LayerSync: Self-aligning Intermediate Layers
作者: Yasaman Haghighi, Bastien van Delft, Mariam Hassan, Alexandre Alahi
分类: cs.CV, cs.LG
发布日期: 2025-10-14
🔗 代码/项目: GITHUB
💡 一句话要点
LayerSync:提出一种自对齐中间层的扩散模型训练方法,提升生成质量和训练效率。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 扩散模型 自监督学习 表征学习 生成模型 正则化 图像生成 音频合成
📋 核心要点
- 现有扩散模型训练依赖外部指导或额外数据,成本较高且泛化性受限。
- LayerSync利用扩散模型自身不同层的表征差异,用高质量层指导低质量层,实现自监督正则化。
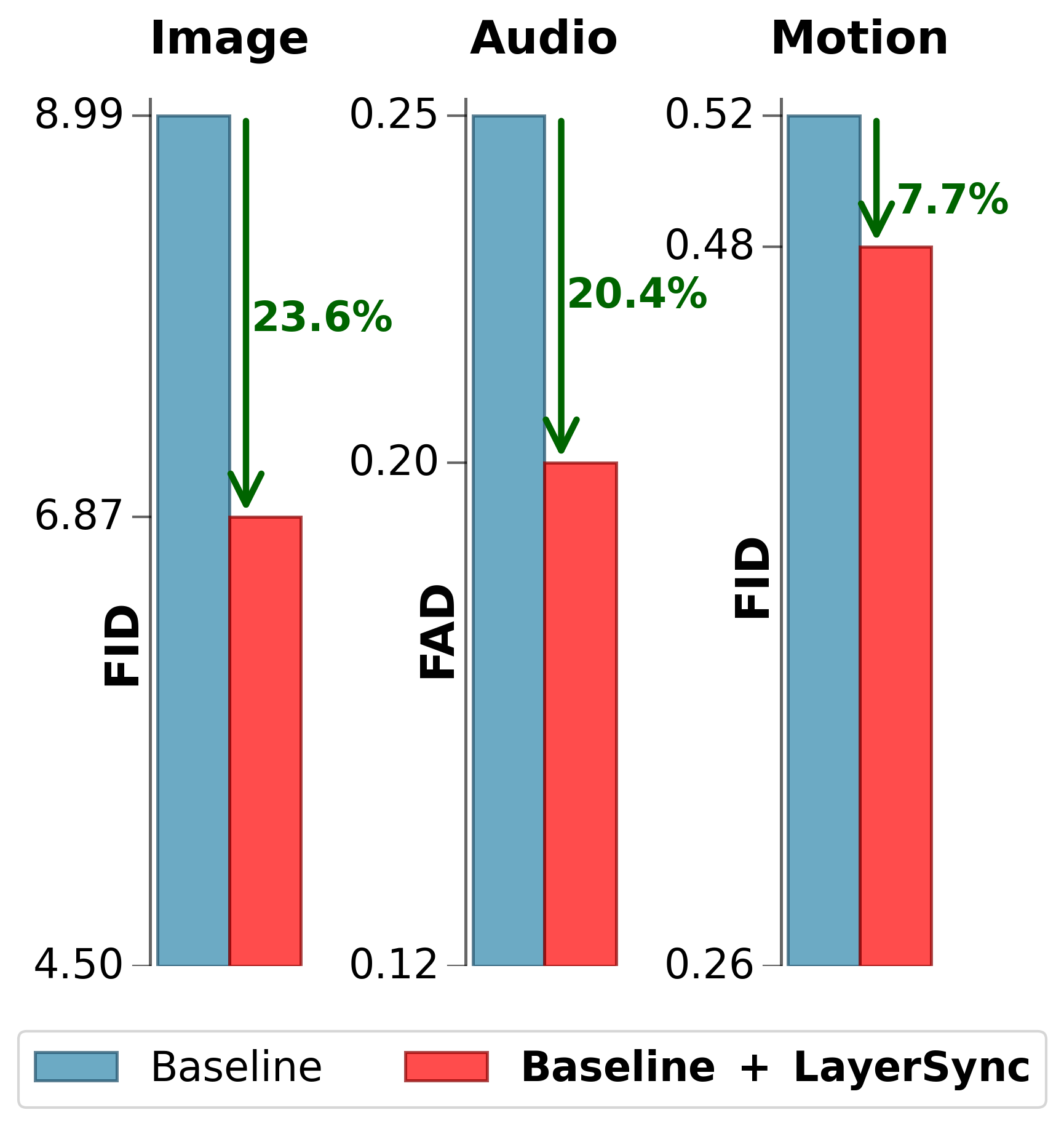
- 实验表明,LayerSync在图像、音频、视频和运动生成等多个领域均能显著提升生成质量和训练效率。
📝 摘要(中文)
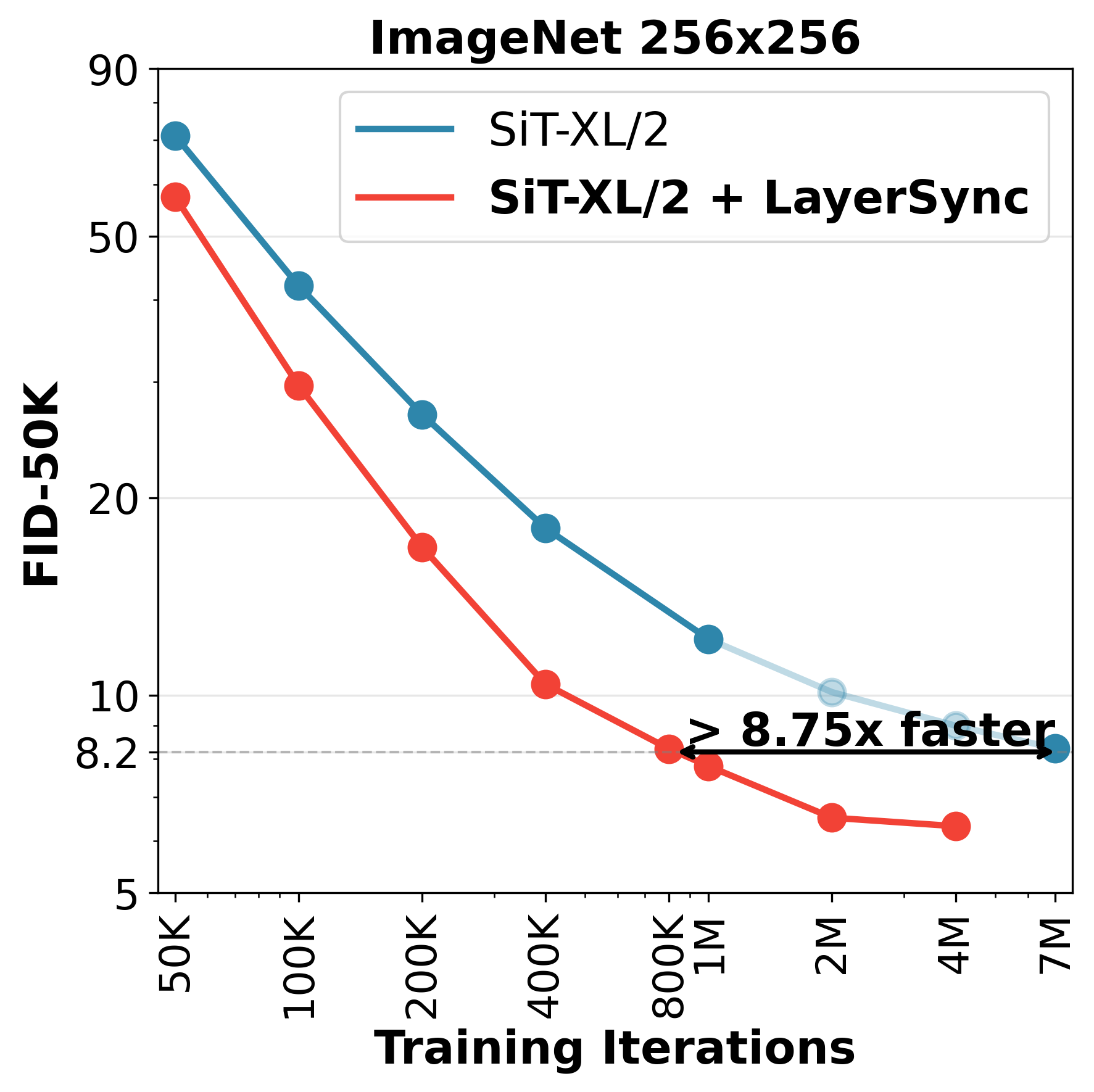
本文提出LayerSync,一种与领域无关的方法,用于提高扩散模型的生成质量和训练效率。先前的研究强调了生成质量与扩散模型学习到的表征之间的联系,表明对模型中间表征的外部指导可以加速训练。我们通过使用扩散模型自身的中间表征来正则化扩散模型,从而重新概念化了这种范式。基于扩散模型层之间的表征质量存在差异的观察,我们表明语义最丰富的表征可以作为较弱表征的内在指导,从而减少对外部监督的需求。我们的方法LayerSync是一种自给自足的即插即用正则化项,不会增加扩散模型训练的开销,并且可以推广到视觉领域之外的其他模态。LayerSync不需要预训练模型或额外数据。我们在图像生成方面广泛评估了该方法,并证明了其在音频、视频和运动生成等其他领域的适用性。我们表明它可以持续提高生成质量和训练效率。例如,我们在ImageNet数据集上将基于流的Transformer的训练速度提高了8.75倍以上,并将生成质量提高了23.6%。
🔬 方法详解
问题定义:现有扩散模型训练方法通常依赖于外部的指导信号或者额外的训练数据来提升生成质量和训练效率。这些方法增加了训练的复杂度和成本,并且可能限制了模型的泛化能力,尤其是在数据稀缺或者标注困难的场景下。因此,如何高效且自监督地提升扩散模型的性能是一个重要的研究问题。
核心思路:LayerSync的核心思路是利用扩散模型自身不同层之间的表征差异,实现自监督的正则化。具体来说,该方法观察到扩散模型的不同层学习到的表征质量存在差异,某些层可能学习到更丰富、更具语义信息的表征。LayerSync利用这些高质量的表征作为“教师”,来指导其他相对较弱的层,从而提升整体的表征质量和生成性能。
技术框架:LayerSync作为一个即插即用的正则化项,可以方便地集成到现有的扩散模型训练流程中。其主要步骤包括:1) 提取扩散模型不同层的中间表征;2) 评估各层表征的质量(例如,通过某种度量指标);3) 选择高质量的层作为“教师”层,低质量的层作为“学生”层;4) 使用某种损失函数(例如,KL散度或MSE)来约束“学生”层的表征,使其尽可能接近“教师”层的表征。整个过程无需额外的预训练模型或数据集。
关键创新:LayerSync的关键创新在于其自监督的正则化方式。与传统的依赖外部指导信号的方法不同,LayerSync完全依赖于模型自身的中间表征,实现了真正的“自给自足”。这种方法不仅降低了训练成本,还提高了模型的泛化能力。此外,LayerSync的即插即用特性使其可以方便地应用于各种不同的扩散模型和任务。
关键设计:LayerSync的关键设计包括:1) 如何选择合适的“教师”层和“学生”层。一种简单的方法是根据层索引来选择,例如选择中间层作为“教师”层,而选择靠近输入和输出的层作为“学生”层。更复杂的方法是使用某种度量指标来评估各层表征的质量,例如使用互信息或线性可分性等指标。2) 如何设计合适的损失函数来约束“学生”层的表征。常用的损失函数包括KL散度、MSE和余弦相似度等。3) 如何平衡正则化项的权重。正则化项的权重需要根据具体的任务和数据集进行调整,以达到最佳的性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LayerSync在多个数据集和任务上均取得了显著的性能提升。例如,在ImageNet数据集上,LayerSync将基于流的Transformer的训练速度提高了8.75倍以上,并将生成质量提高了23.6%。此外,LayerSync还在音频、视频和运动生成等领域展现了良好的泛化能力,证明了其有效性和通用性。
🎯 应用场景
LayerSync具有广泛的应用前景,可应用于图像生成、音频合成、视频生成、动作生成等多个领域。该方法能够提升生成质量和训练效率,降低对外部数据和监督信号的依赖,有望推动扩散模型在资源受限场景下的应用,并促进更具创造性和泛化能力的生成模型的发展。
📄 摘要(原文)
We propose LayerSync, a domain-agnostic approach for improving the generation quality and the training efficiency of diffusion models. Prior studies have highlighted the connection between the quality of generation and the representations learned by diffusion models, showing that external guidance on model intermediate representations accelerates training. We reconceptualize this paradigm by regularizing diffusion models with their own intermediate representations. Building on the observation that representation quality varies across diffusion model layers, we show that the most semantically rich representations can act as an intrinsic guidance for weaker ones, reducing the need for external supervision. Our approach, LayerSync, is a self-sufficient, plug-and-play regularizer term with no overhead on diffusion model training and generalizes beyond the visual domain to other modalities. LayerSync requires no pretrained models nor additional data. We extensively evaluate the method on image generation and demonstrate its applicability to other domains such as audio, video, and motion generation. We show that it consistently improves the generation quality and the training efficiency. For example, we speed up the training of flow-based transformer by over 8.75x on ImageNet dataset and improved the generation quality by 23.6%. The code is available at https://github.com/vita-epfl/LayerSync.