CoIRL-AD: Collaborative-Competitive Imitation-Reinforcement Learning in Latent World Models for Autonomous Driving
作者: Xiaoji Zheng, Ziyuan Yang, Yanhao Chen, Yuhang Peng, Yuanrong Tang, Gengyuan Liu, Bokui Chen, Jiangtao Gong
分类: cs.CV, cs.LG, cs.RO
发布日期: 2025-10-14
备注: 18 pages, 17 figures
🔗 代码/项目: GITHUB
💡 一句话要点
提出CoIRL-AD,一种用于自动驾驶的竞争式模仿-强化学习框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 自动驾驶 模仿学习 强化学习 竞争学习 世界模型
📋 核心要点
- 端到端自动驾驶模型仅依赖模仿学习泛化性差,强化学习则面临样本效率和收敛问题。
- CoIRL-AD构建竞争式双策略框架,让模仿学习和强化学习智能体在训练中交互。
- 实验表明,CoIRL-AD在nuScenes数据集上碰撞率降低18%,泛化能力和长尾场景性能提升。
📝 摘要(中文)
本文提出了一种名为CoIRL-AD的竞争式双策略框架,用于解决端到端自动驾驶模型仅通过模仿学习(IL)训练时泛化能力差的问题,以及强化学习(RL)样本效率低和收敛不稳定等挑战。CoIRL-AD超越了传统的两阶段范式(IL预训练后进行RL微调),使IL和RL智能体在训练期间能够相互交互。CoIRL-AD引入了一种基于竞争的机制,促进知识交流,同时防止梯度冲突。在nuScenes数据集上的实验表明,与基线方法相比,碰撞率降低了18%,同时具有更强的泛化能力和在长尾场景中改进的性能。
🔬 方法详解
问题定义:现有的端到端自动驾驶模型主要依赖模仿学习或强化学习。模仿学习虽然简单,但容易过拟合专家数据,泛化能力差,难以应对复杂和未知的场景。强化学习虽然可以通过奖励最大化进行探索,但样本效率低,训练不稳定,需要大量的试错才能学习到有效的策略。因此,如何结合模仿学习和强化学习的优点,克服各自的缺点,是自动驾驶领域的一个重要挑战。
核心思路:CoIRL-AD的核心思路是构建一个竞争式的双策略框架,让模仿学习(IL)和强化学习(RL)智能体在训练过程中相互竞争和协作。通过竞争,可以促进智能体之间的知识交流,提高策略的多样性,从而增强模型的泛化能力。同时,通过协作,可以避免梯度冲突,保证训练的稳定性。
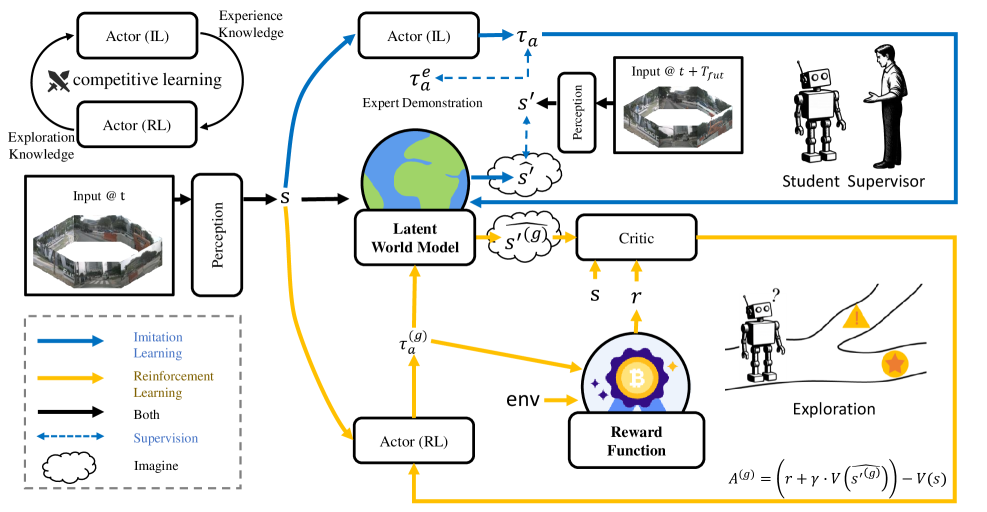
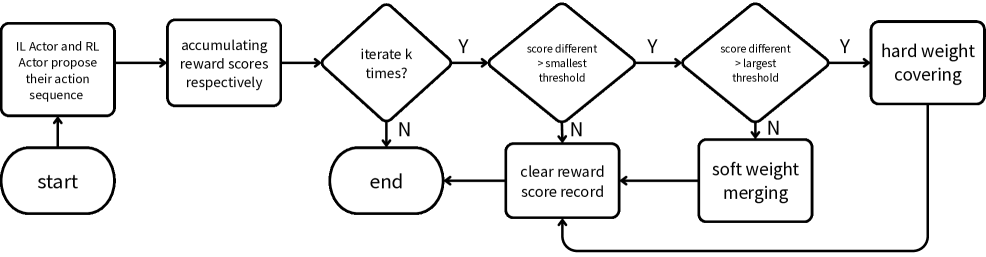
技术框架:CoIRL-AD的整体框架包含两个主要的智能体:模仿学习智能体和强化学习智能体。这两个智能体共享一个潜在世界模型,该模型用于学习环境的抽象表示。在每个训练迭代中,两个智能体根据各自的策略生成动作,并与环境交互。环境返回奖励和下一个状态。模仿学习智能体通过模仿专家数据来学习策略,而强化学习智能体通过最大化累积奖励来学习策略。为了促进知识交流,CoIRL-AD引入了一个竞争机制,该机制根据两个智能体的表现来调整它们的权重。
关键创新:CoIRL-AD的关键创新在于其竞争式的双策略框架。与传统的两阶段方法(先用模仿学习预训练,再用强化学习微调)不同,CoIRL-AD允许模仿学习和强化学习智能体在训练过程中同时学习和交互。这种竞争式的学习方式可以促进知识交流,提高策略的多样性,从而增强模型的泛化能力。此外,CoIRL-AD的竞争机制可以有效地防止梯度冲突,保证训练的稳定性。
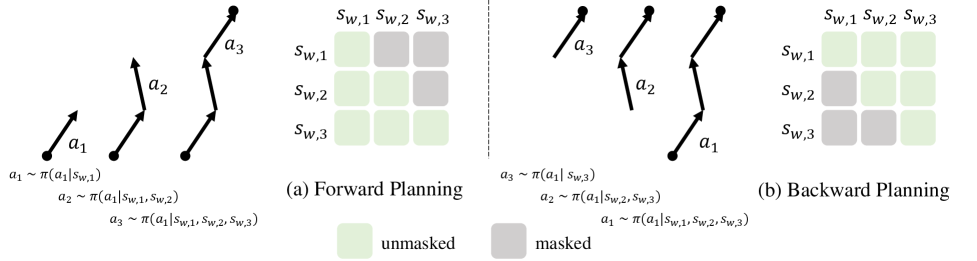
关键设计:CoIRL-AD的关键设计包括:1) 共享的潜在世界模型,用于学习环境的抽象表示;2) 竞争机制,根据两个智能体的表现来调整它们的权重;3) 模仿学习损失函数,用于指导模仿学习智能体学习专家策略;4) 强化学习奖励函数,用于指导强化学习智能体探索环境并学习最优策略。具体的网络结构和参数设置在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
CoIRL-AD在nuScenes数据集上进行了评估,实验结果表明,与基线方法相比,CoIRL-AD的碰撞率降低了18%,表明其具有更强的安全性和可靠性。此外,CoIRL-AD在长尾场景中也表现出更好的性能,表明其具有更强的泛化能力。这些结果验证了CoIRL-AD的有效性和优越性。
🎯 应用场景
CoIRL-AD具有广泛的应用前景,可用于提升自动驾驶系统在复杂和未知环境中的安全性和可靠性。该方法不仅可以应用于车辆的运动规划和控制,还可以扩展到其他机器人领域,例如无人机导航、机器人操作等。通过结合模仿学习和强化学习的优势,CoIRL-AD有望推动自动驾驶技术的发展,实现更安全、更智能的出行。
📄 摘要(原文)
End-to-end autonomous driving models trained solely with imitation learning (IL) often suffer from poor generalization. In contrast, reinforcement learning (RL) promotes exploration through reward maximization but faces challenges such as sample inefficiency and unstable convergence. A natural solution is to combine IL and RL. Moving beyond the conventional two-stage paradigm (IL pretraining followed by RL fine-tuning), we propose CoIRL-AD, a competitive dual-policy framework that enables IL and RL agents to interact during training. CoIRL-AD introduces a competition-based mechanism that facilitates knowledge exchange while preventing gradient conflicts. Experiments on the nuScenes dataset show an 18% reduction in collision rate compared to baselines, along with stronger generalization and improved performance on long-tail scenarios. Code is available at: https://github.com/SEU-zxj/CoIRL-AD.