UniGS: Unified Geometry-Aware Gaussian Splatting for Multimodal Rendering
作者: Yusen Xie, Zhenmin Huang, Jianhao Jiao, Dimitrios Kanoulas, Jun Ma
分类: cs.CV, cs.RO
发布日期: 2025-10-14 (更新: 2025-11-13)
💡 一句话要点
提出UniGS以解决高保真多模态3D重建问题
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态渲染 3D重建 高斯点云 光栅化技术 几何一致性 深度优化 计算机视觉
📋 核心要点
- 现有的3D重建方法在多模态渲染中面临精度和一致性不足的挑战,难以同时生成高质量的RGB图像和深度信息。
- UniGS通过引入可微分的光线-椭球体交点技术,优化了深度渲染过程,并实现了多模态信息的统一处理。
- 实验结果显示,UniGS在重建精度上超越了现有方法,展现出在多模态渲染中的优越性能和高效性。
📝 摘要(中文)
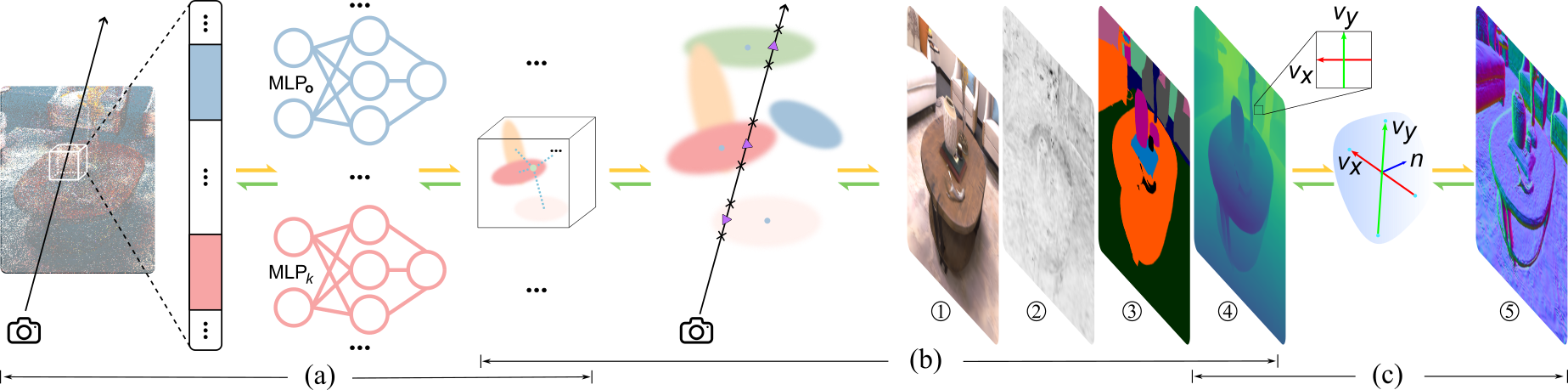
本文提出了UniGS,一个统一的地图表示和可微分框架,旨在基于3D高斯点云实现高保真的多模态3D重建。该框架集成了一个CUDA加速的光栅化管道,能够同时渲染逼真的RGB图像、几何准确的深度图、一致的表面法线和语义逻辑。我们重新设计了光栅化过程,通过可微分的光线-椭球体交点来渲染深度,从而有效优化旋转和缩放属性,并确保重建3D场景的几何一致性。实验结果表明,该方法在各个模态上均实现了最先进的重建精度,验证了我们几何感知范式的有效性。
🔬 方法详解
问题定义:本文旨在解决现有多模态3D重建方法在渲染精度和几何一致性方面的不足,尤其是在同时生成RGB图像和深度图时的挑战。
核心思路:UniGS的核心思路是通过可微分的光线-椭球体交点技术来替代传统的高斯中心渲染深度,从而实现更有效的优化和一致性。
技术框架:该框架包括一个CUDA加速的光栅化管道,能够同时处理RGB图像、深度图、表面法线和语义信息,确保各模态间的几何一致性。
关键创新:最重要的创新在于引入了可微分的光线-椭球体交点技术,使得深度渲染过程的优化更加高效,并且能够通过解析深度梯度来优化旋转和缩放属性。
关键设计:在设计中,采用了可学习的属性以实现对贡献较小的高斯的可微分剪枝,显著提高了计算和存储效率,同时确保了重建的高精度。
🖼️ 关键图片


📊 实验亮点
实验结果表明,UniGS在所有模态上均实现了最先进的重建精度,具体性能数据展示了相较于基线方法的显著提升,尤其在深度图和表面法线的一致性上表现突出,验证了其几何感知范式的有效性。
🎯 应用场景
该研究在计算机视觉、虚拟现实和增强现实等领域具有广泛的应用潜力。通过实现高保真的多模态3D重建,UniGS可用于创建更真实的虚拟环境和物体模型,提升用户体验。此外,该技术在自动驾驶、机器人导航等领域也具有重要的实际价值。
📄 摘要(原文)
In this paper, we propose UniGS, a unified map representation and differentiable framework for high-fidelity multimodal 3D reconstruction based on 3D Gaussian Splatting. Our framework integrates a CUDA-accelerated rasterization pipeline capable of rendering photo-realistic RGB images, geometrically accurate depth maps, consistent surface normals, and semantic logits simultaneously. We redesign the rasterization to render depth via differentiable ray-ellipsoid intersection rather than using Gaussian centers, enabling effective optimization of rotation and scale attribute through analytic depth gradients. Furthermore, we derive the analytic gradient formulation for surface normal rendering, ensuring geometric consistency among reconstructed 3D scenes. To improve computational and storage efficiency, we introduce a learnable attribute that enables differentiable pruning of Gaussians with minimal contribution during training. Quantitative and qualitative experiments demonstrate state-of-the-art reconstruction accuracy across all modalities, validating the efficacy of our geometry-aware paradigm. Source code and multimodal viewer will be available on GitHub.