SPORTS: Simultaneous Panoptic Odometry, Rendering, Tracking and Segmentation for Urban Scenes Understanding
作者: Zhiliu Yang, Jinyu Dai, Jianyuan Zhang, Zhu Yang
分类: cs.CV
发布日期: 2025-10-14
备注: Accepted by IEEE Transactions on Multimedia
💡 一句话要点
SPORTS:面向城市场景理解的同步全景里程计、渲染、跟踪与分割
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 全景分割 视觉里程计 场景渲染 城市场景理解 具身智能
📋 核心要点
- 现有场景理解方案在分割、动态对象干扰、传感器数据稀疏性和视角限制等方面存在不足。
- SPORTS框架通过迭代统一的视角,紧密集成视频全景分割、视觉里程计和场景渲染任务,实现整体场景理解。
- 实验表明,该方法在里程计、跟踪、分割和新视角合成等任务上优于现有方法。
📝 摘要(中文)
本文提出了一种名为SPORTS的新框架,用于整体场景理解,它通过将视频全景分割(VPS)、视觉里程计(VO)和场景渲染(SR)任务紧密集成到一个迭代和统一的视角中。首先,VPS设计了一种基于自适应注意力的几何融合机制,通过引入姿态、深度和光流模态来对齐跨帧特征,从而自动调整不同解码阶段的特征图。并且集成了一种后匹配策略来提高身份跟踪。在VO中,来自VPS的全景分割结果与光流图相结合,以提高动态对象的置信度估计,从而通过基于学习的范例提高相机姿态估计的准确性和深度图生成的完整性。此外,SR的基于点的渲染受益于VO,将稀疏点云转换为神经场,以合成高保真RGB视图和孪生全景视图。在三个公共数据集上的大量实验表明,我们的基于注意力的特征融合在里程计、跟踪、分割和新视角合成任务上优于大多数现有的最先进方法。
🔬 方法详解
问题定义:现有场景理解方法在城市环境中面临诸多挑战,包括分割精度不足、动态物体造成的干扰、传感器数据稀疏以及视角受限等问题。这些问题限制了具身智能体(Embodied-AI agents)对环境的全面感知和理解,进而影响其决策和行动。
核心思路:SPORTS的核心思想是将视频全景分割(VPS)、视觉里程计(VO)和场景渲染(SR)三个任务紧密结合,形成一个迭代优化的闭环。通过互相提供信息,解决各自任务中的固有难题,从而实现更鲁棒和准确的场景理解。
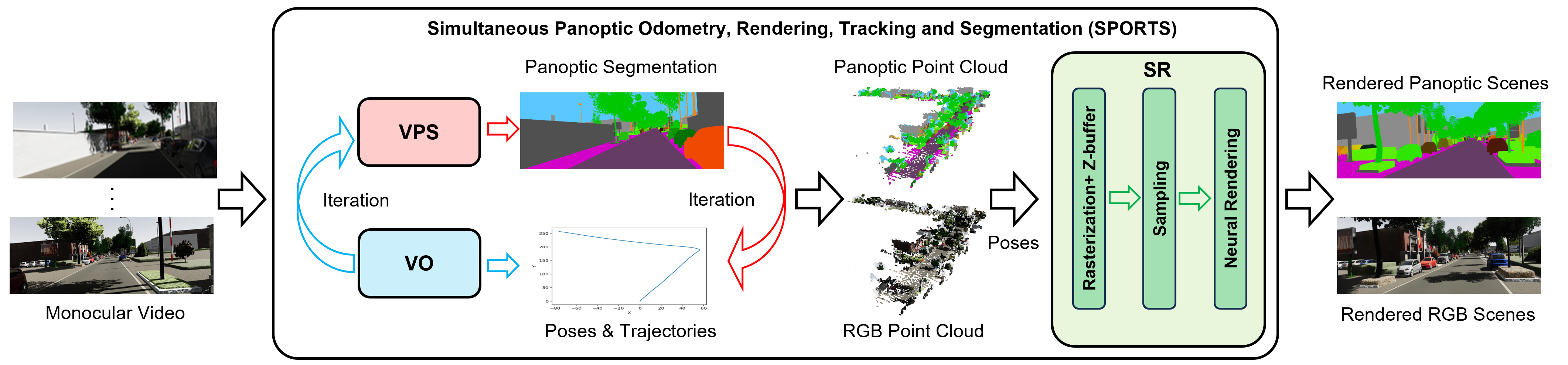
技术框架:SPORTS框架包含三个主要模块:视频全景分割(VPS)、视觉里程计(VO)和场景渲染(SR)。VPS模块负责对视频帧进行全景分割,区分静态背景和动态物体,并进行实例级别的分割和跟踪。VO模块利用VPS的结果和光流信息,估计相机的运动轨迹和场景深度。SR模块则利用VO的结果,将稀疏点云转换为神经场,从而合成高质量的RGB图像和全景分割图像。这三个模块相互依赖,迭代优化。
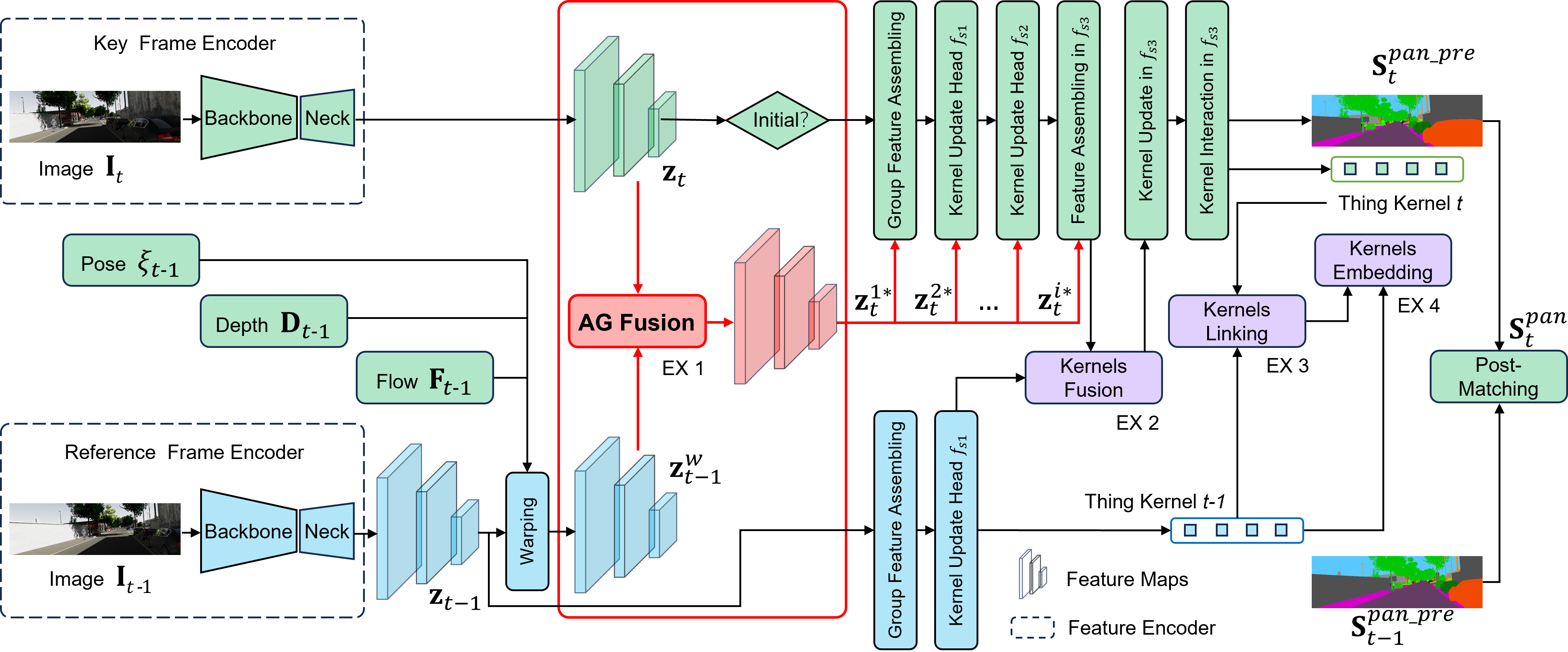
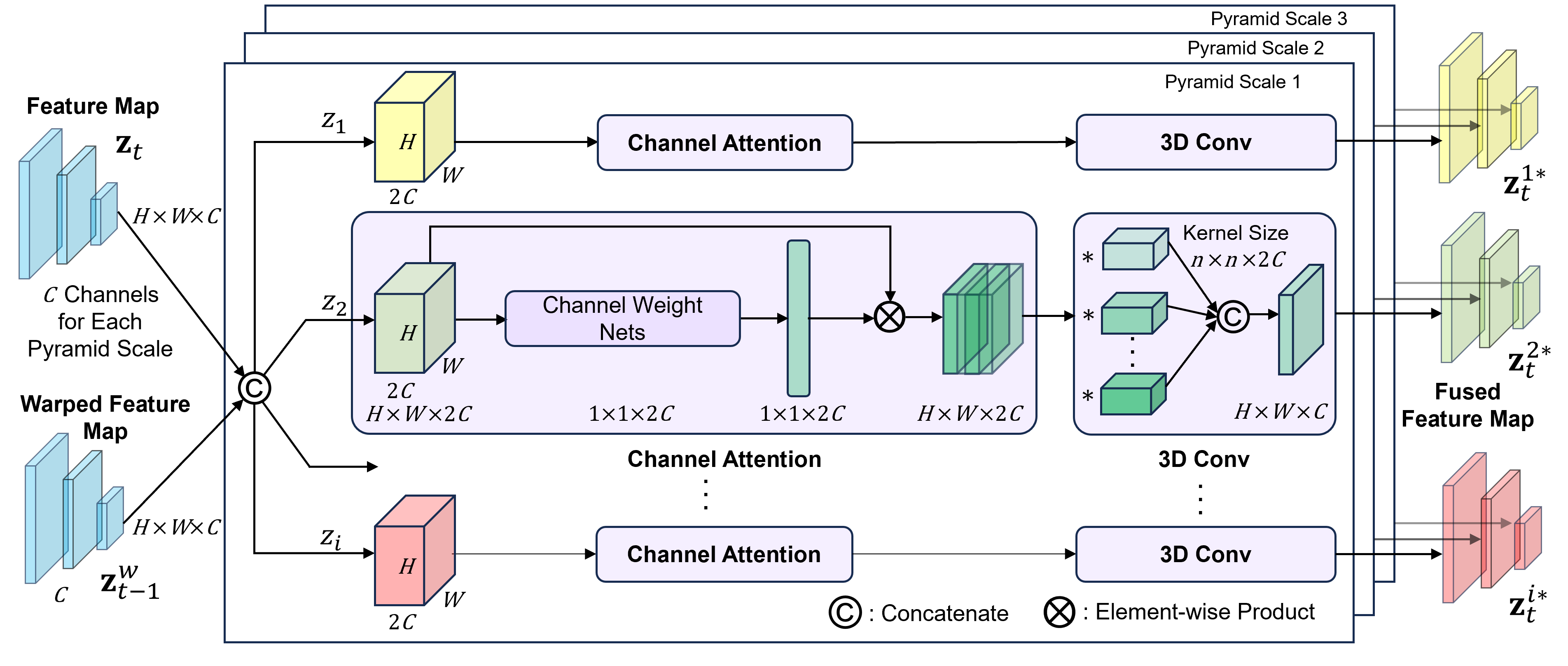
关键创新:该论文的关键创新在于将VPS、VO和SR三个任务集成到一个统一的框架中,并设计了一种基于自适应注意力的几何融合机制,用于对齐跨帧特征。这种融合机制能够根据不同解码阶段的需求,自动调整特征图,从而提高分割和跟踪的精度。此外,该框架还利用VPS的结果来提高VO中动态物体置信度估计的准确性。
关键设计:VPS模块中,自适应注意力机制根据姿态、深度和光流信息动态调整特征权重,实现跨帧特征的有效融合。VO模块中,利用VPS提供的动态物体分割结果,降低动态物体对相机姿态估计的影响。SR模块采用基于点的渲染方法,将稀疏点云转换为神经场,实现高质量的图像合成。损失函数的设计也考虑了三个任务之间的相互依赖关系,例如,VO的损失函数中包含了VPS的分割结果。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SPORTS框架在三个公共数据集上取得了显著的性能提升。在里程计任务上,该方法优于现有的最先进方法。在跟踪任务上,该方法通过集成后匹配策略,提高了身份跟踪的准确性。在分割任务上,基于注意力的特征融合机制显著提高了分割精度。在新视角合成任务上,该方法能够生成高质量的RGB图像和全景分割图像。
🎯 应用场景
SPORTS框架在自动驾驶、机器人导航、增强现实等领域具有广泛的应用前景。它可以帮助自动驾驶系统更准确地感知周围环境,提高导航的安全性。在机器人导航中,该框架可以帮助机器人更好地理解场景,从而实现更智能的路径规划和避障。在增强现实中,该框架可以用于构建更逼真的虚拟场景,提高用户体验。
📄 摘要(原文)
The scene perception, understanding, and simulation are fundamental techniques for embodied-AI agents, while existing solutions are still prone to segmentation deficiency, dynamic objects' interference, sensor data sparsity, and view-limitation problems. This paper proposes a novel framework, named SPORTS, for holistic scene understanding via tightly integrating Video Panoptic Segmentation (VPS), Visual Odometry (VO), and Scene Rendering (SR) tasks into an iterative and unified perspective. Firstly, VPS designs an adaptive attention-based geometric fusion mechanism to align cross-frame features via enrolling the pose, depth, and optical flow modality, which automatically adjust feature maps for different decoding stages. And a post-matching strategy is integrated to improve identities tracking. In VO, panoptic segmentation results from VPS are combined with the optical flow map to improve the confidence estimation of dynamic objects, which enhances the accuracy of the camera pose estimation and completeness of the depth map generation via the learning-based paradigm. Furthermore, the point-based rendering of SR is beneficial from VO, transforming sparse point clouds into neural fields to synthesize high-fidelity RGB views and twin panoptic views. Extensive experiments on three public datasets demonstrate that our attention-based feature fusion outperforms most existing state-of-the-art methods on the odometry, tracking, segmentation, and novel view synthesis tasks.