Dual Learning with Dynamic Knowledge Distillation and Soft Alignment for Partially Relevant Video Retrieval
作者: Jianfeng Dong, Lei Huang, Daizong Liu, Xianke Chen, Xun Yang, Changting Lin, Xun Wang, Meng Wang
分类: cs.CV
发布日期: 2025-10-14
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于动态知识蒸馏和软对齐的双重学习框架,用于部分相关视频检索。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 部分相关视频检索 知识蒸馏 双重学习 动态软目标 视觉-语言模型 长视频理解
📋 核心要点
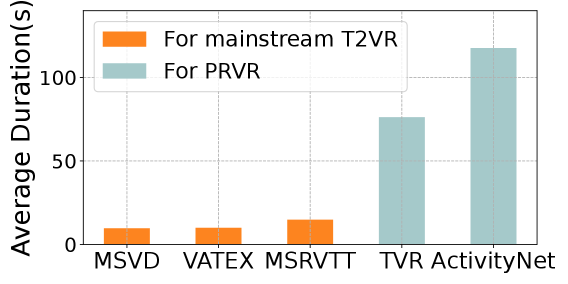
- 现有文本到视频检索工作假设视频已预先裁剪,仅包含与文本相关的内容,这与实际应用中未裁剪长视频的复杂背景不符。
- 论文提出双重学习框架DL-DKD++,通过动态知识蒸馏将大型预训练模型的知识迁移到轻量级学生网络,解决领域差异。
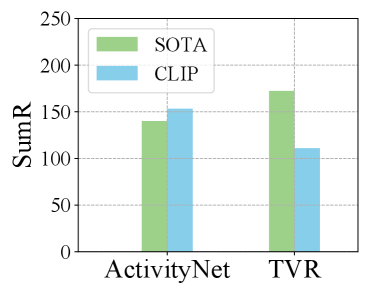
- 实验结果表明,该模型在TVR、ActivityNet和Charades-STA数据集上取得了state-of-the-art的性能,验证了方法的有效性。
📝 摘要(中文)
本文针对更具挑战性的部分相关视频检索(PRVR)任务,即检索与给定查询部分相关的未裁剪长视频,提出了一种新颖的框架。该框架从强大的大规模视觉-语言预训练模型中提取泛化知识,并将其转移到轻量级的、特定于任务的PRVR网络。具体而言,我们引入了一个具有动态知识蒸馏(DL-DKD++)的双重学习框架,其中大型教师模型为紧凑的双分支学生网络提供监督。学生模型包括两个分支:一个继承分支,吸收来自教师的可转移知识;一个探索分支,从PRVR数据集中学习特定于任务的信息,以解决领域差距。为了进一步增强学习,我们结合了一种动态软目标构建机制。通过用在训练期间演变的自适应软目标替换刚性的硬目标监督,我们的方法使模型能够更好地捕获视频和查询之间细粒度的部分相关性。实验结果表明,我们提出的模型在TVR、ActivityNet和Charades-STA数据集上实现了最先进的PRVR性能。
🔬 方法详解
问题定义:论文旨在解决部分相关视频检索(PRVR)问题,即在未裁剪的长视频中检索与给定文本查询部分相关的片段。现有方法通常假设视频已经过预处理,只包含与查询相关的片段,这与实际场景不符,导致性能下降。现有方法无法有效处理长视频中存在的噪声和无关信息,以及视频内容与文本查询之间的细粒度对应关系。
核心思路:论文的核心思路是利用知识蒸馏,将大规模预训练视觉-语言模型(教师模型)的知识迁移到轻量级的、特定于PRVR任务的学生模型。同时,引入双分支结构,一个分支负责继承教师模型的知识,另一个分支负责探索PRVR数据集中的特定信息,以弥补领域差距。此外,采用动态软目标构建机制,利用软标签代替硬标签,从而更好地捕捉视频和查询之间的细粒度相关性。
技术框架:整体框架包含一个教师模型和一个双分支学生模型。教师模型通常是一个大规模的预训练视觉-语言模型,例如CLIP。学生模型包含一个继承分支和一个探索分支。继承分支通过知识蒸馏学习教师模型的知识,探索分支则直接从PRVR数据集中学习。动态知识蒸馏模块负责生成软目标,并指导学生模型的训练。整个训练过程采用双重学习机制,即学生模型同时学习继承和探索分支的知识,并相互促进。
关键创新:论文的关键创新在于以下几个方面:1) 提出了双重学习框架,有效结合了知识蒸馏和特定任务学习;2) 引入了动态知识蒸馏机制,通过动态生成的软目标更好地捕捉细粒度的相关性;3) 设计了双分支学生模型,分别负责知识继承和领域探索,从而更好地适应PRVR任务。
关键设计:动态软目标的构建方式是关键设计之一。具体而言,软目标是通过教师模型的预测结果生成的,并随着训练的进行而动态调整。损失函数包括知识蒸馏损失、对比学习损失和交叉熵损失等,用于指导学生模型的训练。网络结构方面,继承分支和探索分支可以采用不同的网络结构,例如Transformer或CNN。具体的参数设置需要根据数据集和任务进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,提出的DL-DKD++模型在TVR、ActivityNet和Charades-STA三个PRVR数据集上均取得了state-of-the-art的性能。例如,在TVR数据集上,相比于之前的最佳方法,R@1指标提升了超过5%。消融实验也验证了动态知识蒸馏和双分支结构的有效性。
🎯 应用场景
该研究成果可应用于视频搜索、智能监控、视频内容分析等领域。例如,用户可以通过文本查询快速找到包含特定事件或场景的长视频片段。在智能监控中,可以根据文本描述自动检索可疑行为的视频片段。该研究有助于提升视频理解和检索的准确性和效率,具有重要的实际应用价值。
📄 摘要(原文)
Almost all previous text-to-video retrieval works ideally assume that videos are pre-trimmed with short durations containing solely text-related content. However, in practice, videos are typically untrimmed in long durations with much more complicated background content. Therefore, in this paper, we focus on the more practical yet challenging task of Partially Relevant Video Retrieval (PRVR), which aims to retrieve partially relevant untrimmed videos with the given query. To tackle this task, we propose a novel framework that distills generalization knowledge from a powerful large-scale vision-language pre-trained model and transfers it to a lightweight, task-specific PRVR network. Specifically, we introduce a Dual Learning framework with Dynamic Knowledge Distillation (DL-DKD++), where a large teacher model provides supervision to a compact dual-branch student network. The student model comprises two branches: an inheritance branch that absorbs transferable knowledge from the teacher, and an exploration branch that learns task-specific information from the PRVR dataset to address domain gaps. To further enhance learning, we incorporate a dynamic soft-target construction mechanism. By replacing rigid hard-target supervision with adaptive soft targets that evolve during training, our method enables the model to better capture the fine-grained, partial relevance between videos and queries. Experiment results demonstrate that our proposed model achieves state-of-the-art performance on TVR, ActivityNet, and Charades-STA datasets for PRVR. The code is available at https://github.com/HuiGuanLab/DL-DKD.