State Space Prompting via Gathering and Spreading Spatio-Temporal Information for Video Understanding
作者: Jiahuan Zhou, Kai Zhu, Zhenyu Cui, Zichen Liu, Xu Zou, Gang Hua
分类: cs.CV
发布日期: 2025-10-14
💡 一句话要点
提出状态空间提示(SSP)方法,通过时空信息聚合与传播提升视频理解性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation)
关键词: 视频理解 状态空间模型 提示学习 时空信息 帧内聚集 帧间传播 视频分类 深度学习
📋 核心要点
- 现有基于状态空间模型的视频分类方法难以有效捕获视频中的时空上下文信息。
- 提出状态空间提示(SSP)方法,通过帧内聚集和帧间传播模块聚合和传播关键时空信息。
- 实验表明,SSP在四个视频数据集上显著优于现有方法,平均提升2.76%,并减少了微调参数。
📝 摘要(中文)
本文提出了一种用于视频理解的状态空间提示(SSP)方法。该方法旨在解决现有基于状态空间模型的视频分类方法中,视觉提示token难以有效捕获视频中的时空上下文信息的问题。SSP结合了帧内聚集(IFG)和帧间传播(IFS)模块,分别用于聚集帧内空间关键信息和传播帧间判别性时空信息。通过自适应地平衡和压缩帧内和帧间的关键时空信息,SSP能够以互补的方式有效传播视频中的判别性信息。在四个视频基准数据集上的大量实验表明,SSP在减少微调参数开销的同时,显著优于现有的SOTA方法,平均提升2.76%。
🔬 方法详解
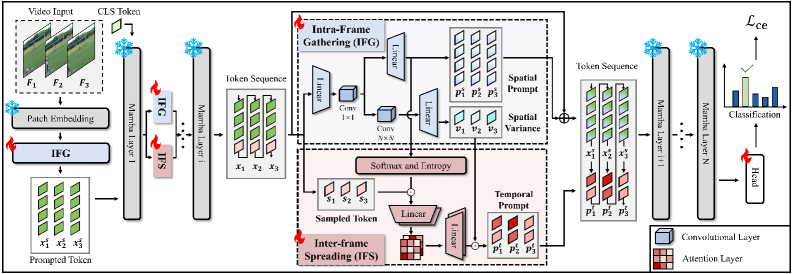
问题定义:现有的基于预训练状态空间模型的视频分类方法,在应用提示学习进行下游任务适配时,顺序压缩的视觉提示token无法有效捕获视频中的空间和时间上下文信息。这限制了帧内空间信息和帧间时间信息的有效传播,以及判别性信息的提取。
核心思路:论文的核心思路是通过设计帧内聚集(Intra-Frame Gathering, IFG)和帧间传播(Inter-Frame Spreading, IFS)模块,显式地建模和利用视频中的时空上下文信息。IFG负责在每一帧内聚合关键的空间信息,IFS负责在不同帧之间传播判别性的时空信息。
技术框架:SSP方法主要包含两个核心模块:IFG和IFS。IFG模块首先对每一帧图像进行处理,提取空间关键信息并进行聚合。然后,IFS模块利用帧间关系,将判别性的时空信息在不同帧之间进行传播。这两个模块协同工作,使得模型能够更好地理解视频内容。整个框架基于预训练的状态空间模型,通过提示学习的方式进行下游任务适配。
关键创新:关键创新在于同时考虑了帧内和帧间的时空信息,并设计了专门的模块来处理这些信息。IFG和IFS模块的结合,使得模型能够更全面地理解视频内容,从而提升视频理解的性能。与现有方法相比,SSP方法能够更有效地利用视频中的时空上下文信息。
关键设计:IFG模块的具体实现方式未知,但其目标是聚合帧内的空间关键信息。IFS模块的具体实现方式也未知,但其目标是传播帧间的判别性时空信息。论文强调了自适应地平衡和压缩帧内和帧间的关键时空信息,这可能涉及到一些自注意力机制或者门控机制的设计。损失函数的设计可能也需要考虑如何更好地利用时空信息,例如可以使用对比学习或者时序一致性损失。
🖼️ 关键图片
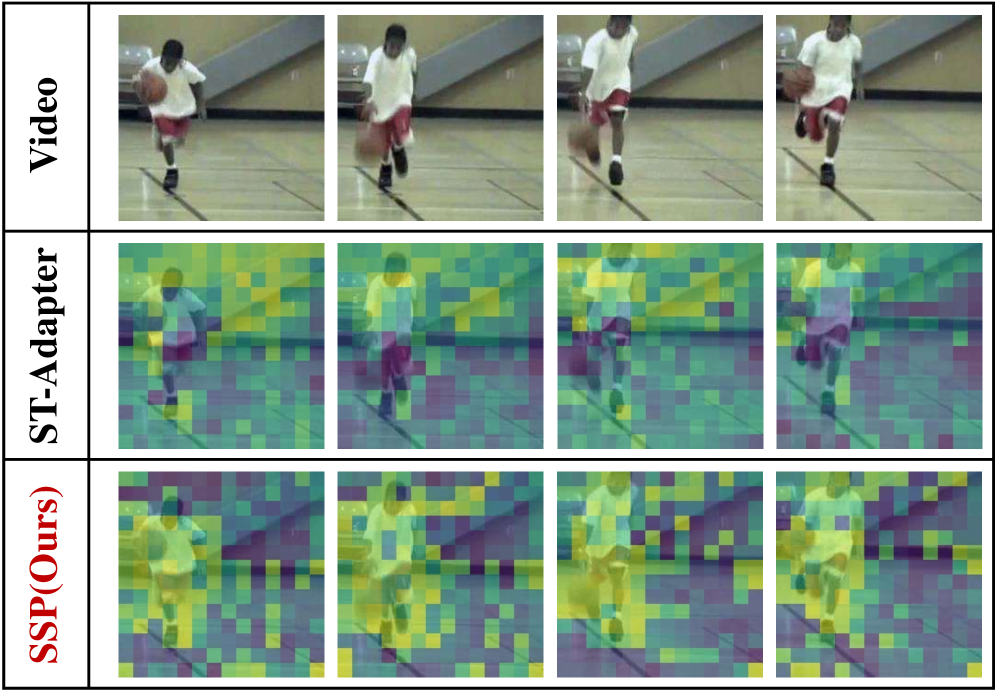

📊 实验亮点
实验结果表明,提出的SSP方法在四个视频基准数据集上显著优于现有的SOTA方法,平均提升2.76%。这一提升是在减少微调参数开销的前提下实现的,表明SSP方法具有更高的效率和更好的泛化能力。具体的性能数据和对比基线在论文中进行了详细的展示。
🎯 应用场景
该研究成果可应用于多种视频理解任务,如视频分类、动作识别、视频检索等。通过提升视频理解的准确性和效率,该方法在智能监控、自动驾驶、视频内容分析等领域具有潜在的应用价值。未来,该方法可以进一步扩展到处理更复杂的视频场景,例如包含多目标、复杂动作和长时间跨度的视频。
📄 摘要(原文)
Recently, pre-trained state space models have shown great potential for video classification, which sequentially compresses visual tokens in videos with linear complexity, thereby improving the processing efficiency of video data while maintaining high performance. To apply powerful pre-trained models to downstream tasks, prompt learning is proposed to achieve efficient downstream task adaptation with only a small number of fine-tuned parameters. However, the sequentially compressed visual prompt tokens fail to capture the spatial and temporal contextual information in the video, thus limiting the effective propagation of spatial information within a video frame and temporal information between frames in the state compression model and the extraction of discriminative information. To tackle the above issue, we proposed a State Space Prompting (SSP) method for video understanding, which combines intra-frame and inter-frame prompts to aggregate and propagate key spatiotemporal information in the video. Specifically, an Intra-Frame Gathering (IFG) module is designed to aggregate spatial key information within each frame. Besides, an Inter-Frame Spreading (IFS) module is designed to spread discriminative spatio-temporal information across different frames. By adaptively balancing and compressing key spatio-temporal information within and between frames, our SSP effectively propagates discriminative information in videos in a complementary manner. Extensive experiments on four video benchmark datasets verify that our SSP significantly outperforms existing SOTA methods by 2.76% on average while reducing the overhead of fine-tuning parameters.