E-MoFlow: Learning Egomotion and Optical Flow from Event Data via Implicit Regularization
作者: Wenpu Li, Bangyan Liao, Yi Zhou, Qi Xu, Pian Wan, Peidong Liu
分类: cs.CV
发布日期: 2025-10-14 (更新: 2025-10-24)
备注: The Thirty-Ninth Annual Conference on Neural Information Processing Systems(NeurIPS 2025)
💡 一句话要点
E-MoFlow:通过隐式正则化从事件数据中学习自运动和光流
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱七:动作重定向 (Motion Retargeting)
关键词: 事件相机 光流估计 自运动估计 隐式正则化 无监督学习 神经形态视觉 几何约束
📋 核心要点
- 传统方法独立估计光流和自运动,但在事件相机中,由于数据关联性差,且缺乏监督,问题变得不适定。
- E-MoFlow通过隐式时空和几何正则化联合优化自运动和光流,避免了显式正则化带来的偏差和计算开销。
- 实验表明,E-MoFlow在无监督方法中达到了最先进的性能,甚至可以与有监督方法竞争,验证了其有效性。
📝 摘要(中文)
光流和六自由度自运动估计是三维视觉中的两个基本任务,通常是独立解决的。然而,对于神经形态视觉(如事件相机),由于缺乏鲁棒的数据关联,单独解决这两个问题是一个不适定的挑战,尤其是在缺乏真实标签监督的情况下。现有工作通过显式的变分正则化器来强制光流场的平滑性,或者利用参数化中的显式结构和运动先验来改善事件对齐,从而缓解这种不适定性。前者会引入偏差和计算开销,而后者将光流参数化为场景深度和相机运动,通常会收敛到次优的局部最小值。为了解决这些问题,我们提出了一个无监督框架,通过隐式的时空和几何正则化来联合优化自运动和光流。首先,通过将相机的自运动建模为连续样条,并将光流建模为隐式神经表示,我们的方法通过归纳偏置固有地嵌入了时空连贯性。其次,我们通过微分几何约束来结合结构和运动先验,绕过了显式的深度估计,同时保持了严格的几何一致性。因此,我们的框架(称为E-MoFlow)在完全无监督的范式下,通过隐式正则化统一了自运动和光流估计。实验表明,它对一般的六自由度运动场景具有通用性,在无监督方法中实现了最先进的性能,甚至可以与有监督的方法相媲美。
🔬 方法详解
问题定义:论文旨在解决事件相机数据中光流和六自由度自运动的联合估计问题。现有方法要么依赖显式的变分正则化器来平滑光流场,引入偏差和计算开销;要么利用显式的结构和运动先验,容易收敛到局部最小值,无法充分利用事件数据的时空信息。
核心思路:论文的核心思路是通过隐式正则化来联合优化自运动和光流。具体来说,将自运动建模为连续样条,光流建模为隐式神经表示,从而嵌入时空连贯性。同时,利用微分几何约束来结合结构和运动先验,避免了显式深度估计,保持了几何一致性。
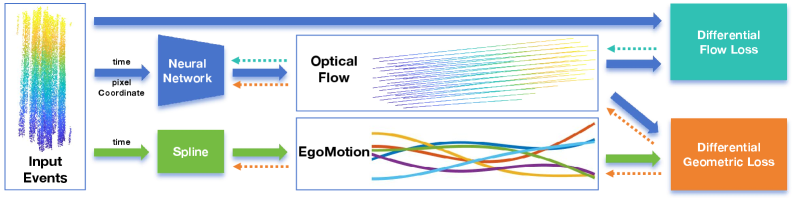
技术框架:E-MoFlow框架主要包含以下几个部分:1) 事件数据输入;2) 自运动表示模块,使用连续样条表示相机运动轨迹;3) 光流表示模块,使用隐式神经表示光流场;4) 几何约束模块,利用微分几何约束保持几何一致性;5) 损失函数,包括光度一致性损失和几何约束损失,用于无监督训练。
关键创新:E-MoFlow的关键创新在于使用隐式正则化来联合优化自运动和光流,避免了显式正则化带来的问题。此外,使用连续样条表示自运动和隐式神经表示光流,能够更好地利用事件数据的时空信息。通过微分几何约束,在没有显式深度估计的情况下,保持了几何一致性。
关键设计:自运动使用三次B样条进行参数化,控制点的位置和旋转作为可学习参数。光流使用MLP网络进行表示,输入是像素坐标,输出是光流向量。损失函数包括光度一致性损失,用于约束重构误差;以及几何约束损失,用于约束光流和自运动的几何一致性。训练过程采用Adam优化器。
🖼️ 关键图片


📊 实验亮点
E-MoFlow在公开数据集上进行了评估,实验结果表明,该方法在无监督自运动和光流估计方面取得了最先进的性能。与现有无监督方法相比,E-MoFlow显著提高了估计精度,甚至可以与一些有监督方法相媲美。这验证了隐式正则化和几何约束的有效性。
🎯 应用场景
E-MoFlow在机器人导航、自动驾驶、增强现实等领域具有广泛的应用前景。通过从事件数据中准确估计自运动和光流,可以帮助机器人更好地理解周围环境,实现自主导航和避障。此外,该方法还可以用于三维重建、视频稳定等任务,具有重要的实际价值。
📄 摘要(原文)
The estimation of optical flow and 6-DoF ego-motion, two fundamental tasks in 3D vision, has typically been addressed independently. For neuromorphic vision (e.g., event cameras), however, the lack of robust data association makes solving the two problems separately an ill-posed challenge, especially in the absence of supervision via ground truth. Existing works mitigate this ill-posedness by either enforcing the smoothness of the flow field via an explicit variational regularizer or leveraging explicit structure-and-motion priors in the parametrization to improve event alignment. The former notably introduces bias in results and computational overhead, while the latter, which parametrizes the optical flow in terms of the scene depth and the camera motion, often converges to suboptimal local minima. To address these issues, we propose an unsupervised framework that jointly optimizes egomotion and optical flow via implicit spatial-temporal and geometric regularization. First, by modeling camera's egomotion as a continuous spline and optical flow as an implicit neural representation, our method inherently embeds spatial-temporal coherence through inductive biases. Second, we incorporate structure-and-motion priors through differential geometric constraints, bypassing explicit depth estimation while maintaining rigorous geometric consistency. As a result, our framework (called E-MoFlow) unifies egomotion and optical flow estimation via implicit regularization under a fully unsupervised paradigm. Experiments demonstrate its versatility to general 6-DoF motion scenarios, achieving state-of-the-art performance among unsupervised methods and competitive even with supervised approaches.