On the Use of Hierarchical Vision Foundation Models for Low-Cost Human Mesh Recovery and Pose Estimation
作者: Shuhei Tarashima, Yushan Wang, Norio Tagawa
分类: cs.CV
发布日期: 2025-10-14 (更新: 2025-11-15)
备注: Accepted at ICCVW 2025. Code: https://github.com/nttcom/TruncHierVFM
🔗 代码/项目: GITHUB
💡 一句话要点
利用分层视觉基础模型,实现低成本人体网格重建与姿态估计
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人体网格重建 人体姿态估计 分层视觉模型 Transformer 模型压缩 计算效率 轻量级模型
📋 核心要点
- 现有HMR方法依赖大型非分层Transformer,计算成本高昂,难以在资源受限场景应用。
- 利用分层VFM的早期阶段作为编码器,在保证性能的同时显著降低计算复杂度。
- 实验表明,截断模型在精度和效率之间取得了更好的平衡,优于现有轻量级方案。
📝 摘要(中文)
本文旨在开发简单高效的人体网格重建(HMR)及其前置任务人体姿态估计(HPE)模型。目前最先进的HMR方法,如HMR2.0及其后续模型,依赖于大型非分层视觉Transformer作为编码器,这些编码器继承自相应的HPE模型,如ViTPose。为了建立不同计算预算下的基线,我们首先通过调整相应的ViTPose模型构建了三个轻量级HMR2.0变体。此外,我们提出利用分层视觉基础模型(VFM)的早期阶段作为编码器,包括Swin Transformer、GroupMixFormer和VMamba。这一设计的动机是观察到分层VFM的中间阶段产生的分辨率与非分层模型相当或更高的特征图。我们对27个基于分层VFM的HMR和HPE模型进行了全面评估,表明仅使用前两个或三个阶段即可达到与完整阶段模型相当的性能。此外,我们表明,与现有的轻量级替代方案相比,由此产生的截断模型在准确性和计算效率之间表现出更好的权衡。
🔬 方法详解
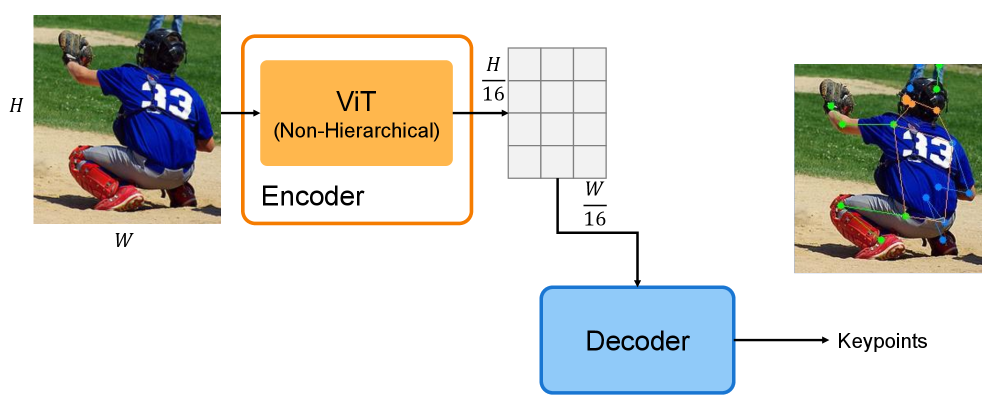
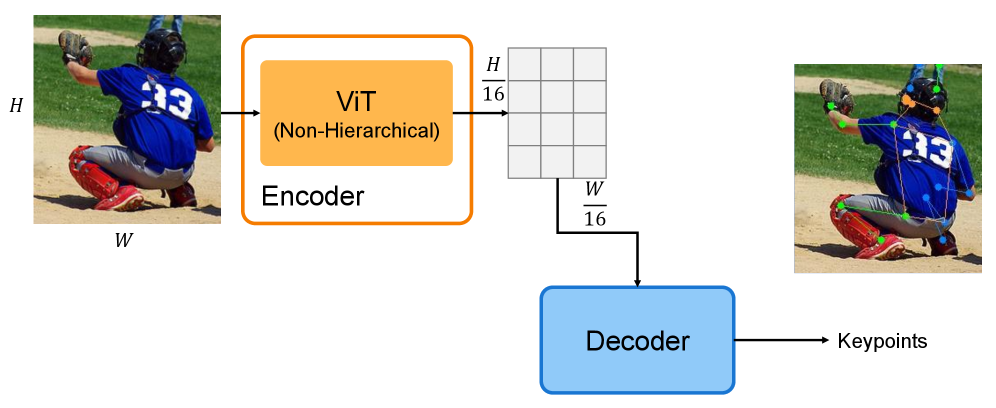
问题定义:现有的人体网格重建(HMR)和人体姿态估计(HPE)方法,特别是基于Transformer的模型,计算量大,难以在低成本或资源受限的环境中部署。HMR2.0等先进方法依赖于大型非分层视觉Transformer,这限制了其在边缘设备上的应用。因此,需要开发一种计算效率更高,但性能不显著下降的HMR和HPE模型。
核心思路:论文的核心思路是利用分层视觉基础模型(VFM)的早期阶段作为编码器。分层VFM,如Swin Transformer、GroupMixFormer和VMamba,在网络的早期阶段产生高分辨率的特征图,这些特征图包含足够的信息用于HMR和HPE任务。通过截断VFM,只使用其前几个阶段,可以显著减少计算量,同时保持甚至提高性能。
技术框架:整体框架包括以下步骤:1) 选择一个分层VFM(如Swin Transformer);2) 截断该VFM,只保留前N个stage(N=2或3);3) 将截断的VFM作为HMR或HPE模型的编码器;4) 使用标准的人体网格重建或姿态估计损失函数进行训练。该框架可以灵活地与不同的分层VFM和HMR/HPE解码器结合使用。
关键创新:关键创新在于发现并利用了分层VFM的早期阶段所包含的丰富信息。与直接使用完整的VFM或非分层Transformer相比,截断的VFM在计算效率和性能之间取得了更好的平衡。这种方法避免了对整个图像进行全局注意力计算,从而降低了计算复杂度。
关键设计:论文的关键设计包括:1) 选择合适的分层VFM,如Swin Transformer、GroupMixFormer和VMamba;2) 确定最佳的截断阶段数N,实验表明N=2或3通常可以获得最佳性能;3) 使用标准的HMR和HPE损失函数,如MPJPE(Mean Per Joint Position Error)和PA-MPJPE(Pose Aligned MPJPE)进行评估。没有特别提及特殊的参数设置或网络结构,而是强调了利用现有VFM的早期阶段。
🖼️ 关键图片

📊 实验亮点
实验结果表明,基于截断分层VFM的HMR和HPE模型在性能上与完整模型相当,甚至在某些情况下有所提升。例如,使用Swin Transformer的前两个阶段作为编码器,可以在保持精度的同时,显著降低计算量。与现有的轻量级HMR模型相比,该方法在精度和效率之间取得了更好的权衡。
🎯 应用场景
该研究成果可应用于低功耗设备上的人体姿态识别、动作捕捉、虚拟现实/增强现实、智能监控等领域。通过降低计算成本,使得HMR和HPE技术能够更广泛地应用于移动设备和嵌入式系统,为用户提供更便捷、实时的交互体验。
📄 摘要(原文)
In this work, we aim to develop simple and efficient models for human mesh recovery (HMR) and its predecessor task, human pose estimation (HPE). State-of-the-art HMR methods, such as HMR2.0 and its successors, rely on large, non-hierarchical vision transformers as encoders, which are inherited from the corresponding HPE models like ViTPose. To establish baselines across varying computational budgets, we first construct three lightweight HMR2.0 variants by adapting the corresponding ViTPose models. In addition, we propose leveraging the early stages of hierarchical vision foundation models (VFMs), including Swin Transformer, GroupMixFormer, and VMamba, as encoders. This design is motivated by the observation that intermediate stages of hierarchical VFMs produce feature maps with resolutions comparable to or higher than those of non-hierarchical counterparts. We conduct a comprehensive evaluation of 27 hierarchical-VFM-based HMR and HPE models, demonstrating that using only the first two or three stages achieves performance on par with full-stage models. Moreover, we show that the resulting truncated models exhibit better trade-offs between accuracy and computational efficiency compared to existing lightweight alternatives. The source code is available at https://github.com/nttcom/TruncHierVFM.