SpineBench: Benchmarking Multimodal LLMs for Spinal Pathology Analysis
作者: Chenghanyu Zhang, Zekun Li, Peipei Li, Xing Cui, Shuhan Xia, Weixiang Yan, Yiqiao Zhang, Qianyu Zhuang
分类: cs.CV
发布日期: 2025-10-14
备注: Proceedings of the 33rd ACM International Conference on Multimedia,ACMMM 2025 Dataset Track
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
SpineBench:用于脊柱病理分析的多模态LLM基准测试
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 大型语言模型 脊柱病理分析 视觉问答 医学图像分析
📋 核心要点
- 现有医学基准测试未能充分评估MLLM在脊柱等依赖视觉信息的细分领域的性能。
- SpineBench通过构建包含大量脊柱图像和问题答案对的VQA基准,实现对MLLM的精细评估。
- 实验结果表明,现有MLLM在脊柱任务中表现不佳,为未来改进提供了方向。
📝 摘要(中文)
随着多模态大型语言模型(MLLM)日益融入医学领域,全面评估其在各个医学领域的性能至关重要。然而,现有的基准测试主要评估一般的医学任务,未能充分捕捉到像脊柱这样严重依赖视觉输入的细微领域的性能。为了解决这个问题,我们推出了SpineBench,这是一个全面的视觉问答(VQA)基准,专为脊柱领域MLLM的精细分析和评估而设计。SpineBench包含来自40,263张脊柱图像的64,878个QA对,通过两项关键的临床任务(脊柱疾病诊断和脊柱病灶定位)涵盖11种脊柱疾病,均采用多项选择题形式。SpineBench通过整合和标准化来自开源脊柱疾病数据集的图像-标签对构建,并为每个VQA对采样具有视觉相似性的困难负样本选项(相似但非同一种疾病),模拟真实的挑战性场景。我们评估了SpineBench上的12个领先的MLLM。结果表明,这些模型在脊柱任务中表现不佳,突出了当前MLLM在脊柱领域的局限性,并指导未来脊柱医学应用的改进。SpineBench可在https://zhangchenghanyu.github.io/SpineBench.github.io/公开获取。
🔬 方法详解
问题定义:论文旨在解决多模态大型语言模型(MLLM)在脊柱病理分析领域缺乏有效评估的问题。现有医学基准测试通常侧重于通用医学任务,无法充分评估MLLM在需要精细视觉理解的脊柱疾病诊断和病灶定位方面的能力。因此,需要一个专门针对脊柱病理的基准测试,以揭示现有MLLM的局限性,并指导未来的模型改进。
核心思路:论文的核心思路是构建一个高质量的脊柱病理视觉问答(VQA)基准测试数据集SpineBench。该数据集包含大量脊柱图像和相应的问答对,涵盖多种脊柱疾病和临床任务。通过在该基准上评估现有MLLM的性能,可以客观地了解它们在脊柱病理分析方面的能力,并识别其不足之处。同时,通过构建具有视觉相似性的困难负样本,模拟真实临床场景中的挑战,从而更全面地评估模型的鲁棒性。
技术框架:SpineBench的构建流程主要包括以下几个阶段:1) 数据收集与整合:从公开的脊柱疾病数据集中收集图像和标签信息。2) 数据标准化:对收集到的数据进行标准化处理,确保数据格式和标注的一致性。3) 问题生成:根据图像和标签信息,生成相应的视觉问答对,包括疾病诊断和病灶定位等任务。4) 困难负样本采样:为每个问题生成具有视觉相似性的困难负样本选项,增加测试的难度。5) 数据集划分:将数据集划分为训练集、验证集和测试集。
关键创新:SpineBench的关键创新在于其专注于脊柱病理分析这一特定领域,并构建了包含大量高质量VQA对的基准测试数据集。此外,通过引入具有视觉相似性的困难负样本,模拟了真实临床场景中的挑战,从而更全面地评估MLLM的性能。与现有通用医学基准测试相比,SpineBench能够更准确地反映MLLM在脊柱病理分析方面的能力。
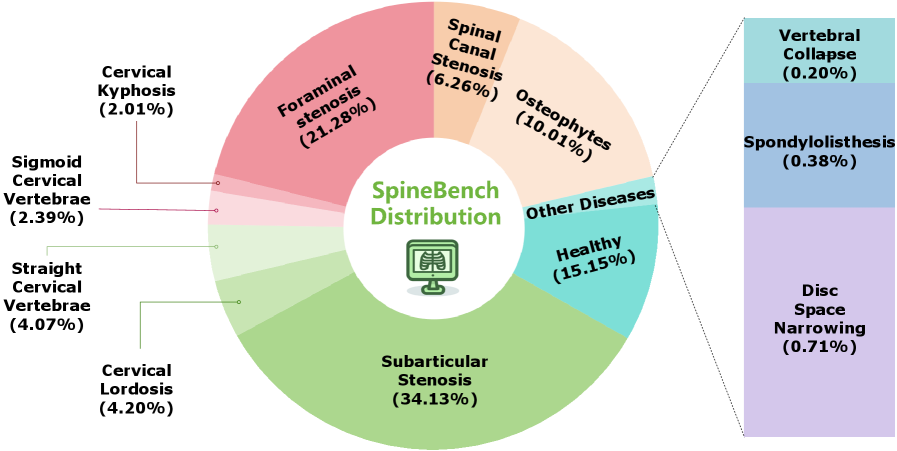
关键设计:SpineBench包含64,878个QA对,来自40,263张脊柱图像,涵盖11种脊柱疾病。问题类型包括脊柱疾病诊断和脊柱病灶定位,均采用多项选择题形式。困难负样本的生成基于视觉相似性,即选择与正确答案在视觉上相似但实际不同的疾病作为错误选项。数据集的划分比例未知。
🖼️ 关键图片


📊 实验亮点
在SpineBench上对12个领先的MLLM进行了评估,结果表明这些模型在脊柱任务中表现不佳,这突显了当前MLLM在脊柱领域的局限性。具体的性能数据和对比基线未在摘要中给出,但该结果表明,现有MLLM在处理复杂的脊柱图像和相关临床问题时仍存在很大的改进空间。
🎯 应用场景
SpineBench的潜在应用领域包括辅助脊柱疾病诊断、病灶定位和治疗方案选择。通过利用MLLM在SpineBench上进行训练和评估,可以开发出更准确、更可靠的脊柱病理分析工具,从而提高临床诊断效率和治疗效果。此外,SpineBench可以作为研究平台,促进MLLM在医学图像分析领域的进一步发展。
📄 摘要(原文)
With the increasing integration of Multimodal Large Language Models (MLLMs) into the medical field, comprehensive evaluation of their performance in various medical domains becomes critical. However, existing benchmarks primarily assess general medical tasks, inadequately capturing performance in nuanced areas like the spine, which relies heavily on visual input. To address this, we introduce SpineBench, a comprehensive Visual Question Answering (VQA) benchmark designed for fine-grained analysis and evaluation of MLLMs in the spinal domain. SpineBench comprises 64,878 QA pairs from 40,263 spine images, covering 11 spinal diseases through two critical clinical tasks: spinal disease diagnosis and spinal lesion localization, both in multiple-choice format. SpineBench is built by integrating and standardizing image-label pairs from open-source spinal disease datasets, and samples challenging hard negative options for each VQA pair based on visual similarity (similar but not the same disease), simulating real-world challenging scenarios. We evaluate 12 leading MLLMs on SpineBench. The results reveal that these models exhibit poor performance in spinal tasks, highlighting limitations of current MLLM in the spine domain and guiding future improvements in spinal medicine applications. SpineBench is publicly available at https://zhangchenghanyu.github.io/SpineBench.github.io/.