CurriFlow: Curriculum-Guided Depth Fusion with Optical Flow-Based Temporal Alignment for 3D Semantic Scene Completion
作者: Jinzhou Lin, Jie Zhou, Wenhao Xu, Rongtao Xu, Changwei Wang, Shunpeng Chen, Kexue Fu, Yihua Shao, Li Guo, Shibiao Xu
分类: cs.CV
发布日期: 2025-10-14
💡 一句话要点
CurriFlow:基于光流时间对齐与课程学习的深度融合,用于3D语义场景补全
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 语义场景补全 光流对齐 课程学习 深度融合 三维重建
📋 核心要点
- 现有语义场景补全方法在处理遮挡、噪声深度以及缺乏显式运动推理方面存在不足,限制了其在复杂环境下的性能。
- CurriFlow通过光流对齐跨帧特征,并结合课程学习策略,从稀疏到密集地利用深度信息,提升了时间和空间一致性。
- CurriFlow在SemanticKITTI数据集上取得了state-of-the-art的结果,平均IoU达到16.9,验证了其有效性。
📝 摘要(中文)
语义场景补全(SSC)旨在从单目图像推断完整的3D几何和语义信息,是基于相机的自动驾驶感知中的关键能力。然而,现有的依赖于时间堆叠或深度投影的SSC方法通常缺乏显式的运动推理,并且难以处理遮挡和噪声深度监督。我们提出了CurriFlow,一种新颖的语义占据预测框架,它集成了基于光流的时间对齐和课程引导的深度融合。CurriFlow采用多层次融合策略,利用预训练的光流来对齐跨帧的分割、视觉和深度特征,从而提高时间一致性和动态对象理解。为了增强几何鲁棒性,课程学习机制在训练期间逐步从稀疏但精确的LiDAR深度过渡到密集但有噪声的立体深度,确保稳定的优化和无缝适应真实世界的部署。此外,来自Segment Anything Model(SAM)的语义先验提供了类别无关的监督,加强了体素级别的语义学习和空间一致性。在SemanticKITTI基准上的实验表明,CurriFlow实现了最先进的性能,平均IoU为16.9,验证了我们的运动引导和课程感知设计对于基于相机的3D语义场景补全的有效性。
🔬 方法详解
问题定义:语义场景补全(SSC)旨在从不完整的单目图像中恢复场景的完整3D几何和语义信息。现有方法主要依赖于时间堆叠或深度投影,但这些方法缺乏对场景中物体运动的显式建模,容易受到遮挡和噪声深度的影响,导致补全结果不准确。
核心思路:CurriFlow的核心思路是利用光流来对齐不同帧之间的特征,从而实现更准确的运动估计和时间一致性。此外,采用课程学习策略,从高质量但稀疏的LiDAR深度逐步过渡到低质量但密集的立体深度,以提高模型的鲁棒性和泛化能力。同时,引入SAM的语义先验,增强体素级别的语义学习。
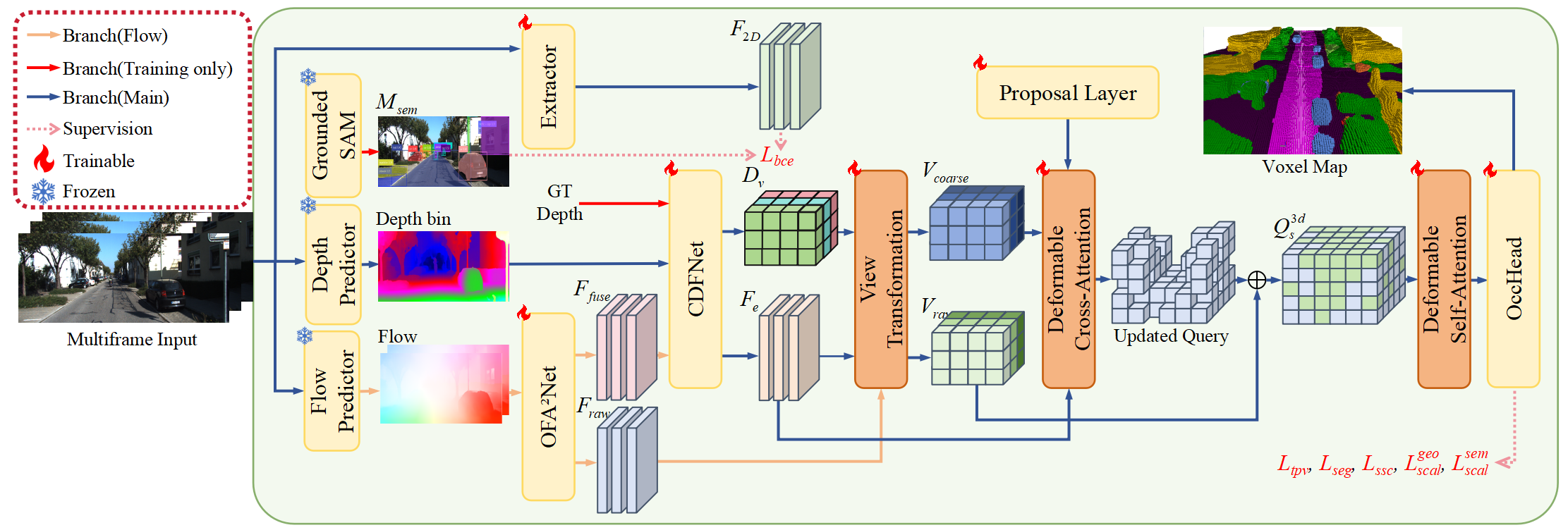
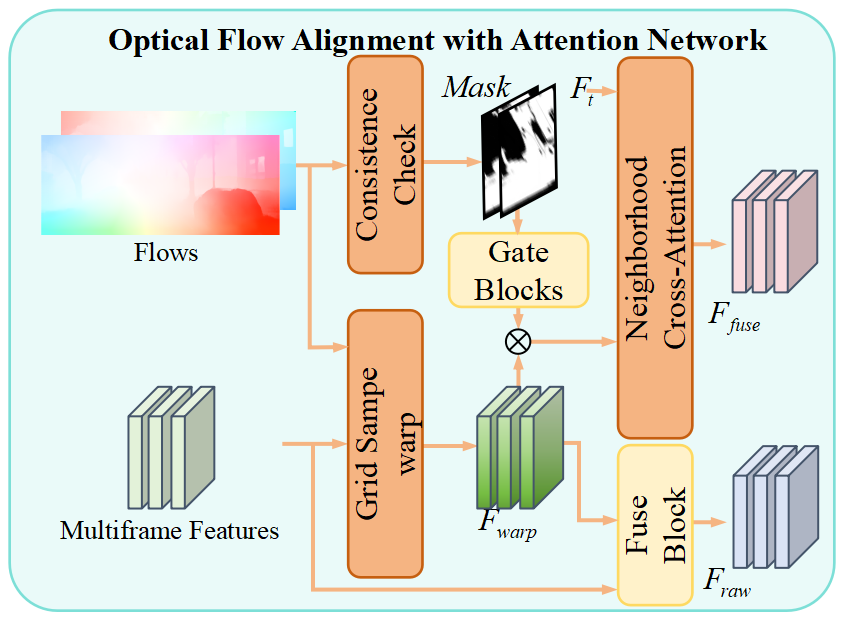
技术框架:CurriFlow框架包含以下主要模块:1) 特征提取模块:提取图像的分割、视觉和深度特征。2) 光流对齐模块:利用预训练的光流模型,将不同帧的特征对齐到同一坐标系下。3) 多层次融合模块:融合对齐后的分割、视觉和深度特征,生成体素级别的特征表示。4) 语义占据预测模块:基于体素特征预测每个体素的语义类别和占据状态。5) 课程学习模块:在训练过程中,逐步增加立体深度的权重,减少LiDAR深度的权重。
关键创新:CurriFlow的关键创新在于:1) 提出了一种基于光流的时间对齐方法,能够有效地处理场景中的物体运动。2) 引入了课程学习策略,能够从稀疏到密集地利用深度信息,提高模型的鲁棒性。3) 利用SAM的语义先验,增强了体素级别的语义学习和空间一致性。
关键设计:在光流对齐模块中,使用了预训练的RAFT模型来估计光流。在课程学习模块中,使用了一个sigmoid函数来控制LiDAR深度和立体深度的权重。损失函数包括语义交叉熵损失、占据交叉熵损失和光流一致性损失。
🖼️ 关键图片

📊 实验亮点
CurriFlow在SemanticKITTI数据集上取得了显著的性能提升,平均IoU达到了16.9%,超过了现有的state-of-the-art方法。消融实验表明,光流对齐、课程学习和SAM语义先验都对性能提升做出了贡献。尤其是在处理动态物体和遮挡区域时,CurriFlow表现出了更强的鲁棒性。
🎯 应用场景
CurriFlow在自动驾驶领域具有重要的应用价值,可以用于构建更完整、准确的3D场景表示,从而提高车辆的感知能力和决策能力。此外,该方法还可以应用于机器人导航、虚拟现实等领域,为这些应用提供更可靠的环境理解能力。未来,可以探索将CurriFlow扩展到更复杂的场景和任务中,例如多传感器融合、动态场景理解等。
📄 摘要(原文)
Semantic Scene Completion (SSC) aims to infer complete 3D geometry and semantics from monocular images, serving as a crucial capability for camera-based perception in autonomous driving. However, existing SSC methods relying on temporal stacking or depth projection often lack explicit motion reasoning and struggle with occlusions and noisy depth supervision. We propose CurriFlow, a novel semantic occupancy prediction framework that integrates optical flow-based temporal alignment with curriculum-guided depth fusion. CurriFlow employs a multi-level fusion strategy to align segmentation, visual, and depth features across frames using pre-trained optical flow, thereby improving temporal consistency and dynamic object understanding. To enhance geometric robustness, a curriculum learning mechanism progressively transitions from sparse yet accurate LiDAR depth to dense but noisy stereo depth during training, ensuring stable optimization and seamless adaptation to real-world deployment. Furthermore, semantic priors from the Segment Anything Model (SAM) provide category-agnostic supervision, strengthening voxel-level semantic learning and spatial consistency. Experiments on the SemanticKITTI benchmark demonstrate that CurriFlow achieves state-of-the-art performance with a mean IoU of 16.9, validating the effectiveness of our motion-guided and curriculum-aware design for camera-based 3D semantic scene completion.