VQArt-Bench: A semantically rich VQA Benchmark for Art and Cultural Heritage
作者: A. Alfarano, L. Venturoli, D. Negueruela del Castillo
分类: cs.CV, cs.AI, cs.LG
发布日期: 2025-10-14
💡 一句话要点
提出VQArt-Bench:一个用于艺术和文化遗产的语义丰富型VQA基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉问答 多模态学习 文化遗产 艺术分析 基准数据集
📋 核心要点
- 现有VQA基准在艺术等复杂领域缺乏深层语义理解,模型倾向于利用统计捷径而非视觉推理。
- 论文提出VQArt-Bench,一个大规模、语义丰富的文化遗产VQA基准,旨在评估模型对符号意义、叙事和复杂视觉关系的理解能力。
- 实验表明,现有MLLM在VQArt-Bench上表现出显著局限性,尤其是在计数任务和开源模型方面。
📝 摘要(中文)
多模态大型语言模型(MLLM)在联合视觉和语言任务中表现出显著的能力。然而,现有的视觉问答(VQA)基准通常无法评估深层语义理解,尤其是在视觉艺术分析等复杂领域。这些问题局限于简单的句法结构和表面层属性,无法捕捉人类视觉探究的多样性和深度。这种局限性促使模型利用统计捷径,而不是进行视觉推理。为了解决这一差距,我们引入了VQArt-Bench,这是一个新的、大规模的文化遗产领域VQA基准。该基准是使用一种新颖的多智能体管道构建的,其中专门的智能体协作生成细致的、经过验证的、语言上多样的问题。由此产生的基准沿着相关的视觉理解维度进行结构化,以探测模型解释象征意义、叙事和复杂视觉关系的能力。我们对14个最先进的MLLM在该基准上的评估揭示了当前模型的重大局限性,包括在简单计数任务中的惊人弱点,以及专有模型和开源模型之间明显的性能差距。
🔬 方法详解
问题定义:现有视觉问答(VQA)基准测试在评估模型对艺术和文化遗产等复杂领域图像的深层语义理解方面存在不足。这些基准测试中的问题往往过于简单,侧重于表面属性和句法结构,无法捕捉人类视觉探究的深度和多样性。这导致模型倾向于利用数据集中的统计偏差来回答问题,而不是真正进行视觉推理,从而限制了模型在实际应用中的泛化能力。
核心思路:论文的核心思路是构建一个更具挑战性和语义丰富性的VQA基准,即VQArt-Bench,以更全面地评估模型在理解艺术和文化遗产图像方面的能力。该基准旨在通过提出需要模型理解图像中的符号意义、叙事和复杂视觉关系的问题,来克服现有基准的局限性。
技术框架:VQArt-Bench的构建采用了一种新颖的多智能体管道。该管道包含多个专门的智能体,它们协同工作以生成细致、经过验证且语言上多样的问题。这些智能体可能包括问题生成智能体、问题验证智能体和语言多样性增强智能体。整个流程旨在确保生成的问题既具有挑战性,又与图像内容相关,并且覆盖了不同的视觉理解维度。
关键创新:VQArt-Bench的关键创新在于其问题生成方法,即使用多智能体管道来生成更复杂、更具语义挑战性的问题。与传统的手动标注或简单的规则生成方法相比,多智能体管道能够生成更自然、更贴近人类提问方式的问题,从而更好地评估模型的视觉推理能力。
关键设计:论文中没有详细说明具体的参数设置、损失函数或网络结构等技术细节。重点在于基准数据集的构建和评估,而非特定模型的训练或优化。关键设计在于多智能体协同生成问题,并对问题进行验证和多样性增强,以确保基准的质量和挑战性。
🖼️ 关键图片


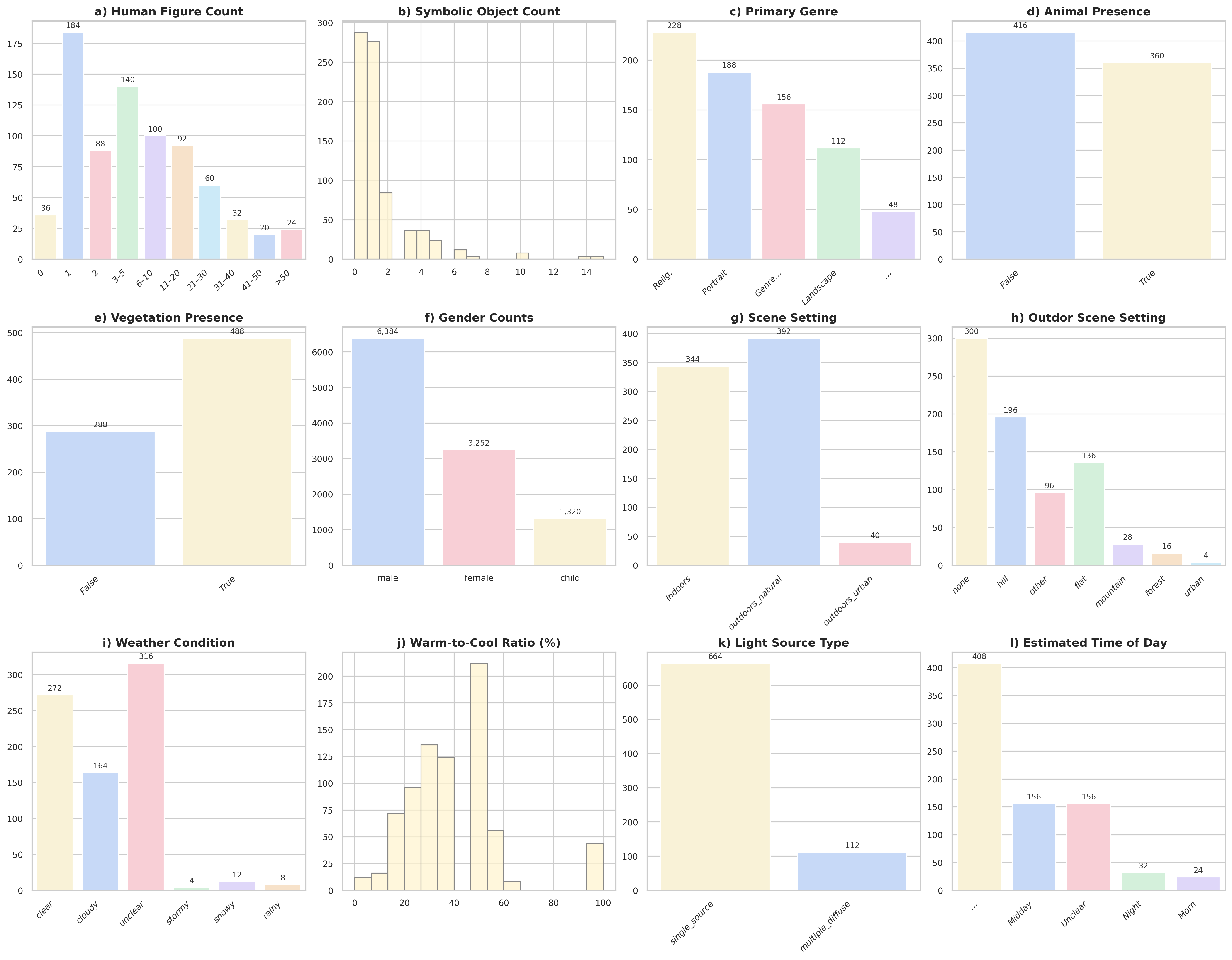
📊 实验亮点
在VQArt-Bench上对14个最先进的MLLM的评估表明,现有模型在理解复杂视觉信息方面存在显著局限性。令人惊讶的是,即使是简单的计数任务,许多模型也表现不佳。此外,专有模型通常优于开源模型,表明在模型规模和训练数据方面仍有提升空间。这些结果突显了VQArt-Bench作为评估和改进MLLM在文化遗产领域应用的重要价值。
🎯 应用场景
VQArt-Bench可用于评估和改进多模态大型语言模型在文化遗产领域的应用,例如艺术品分析、博物馆导览、历史研究等。通过提高模型对艺术作品和文化遗产的理解能力,可以为用户提供更深入、更丰富的知识和体验,促进文化传承和教育。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have demonstrated significant capabilities in joint visual and linguistic tasks. However, existing Visual Question Answering (VQA) benchmarks often fail to evaluate deep semantic understanding, particularly in complex domains like visual art analysis. Confined to simple syntactic structures and surface-level attributes, these questions fail to capture the diversity and depth of human visual inquiry. This limitation incentivizes models to exploit statistical shortcuts rather than engage in visual reasoning. To address this gap, we introduce VQArt-Bench, a new, large-scale VQA benchmark for the cultural heritage domain. This benchmark is constructed using a novel multi-agent pipeline where specialized agents collaborate to generate nuanced, validated, and linguistically diverse questions. The resulting benchmark is structured along relevant visual understanding dimensions that probe a model's ability to interpret symbolic meaning, narratives, and complex visual relationships. Our evaluation of 14 state-of-the-art MLLMs on this benchmark reveals significant limitations in current models, including a surprising weakness in simple counting tasks and a clear performance gap between proprietary and open-source models.