis.github.io/flow-poke-transformer
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出Flow Poke Transformer,通过稀疏交互理解场景运动分布
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 运动预测 物理交互 Transformer 概率建模 稀疏交互
📋 核心要点
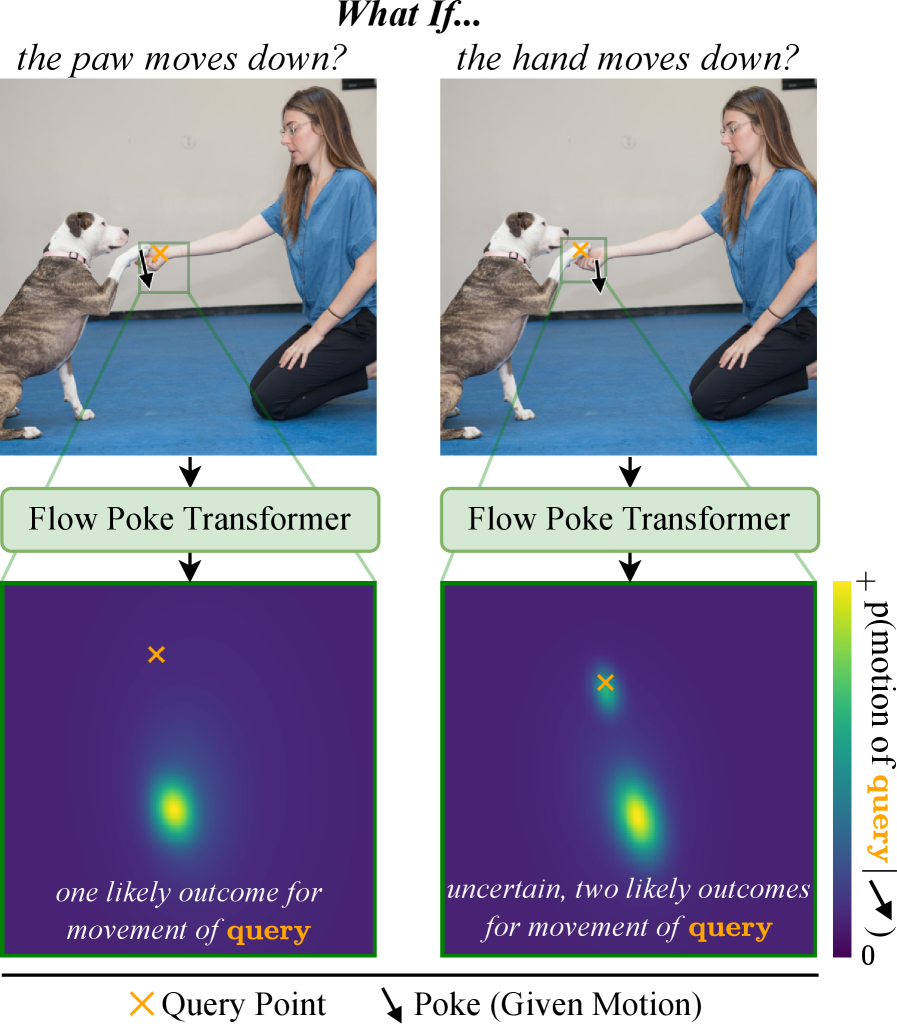
- 现有方法在理解场景动态时,通常只能生成单一的运动实现,无法捕捉运动的多样性和不确定性。
- Flow Poke Transformer (FPT) 通过预测局部运动的分布,并以稀疏交互作为条件,来理解场景动态。
- 实验表明,FPT 在人脸运动生成、铰接物体运动估计和移动部件分割等任务上表现出色,超越了现有方法。
📝 摘要(中文)
理解物理场景的动态变化需要推断其潜在的多种变化方式,特别是局部交互作用导致的变化。我们提出了Flow Poke Transformer (FPT),一种新颖的框架,用于直接预测局部运动的分布,该分布以稀疏交互(称为“pokes”)为条件。与传统方法通常只能对场景动态的单一实现进行密集采样不同,FPT提供了一种可解释的、可直接访问的多模态场景运动表示,以及它对物理交互的依赖性和场景动态的内在不确定性。我们还在几个下游任务上评估了我们的模型,以便与先前的方法进行比较,并突出我们方法的灵活性。在密集人脸运动生成方面,我们通用的预训练模型超越了专门的基线模型。FPT可以在强分布外任务(如合成数据集)中进行微调,从而在铰接对象运动估计方面显著优于领域内方法。此外,直接预测显式运动分布使我们的方法能够在诸如从pokes移动部件分割等任务上实现有竞争力的性能,这进一步证明了FPT的多功能性。
🔬 方法详解
问题定义:现有方法在理解物理场景动态时,通常只能预测单一的运动轨迹,无法捕捉到运动的多种可能性和内在的不确定性。此外,这些方法难以显式地建模物理交互(例如“戳”)对场景运动的影响,缺乏可解释性。因此,需要一种能够预测运动分布,并能有效利用稀疏交互信息的方法。
核心思路:本文的核心思路是利用Transformer架构,直接预测局部运动的概率分布,并以稀疏交互(“pokes”)作为条件。通过预测运动分布,模型可以捕捉到运动的多样性;通过以稀疏交互为条件,模型可以学习物理交互与运动之间的关系,提高可解释性。
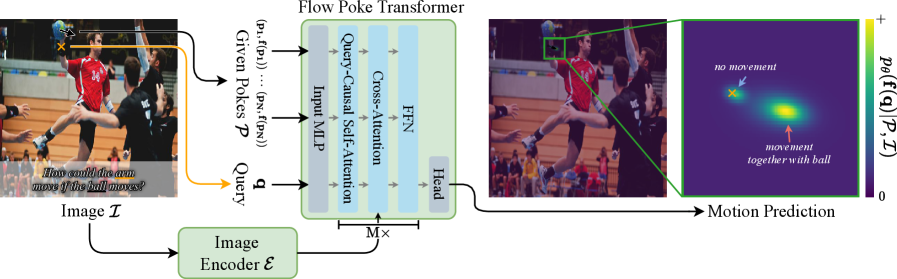
技术框架:FPT的整体框架包括以下几个主要模块:1) 输入编码器:将稀疏交互(pokes)和初始场景状态编码成特征向量。2) Transformer网络:利用Transformer的自注意力机制,学习不同位置之间的依赖关系,并预测每个位置的运动分布参数。3) 运动解码器:将运动分布参数解码成具体的运动向量。整个流程是端到端可训练的。
关键创新:FPT的关键创新在于:1) 直接预测运动分布:与传统方法预测单一运动轨迹不同,FPT直接预测运动的概率分布,能够捕捉运动的多样性和不确定性。2) 以稀疏交互为条件:FPT以稀疏交互(“pokes”)作为条件,能够学习物理交互与运动之间的关系,提高可解释性。3) 利用Transformer架构:Transformer的自注意力机制能够有效地学习不同位置之间的依赖关系,提高预测精度。
关键设计:FPT的关键设计包括:1) 运动分布的参数化:论文采用混合高斯模型来参数化运动分布,每个高斯分量对应一种可能的运动模式。2) 损失函数:论文采用负对数似然损失函数来训练模型,鼓励模型预测的运动分布与真实运动分布尽可能接近。3) Transformer网络结构:论文采用标准的Transformer编码器-解码器结构,并针对运动预测任务进行了优化。
🖼️ 关键图片

📊 实验亮点
FPT在多个下游任务上取得了显著成果。在密集人脸运动生成任务中,FPT超越了专门的基线模型。在铰接物体运动估计任务中,通过在合成数据集上进行微调,FPT显著优于领域内方法。在移动部件分割任务中,FPT也取得了有竞争力的性能。这些实验结果表明,FPT具有很强的泛化能力和多功能性。
🎯 应用场景
该研究成果可应用于机器人操作、游戏AI、虚拟现实等领域。例如,机器人可以利用该模型预测物体在受到外力作用后的运动轨迹,从而更好地完成操作任务。在游戏AI中,可以生成更逼真、更自然的物理交互效果。在虚拟现实中,可以增强用户与虚拟环境的交互体验。
📄 摘要(原文)
Understanding the dynamics of a physical scene involves reasoning about the diverse ways it can potentially change, especially as a result of local interactions. We present the Flow Poke Transformer (FPT), a novel framework for directly predicting the distribution of local motion, conditioned on sparse interactions termed "pokes". Unlike traditional methods that typically only enable dense sampling of a single realization of scene dynamics, FPT provides an interpretable directly accessible representation of multi-modal scene motion, its dependency on physical interactions and the inherent uncertainties of scene dynamics. We also evaluate our model on several downstream tasks to enable comparisons with prior methods and highlight the flexibility of our approach. On dense face motion generation, our generic pre-trained model surpasses specialized baselines. FPT can be fine-tuned in strongly out-of-distribution tasks such as synthetic datasets to enable significant improvements over in-domain methods in articulated object motion estimation. Additionally, predicting explicit motion distributions directly enables our method to achieve competitive performance on tasks like moving part segmentation from pokes which further demonstrates the versatility of our FPT. Code and models are publicly available at https://compvis.github.io/flow-poke-transformer.